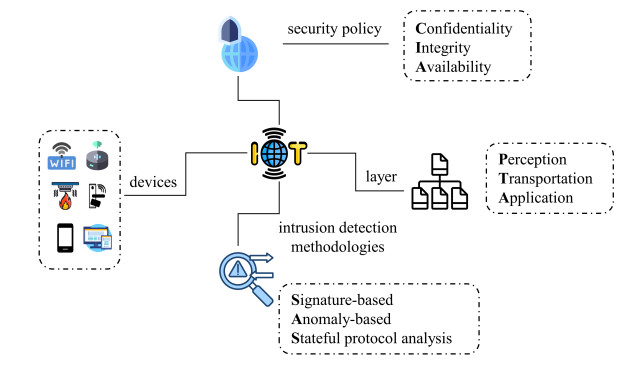
With the widespread application of smart devices, the security of internet of things (IoT) systems faces entirely new challenges. The IoT data stream operates in a non-stationary, dynamic environment, making it prone to concept drift. This paper focused on addressing the issue of concept drift in data streams, with a key emphasis on introducing an innovative drift detection method-ensemble multiple non-parametric concept localization detectors, abbreviated as EMNCD. EMNCD employs an ensemble of non-parametric statistical methods, including the Kolmogorov-Smirnov, Wilcoxon rank sum and Mann-Kendall tests. By comparing sample distributions within a sliding window, EMNCD accurately detects concept drift, achieving precise localization of drift points, and enhancing overall detection reliability. Experimental results demonstrated the superior performance of EMNCD compared to classical methods on artificial datasets. Simultaneously, to enhance the robustness of data stream processing, we presented an online anomaly detection method based on the isolation forest (iForest). Additionally, we proposedwhale optimization algorithm (WOA)-extreme gradient boosting (XGBoost), a drift adaptation model employing XGBoost as a base classifier. This model dynamically updates using drift points detected by EMNCD and fine-tunes parameters through the WOA. Real-world applications on the edge-industrial IoTset (IIoTset) intrusion dataset explore the impact of concept drift on intrusion detection, where IIoT is a subclass of IoT. In summary, this paper focused on EMNCD, introducing innovative approaches for drift detection, anomaly detection, and drift adaptation. The research provided practical and viable solutions to address concept drift in data streams, enhancing security in IoT systems.
Citation: Renjie Chu, Peiyuan Jin, Hanli Qiao, Quanxi Feng. Intrusion detection in the IoT data streams using concept drift localization[J]. AIMS Mathematics, 2024, 9(1): 1535-1561. doi: 10.3934/math.2024076
With the widespread application of smart devices, the security of internet of things (IoT) systems faces entirely new challenges. The IoT data stream operates in a non-stationary, dynamic environment, making it prone to concept drift. This paper focused on addressing the issue of concept drift in data streams, with a key emphasis on introducing an innovative drift detection method-ensemble multiple non-parametric concept localization detectors, abbreviated as EMNCD. EMNCD employs an ensemble of non-parametric statistical methods, including the Kolmogorov-Smirnov, Wilcoxon rank sum and Mann-Kendall tests. By comparing sample distributions within a sliding window, EMNCD accurately detects concept drift, achieving precise localization of drift points, and enhancing overall detection reliability. Experimental results demonstrated the superior performance of EMNCD compared to classical methods on artificial datasets. Simultaneously, to enhance the robustness of data stream processing, we presented an online anomaly detection method based on the isolation forest (iForest). Additionally, we proposedwhale optimization algorithm (WOA)-extreme gradient boosting (XGBoost), a drift adaptation model employing XGBoost as a base classifier. This model dynamically updates using drift points detected by EMNCD and fine-tunes parameters through the WOA. Real-world applications on the edge-industrial IoTset (IIoTset) intrusion dataset explore the impact of concept drift on intrusion detection, where IIoT is a subclass of IoT. In summary, this paper focused on EMNCD, introducing innovative approaches for drift detection, anomaly detection, and drift adaptation. The research provided practical and viable solutions to address concept drift in data streams, enhancing security in IoT systems.

| [1] |
M. A. Hoque, C. Davidson, Design and implementation of an IoT-based smart home security system, Int. J. Networked Distrib. Comput., 7 (2019), 85–92. https://doi.org/10.2991/ijndc.k.190326.004 doi: 10.2991/ijndc.k.190326.004

|
| [2] |
Z. Chen, C. Sivaparthipan, B. Muthu, IoT based smart and intelligent smart city energy optimization, Sustainable Energy Technol. Assess., 49 (2022), 101724. https://doi.org/10.1016/j.seta.2021.101724 doi: 10.1016/j.seta.2021.101724
|
| [3] |
D. Dobrilović, M. M, D. Malić, Learning platform for smart city application development, Interdiscip. Descr. Complex Syst., 17 (2019), 430–437. https://doi.org/10.7906/indecs.17.3.1 doi: 10.7906/indecs.17.3.1
|
| [4] |
R. W. Liu, Y. Guo, Y. Lu, K. T. Chui, B. B. Gupta, Deep network-enabled haze visibility enhancement for visual IoT-driven intelligent transportation systems, IEEE Trans. Ind. Inf., 19 (2022), 1581–1591. https://doi.org/10.1109/TII.2022.3170594 doi: 10.1109/TII.2022.3170594
|
| [5] |
X. Zhan, W. Wu, L. Shen, W. Liao, Z. Zhao, J. Xia, Industrial internet of things and unsupervised deep learning enabled real-time occupational safety monitoring in cold storage warehouse, Safety Sci., 152 (2022), 105766. https://doi.org/10.1016/j.ssci.2022.105766 doi: 10.1016/j.ssci.2022.105766
|
| [6] |
H. Gururaj, B. Swathi, R. Trupti, U. R. Darshan, A. Rajendra, K. Paramesha, Analysis of preventive measures against ddos attacks in smart grid, J. Inst. Eng. India, 104 (2023), 297–303. https://doi.org/10.1007/s40031-022-00844-1 doi: 10.1007/s40031-022-00844-1
|
| [7] |
A. K. Yadav, M. Misra, P. K. Pandey, M. Liyanage, An eap-based mutual authentication protocol for wlan-connected IoT devices, IEEE Trans. Ind. Inf., 19 (2022), 1343–1355. https://doi.org/10.1109/TII.2022.3194956 doi: 10.1109/TII.2022.3194956
|
| [8] |
R. Vinayakumar, M. Alazab, S. Srinivasan, Q. V. Pham, S. K. Padannayil, K. Simran, A visualized botnet detection system based deep learning for the internet of things networks of smart cities, IEEE Trans. Ind. Appl., 56 (2020), 4436–4456. https://doi.org/10.1109/TIA.2020.2971952 doi: 10.1109/TIA.2020.2971952
|
| [9] |
E. Benkhelifa, T. Welsh, W. Hamouda, A critical review of practices and challenges in intrusion detection systems for IoT: toward universal and resilient systems, IEEE Commun. Surv. Tut., 20 (2018), 3496–3509. https://doi.org/10.1109/COMST.2018.2844742 doi: 10.1109/COMST.2018.2844742
|
| [10] |
E. Bout, V. Loscri, A. Gallais, How machine learning changes the nature of cyberattacks on IoT networks: a survey, IEEE Commun. Surv. Tut., 24 (2021), 248–279. https://doi.org/10.1109/COMST.2021.3127267 doi: 10.1109/COMST.2021.3127267
|
| [11] |
A. Jamalipour, S. Murali, A taxonomy of machine-learning-based intrusion detection systems for the internet of things: a survey, IEEE Internet Things J., 9 (2021), 9444–9466. https://doi.org/10.1109/JIOT.2021.3126811 doi: 10.1109/JIOT.2021.3126811
|
| [12] |
N. W. Khan, M. S. Alshehri, M. A Khan, S. Almakdi, N. Moradpoor, A. Alazeb, et al., A hybrid deep learning-based intrusion detection system for IoT networks, Math. Biosci. Eng., 20 (2023), 13491–13520. https://doi.org/10.3934/mbe.2023602 doi: 10.3934/mbe.2023602
|
| [13] |
S. Ullah, J. Ahmad, M. A. Khan, M. S. Alshehri, W. Boulila, A. Koubaa, et al., TNN-IDS: transformer neural network-based intrusion detection system for MQTT-enabled IoT networks, Comput. Networks, 237 (2023), 110072. https://doi.org/10.1016/j.comnet.2023.110072 doi: 10.1016/j.comnet.2023.110072
|
| [14] |
S. Ullah, J. Ahmad, M. A. Khan, E. H. Alkhammash, M. Hadjouni, Y. Y. Ghadi, et al., A new intrusion detection system for the internet of things via deep convolutional neural network and feature engineering, Sensors, 22 (2022), 3607. https://doi.org/10.3390/s22103607 doi: 10.3390/s22103607
|
| [15] |
L. Cohen, G. Avrahami-Bakish, M. Last, A. Kandel, O. Kipersztok, Real-time data mining of non-stationary data streams from sensor networks, Inf. Fusion, 9 (2008), 344–353. https://doi.org/10.1016/j.inffus.2005.05.005 doi: 10.1016/j.inffus.2005.05.005
|
| [16] |
J. Lu, A. Liu, F. Dong, F. Gu, J. Gama, G. Zhang, Learning under concept drift: a review, IEEE Trans. Knowl. Data Eng., 31 (2018), 2346–2363. https://doi.org/10.1109/TKDE.2018.2876857 doi: 10.1109/TKDE.2018.2876857
|
| [17] |
J. Gama, P. Medas, G. Castillo, P. Rodrigues, Learning with drift detection, Brazilian Symposium on Artificial Intelligence, 2004,286–295. https://doi.org/10.1007/978-3-540-28645-5_29 doi: 10.1007/978-3-540-28645-5_29
|
| [18] |
A. Liu, J. Lu, F. Liu, G. Zhang, Accumulating regional density dissimilarity for concept drift detection in data streams, Pattern Recognit., 76 (2018), 256–272. https://doi.org/10.1016/j.patcog.2017.11.009 doi: 10.1016/j.patcog.2017.11.009
|
| [19] |
L. Du, Q. Song, X. Jia, Detecting concept drift: an information entropy based method using an adaptive sliding window, Intell. Data Anal., 18 (2014), 337–364. https://doi.org/10.3233/IDA-140645 doi: 10.3233/IDA-140645
|
| [20] |
H. Qiao, B. Novikov, J. O. Blech, Concept drift analysis by dynamic residual projection for effectively detecting botnet cyber-attacks in IoT scenarios, IEEE Trans. Ind. Inf., 18 (2021), 3692–3701. https://doi.org/10.1109/TII.2021.3108464 doi: 10.1109/TII.2021.3108464
|
| [21] |
L. Yang, A. Shami, A lightweight concept drift detection and adaptation framework for IoT data streams, IEEE Internet Things Mag., 4 (2021), 96–101. https://doi.org/10.1109/IOTM.0001.2100012 doi: 10.1109/IOTM.0001.2100012
|
| [22] |
W. Lalouani, M. Younis, Robust distributed intrusion detection system for edge of things, 2021 IEEE Global Communications Conference, 2021. https://doi.org/10.1109/GLOBECOM46510.2021.9685361 doi: 10.1109/GLOBECOM46510.2021.9685361
|
| [23] |
M. A. H. Al-Balhawi, G. Cansever, Intursion detection in iot networks using feature selection and svm classificastion, 2022 International Congress on Human-Computer Interaction, Optimization and Robotic Applications, 2022. https://doi.org/10.1109/HORA55278.2022.9799861 doi: 10.1109/HORA55278.2022.9799861
|
| [24] |
M. M. Alani, A. I. Awad, An intelligent two-layer intrusion detection system for the internet of things, IEEE Trans. Ind. Inf., 19 (2022), 683–692. https://doi.org/10.1109/TII.2022.3192035 doi: 10.1109/TII.2022.3192035
|
| [25] |
T. B. Hoang, L. Vu, Q. U. Nguyen, A data sampling and two-stage convolution neural network for IoT devices identification, 2022 RIVF International Conference on Computing and Communication Technologies, 2022,458–463. https://doi.org/10.1109/RIVF55975.2022.10013866 doi: 10.1109/RIVF55975.2022.10013866
|
| [26] |
G. Rathee, C. A. Kerrache, M. Lahby, Trustblksys: a trusted and blockchained cybersecure system for IIoT, IEEE Trans. Ind. Inf., 19 (2022), 1592–1599. https://doi.org/10.1109/TII.2022.3182984 doi: 10.1109/TII.2022.3182984
|
| [27] |
O. A. Wahab, Intrusion detection in the IoT under data and concept drifts: Online deep learning approach, IEEE Internet Things J., 9 (2022), 19706–19716. https://doi.org/10.1109/JIOT.2022.3167005 doi: 10.1109/JIOT.2022.3167005
|
| [28] |
E. Lughofer, E. Weigl, W. Heidl, C. Eitzinger, T. Radauer, Recognizing input space and target concept drifts in data streams with scarcely labeled and unlabelled instances, Inf. Sci., 355 (2016), 127–151. https://doi.org/10.1016/j.ins.2016.03.034 doi: 10.1016/j.ins.2016.03.034
|
| [29] |
C. Alippi, G. Boracchi, M. Roveri, Hierarchical change-detection tests, IEEE Trans. Neural Networks Learn. Syst., 28 (2016), 246–258. https://doi.org/10.1109/TNNLS.2015.2512714 doi: 10.1109/TNNLS.2015.2512714
|
| [30] |
K. Nishida, K. Yamauchi, Detecting concept drift using statistical testing, Proceedings of the 10th International Conference on Discovery Science, 2007,264–269. https://doi.org/10.1007/978-3-540-75488-6_27 doi: 10.1007/978-3-540-75488-6_27
|
| [31] |
R. S. M. de Barros, J. I. G. Hidalgo, D. R. de L. Cabral, Wilcoxon rank sum test drift detector, Neurocomputing, 275 (2018), 1954–1963. https://doi.org/10.1016/j.neucom.2017.10.051 doi: 10.1016/j.neucom.2017.10.051
|
| [32] |
L. Bu, C. Alippi, D. Zhao, A pdf-free change detection test based on density difference estimation, IEEE Trans. Neural Networks Learn. Syst., 29 (2016), 324–334. https://doi.org/10.1109/TNNLS.2016.2619909 doi: 10.1109/TNNLS.2016.2619909
|
| [33] |
D. Liu, Y. Wu, H. Jiang, FP-ELM: an online sequential learning algorithm for dealing with concept drift, Neurocomputing, 207 (2016), 322–334. https://doi.org/10.1016/j.neucom.2016.04.043 doi: 10.1016/j.neucom.2016.04.043
|
| [34] |
Y. Sun, K. Tang, Z. Zhu, X. Yao, Concept drift adaptation by exploiting historical knowledge, IEEE Trans. Neural Networks Learn. Syst., 29 (2018), 4822–4832. https://doi.org/10.1109/TNNLS.2017.2775225 doi: 10.1109/TNNLS.2017.2775225
|
| [35] |
D. S. Dimitrova, V. K. Kaishev, S. Tan, Computing the kolmogorov-smirnov distribution when the underlying cdf is purely discrete, mixed, or continuous, J. Stat. Software, 95 (2020), 1–42. https://doi.org/10.18637/jss.v095.i10 doi: 10.18637/jss.v095.i10
|
| [36] |
V. W. Berger, Y. Zhou, Kolmogorov-Smirnov test: overview, Wiley Statsref, 2014. https://doi.org/10.1002/9781118445112.stat06558 doi: 10.1002/9781118445112.stat06558
|
| [37] |
S. Yue, C. Wang, The Mann-Kendall test modified by effective sample size to detect trend in serially correlated hydrological series, Water Resour. Manage., 18 (2004), 201–218. https://doi.org/10.1023/B:WARM.0000043140.61082.60 doi: 10.1023/B:WARM.0000043140.61082.60
|
| [38] |
V. Hodge, J. Austin, A survey of outlier detection methodologies, Artif. Intell. Rev., 22 (2004), 85–126. https://doi.org/10.1023/B:AIRE.0000045502.10941.a9 doi: 10.1023/B:AIRE.0000045502.10941.a9
|
| [39] |
D. Olszewski, M. Iwanowski, W. Graniszewski, Dimensionality reduction for detection of anomalies in the IoT traffic data, Future Gener. Comput. Syst., 151 (2024), 137–151. https://doi.org/10.1016/j.future.2023.09.033 doi: 10.1016/j.future.2023.09.033
|
| [40] |
F. T. Liu, K. M. Ting, Z. H. Zhou, Isolation forest, 2008 Eighth IEEE International Conference on Data Mining, 2008,413–422. https://doi.org/10.1109/ICDM.2008.17 doi: 10.1109/ICDM.2008.17
|
| [41] |
F. T. Liu, K. M. Ting, Z. H. Zhou, Isolation-based anomaly detection, ACM Trans. Knowl. Discovery Data, 6 (2012), 1–39. https://doi.org/10.1145/2133360.2133363 doi: 10.1145/2133360.2133363
|
| [42] |
I. Souiden, M. N. Omri, Z. Brahmi, A survey of outlier detection in high dimensional data streams, Comput. Sci. Rev., 44 (2022), 100463. https://doi.org/10.1016/j.cosrev.2022.100463 doi: 10.1016/j.cosrev.2022.100463
|
| [43] |
L. Torlay, M. Perrone-Bertolotti, E. Thomas, M. Baciu, Machine learning-XGBoost analysis of language networks to classify patients with epilepsy, Brain Inf., 4 (2017), 159–169. https://doi.org/10.1007/s40708-017-0065-7 doi: 10.1007/s40708-017-0065-7
|
| [44] |
S. Mirjalili, A. Lewis, The whale optimization algorithm, Adv. Eng. Software, 95 (2016), 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008 doi: 10.1016/j.advengsoft.2016.01.008
|
| [45] |
F. S. Gharehchopogh, H. Gholizadeh, A comprehensive survey: whale optimization algorithm and its applications, Swarm Evol. Comput., 48 (2019), 1–24. https://doi.org/10.1016/j.swevo.2019.03.004 doi: 10.1016/j.swevo.2019.03.004
|
| [46] |
W. Yang, K. Xia, S. Fan, L. Wang, T. Li, J. Zhang, et al., A multi-strategy whale optimization algorithm and its application, Eng. Appl. Artif. Intell., 108 (2022), 104558. https://doi.org/10.1016/j.engappai.2021.104558 doi: 10.1016/j.engappai.2021.104558
|
| [47] |
W. N. Street, Y. Kim, A streaming ensemble algorithm (SEA) for large-scale classification, Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2001,377–382. https://doi.org/10.1145/502512.502568 doi: 10.1145/502512.502568
|
| [48] |
G. Widmer, M. Kubat, Learning in the presence of concept drift and hidden contexts, Mach. Learn., 23 (1996), 69–101. https://doi.org/10.1023/A:1018046501280 doi: 10.1023/A:1018046501280
|
| [49] |
G. Hulten, L. Spencer, P. Domingos, Mining time-changing data streams, Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2001, 97–106. https://doi.org/10.1145/502512.502529 doi: 10.1145/502512.502529
|
| [50] |
H. Wang, W. Fan, P. S. Yu, J. Han, Mining concept-drifting data streams using ensemble classifiers, Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2003,226–235. https://doi.org/10.1145/956750.956778 doi: 10.1145/956750.956778
|
| [51] |
M. A. Ferrag, O. Friha, D. Hamouda, L. Maglaras, H. Janicke, Edge-IIoTset: a new comprehensive realistic cyber security dataset of IoT and IIoT applications for centralized and federated learning, IEEE Access, 10 (2022), 40281–40306. https://doi.org/10.1109/ACCESS.2022.3165809 doi: 10.1109/ACCESS.2022.3165809
|












Figures(13) / Tables(8)

Renjie Chu, Peiyuan Jin, Hanli Qiao, Quanxi Feng. Intrusion detection in the IoT data streams using concept drift localization[J]. AIMS Mathematics, 2024, 9(1): 1535-1561. doi: 10.3934/math.2024076







 DownLoad:
DownLoad: