Progressive first-failure censoring has been widely-used in practice when the experimenter desires to remove some groups of test units before the first-failure is observed in all groups. Practically, some test groups may haphazardly quit the experiment at each progressive stage, which cannot be determined in advance. As a result, in this article, we propose a progressively first-failure censored sampling with random removals, which allows the removal of the surviving group(s) during the execution of the life test with uncertain probability, called the beta-binomial probability law. Generalized extreme value lifetime model has been widely-used to analyze a variety of extreme value data, including flood flows, wind speeds, radioactive emissions, and others. So, when the sample observations are gathered using the suggested censoring plan, the Bayes and maximum likelihood approaches are used to estimate the generalized extreme value distribution parameters. Furthermore, Bayes estimates are produced under balanced symmetric and asymmetric loss functions. A hybrid Gibbs within the Metropolis-Hastings method is suggested to gather samples from the joint posterior distribution. The highest posterior density intervals are also provided. To further understand how the suggested inferential approaches actually work in the long run, extensive Monte Carlo simulation experiments are carried out. Two applications of real-world datasets from clinical trials are examined to show the applicability and feasibility of the suggested methodology. The numerical results showed that the proposed sampling mechanism is more flexible to operate a classical (or Bayesian) inferential approach to estimate any lifetime parameter.
Citation: Ahmed Elshahhat, Vikas Kumar Sharma, Heba S. Mohammed. Statistical analysis of progressively first-failure-censored data via beta-binomial removals[J]. AIMS Mathematics, 2023, 8(9): 22419-22446. doi: 10.3934/math.20231144
Progressive first-failure censoring has been widely-used in practice when the experimenter desires to remove some groups of test units before the first-failure is observed in all groups. Practically, some test groups may haphazardly quit the experiment at each progressive stage, which cannot be determined in advance. As a result, in this article, we propose a progressively first-failure censored sampling with random removals, which allows the removal of the surviving group(s) during the execution of the life test with uncertain probability, called the beta-binomial probability law. Generalized extreme value lifetime model has been widely-used to analyze a variety of extreme value data, including flood flows, wind speeds, radioactive emissions, and others. So, when the sample observations are gathered using the suggested censoring plan, the Bayes and maximum likelihood approaches are used to estimate the generalized extreme value distribution parameters. Furthermore, Bayes estimates are produced under balanced symmetric and asymmetric loss functions. A hybrid Gibbs within the Metropolis-Hastings method is suggested to gather samples from the joint posterior distribution. The highest posterior density intervals are also provided. To further understand how the suggested inferential approaches actually work in the long run, extensive Monte Carlo simulation experiments are carried out. Two applications of real-world datasets from clinical trials are examined to show the applicability and feasibility of the suggested methodology. The numerical results showed that the proposed sampling mechanism is more flexible to operate a classical (or Bayesian) inferential approach to estimate any lifetime parameter.

| [1] |
U. Balasooriya, Failure-censored reliability sampling plans for the exponential distribution, J. Stat. Comput. Sim., 52 (1995), 337–349. https://doi.org/10.1080/00949659508811684 doi: 10.1080/00949659508811684

|
| [2] |
S. J. Wu, C. Kuş, On estimation based on progressive first-failure-censored sampling, Comput. Stat. Data Anal., 53 (2009), 3659–3670. https://doi.org/10.1016/j.csda.2009.03.010 doi: 10.1016/j.csda.2009.03.010
|
| [3] |
S. K. Ashour, A. A. El-Sheikh, A. Elshahhat, Inferences and optimal censoring schemes for progressively first-failure censored Nadarajah-Haghighi distribution, Sankhya A, 84 (2020), 885–923. https://doi.org/10.1007/s13171-019-00175-2 doi: 10.1007/s13171-019-00175-2
|
| [4] | M. M. Yousef, E. M. Almetwally, Multi stress-strength reliability based on progressive first failure for Kumaraswamy model: Bayesian and non-Bayesian estimation, Symmetry, 13 (2021). https://doi.org/10.3390/sym13112120 |
| [5] |
M. Nassar, R. Alotaibi, A. Elshahhat, Statistical analysis of alpha power exponential parameters using progressive first-failure censoring with applications, Axioms, 11 (2022), 553. https://doi.org/10.3390/axioms11100553 doi: 10.3390/axioms11100553
|
| [6] |
D. A. Ramadan, E. M. Almetwally, A. H. Tolba, Statistical inference for multi stress-strength reliability based on progressive first failure with lifetime inverse Lomax distribution and analysis of transformer insulation data, Qual. Reliab. Eng. Int., 2023. https://doi.org/10.1002/qre.3362 doi: 10.1002/qre.3362
|
| [7] | S. R. Huang, S. J. Wu, Estimation of Pareto distribution under progressive first-failure censoring with random removals, J. Chinese Stat. Assoc., 49 (2011), 82–97. |
| [8] |
S. K. Ashour, A. A. El-Sheikh, A. Elshahhat, Inferences for Weibull lifetime model under progressively first-failure censored data with binomial random removals, Stat. Optim. Inform. Comput., 9 (2020), 47–60. https://doi.org/10.19139/soic-2310-5070-611 doi: 10.19139/soic-2310-5070-611
|
| [9] |
S. K. Singh, U. Singh, V. K. Sharma, Expected total test time and Bayesian estimation for generalized Lindley distribution under progressively Type-Ⅱ censored sample where removals follow the beta-binomial probability law, Appl. Math. Comput., 222 (2013), 402–419. https://doi.org/10.1016/j.amc.2013.07.058 doi: 10.1016/j.amc.2013.07.058
|
| [10] |
A. Kaushik, U. Singh, S. K. Singh, Bayesian inference for the parameters of Weibull distribution under progressive Type-Ⅰ interval censored data with beta-binomial removals, Commun. Stat.-Simul. Comput., 46 (2017), 3140–3158. https://doi.org/10.1080/03610918.2015.1076469 doi: 10.1080/03610918.2015.1076469
|
| [11] | P. K. Sangal, A. Sinha, Classical estimation in exponential power distribution under Type-Ⅰ progressive hybrid censoring with beta-binomial removals, Int. J. Agric. Stat. Sci., 17 (2021), 1973–1988. |
| [12] |
C. Ding, C. Yang, S. K. Tse, Accelerated life test sampling plans for the Weibull distribution under Type-Ⅰ progressive interval censoring with random removals, J. Stat. Comput. Simul., 80 (2010), 903–914. https://doi.org/10.1080/00949650902834478 doi: 10.1080/00949650902834478
|
| [13] |
C. Ding, S. K. Tse, Design of accelerated life test plans under progressive Type-Ⅱ interval censoring with random removals, J. Stat. Comput. Simul., 83 (2013), 1330–1343. https://doi.org/10.1080/00949655.2012.660155 doi: 10.1080/00949655.2012.660155
|
| [14] |
A. Kaushik, A. Pandey, U. Singh, S. K. Singh, Bayesian estimation of the parameters of exponentiated exponential distribution under progressive interval Type-Ⅰ censoring scheme with binomial removals, Aust. J. Stat., 46 (2017), 43–47. https://doi.org/10.17713/ajs.v46i2.566 doi: 10.17713/ajs.v46i2.566
|
| [15] |
M. Chacko, R. Mohan, Bayesian analysis of Weibull distribution based on progressive Type-Ⅱ censored competing risks data with binomial removals, Comput. Stat., 34 (2019), 233–252. https://doi.org/10.1007/s00180-018-0847-2 doi: 10.1007/s00180-018-0847-2
|
| [16] |
A. Elshahhat, M. Nassar, Analysis of adaptive Type-Ⅱ progressively hybrid censoring with binomial removals, J. Stat. Comput. Simul., 93 (2022), 1077–1103. https://doi.org/10.1080/00949655.2022.2127149 doi: 10.1080/00949655.2022.2127149
|
| [17] | C. D. Lai, Generalized Weibull distributions, Springer Briefs in Statistics, Springer, Berlin, Heidelberg, 2014. |
| [18] | G. M. Cordeiro, E. M. M. Ortega, G. Silva, The beta extended Weibull family, J. Probab. Stat. Sci., 10 (2012), 15–40. |
| [19] |
N. Balakrishnan, N. Kannan, C. T. Lin, S. J. S. Wu, Inference for the extreme value distribution under progressive Type-Ⅱ censoring, J. Stat. Comput. Simul., 74 (2004), 25–45. https://doi.org/10.1080/0094965031000105881 doi: 10.1080/0094965031000105881
|
| [20] |
R. Pandey, J. Kumar, N. Kumari, Bayesian parameter estimation of beta log-Weibull distribution under Type-Ⅱ progressive censoring, J. Stat. Manag. Syst., 22 (2019), 977–1004. https://doi.org/10.1080/09720510.2019.1602355 doi: 10.1080/09720510.2019.1602355
|
| [21] |
N. Kumari, R. Pandey, On Bayesian parameter estimation of beta log-Weibull distribution under Type-Ⅱ censoring, Commun. Stat.-Simul. Comput., 2019. https://doi.org/10.1080/03610918.2019.1565579 doi: 10.1080/03610918.2019.1565579
|
| [22] |
A. Henningsen, O. Toomet, maxLik: A package for maximum likelihood estimation in R, Comput. Stat., 26 (2011), 443–458. https://doi.org/10.1007/s00180-010-0217-1 doi: 10.1007/s00180-010-0217-1
|
| [23] | M. Plummer, N. Best, K. Cowles, K. Vines, CODA: Convergence diagnosis and output analysis for MCMC, R news, 6 (2006), 7–11. |
| [24] | I. Usta, H. Gezer, Parameter estimation in Weibull distribution on progressively Type-Ⅱ censored sample with beta-binomial removals, Econ. Bus. J., 10 (2016), 505–515. |
| [25] |
P. K. Vishwakarma, A. Kaushik, A. Pandey, U. Singh, S. K. Singh, Bayesian estimation for inverse Weibull distribution under progressive Type-Ⅱ censored data with beta-binomial removals, Aust. J. Stat., 47 (2018), 77–94. https://doi.org/10.17713/ajs.v47i1.578 doi: 10.17713/ajs.v47i1.578
|
| [26] | J. F. Lawless, Statistical models and methods for lifetime data, 2 Eds., John Wiley and Sons, Hoboken, New Jersey, USA, 2003. https://doi.org/10.1002/9781118033005 |
| [27] |
A. Zellner, Bayesian estimation and prediction using asymmetric loss functions, J. Am. Stat. Assoc., 81 (1986), 446–451. https://doi.org/10.1080/01621459.1986.10478289 doi: 10.1080/01621459.1986.10478289
|
| [28] |
M. J. Jozani, É. Marchand, A. Parsian, Bayesian and Robust Bayesian analysis under a general class of balanced loss functions, Stat. Pap., 53 (2012), 51–60. https://doi.org/10.1007/s00362-010-0307-8 doi: 10.1007/s00362-010-0307-8
|
| [29] |
D. R. Barot, M. N. Patel, Posterior analysis of the compound Rayleigh distribution under balanced loss functions for censored data, Commun. Stat.-Theor. M., 46 (2017), 1317–1336. https://doi.org/10.1080/03610926.2015.1019140 doi: 10.1080/03610926.2015.1019140
|
| [30] |
K. Maiti, S. Kayal, Estimation for the generalized Fréchet distribution under progressive censoring scheme, Int. J. Syst. Assur. Eng. Manag., 10 (2019), 1276–1301. https://doi.org/10.1007/s13198-019-00875-w doi: 10.1007/s13198-019-00875-w
|
| [31] |
M. V. Ahmadi, M. Doostparast, Pareto analysis for the lifetime performance index of products on the basis of progressively first-failure-censored batches under balanced symmetric and asymmetric loss functions, J. Appl. Stat., 46 (2019), 1196–1227. https://doi.org/10.1080/02664763.2018.1541170 doi: 10.1080/02664763.2018.1541170
|
| [32] |
W. K. Hastings, Monte Carlo sampling methods using Markov chains and their applications, Biometrika, 57 (1970), 97–109. https://doi.org/10.1093/biomet/57.1.97 doi: 10.1093/biomet/57.1.97
|
| [33] |
M. H. Chen, Q. M. Shao, Monte Carlo estimation of Bayesian credible and HPD intervals, J. Comput. Graph. Stat., 8 (1999), 69–92. https://doi.org/10.1080/10618600.1999.10474802 doi: 10.1080/10618600.1999.10474802
|
| [34] | D. Collett, Modelling survival data in medical research, 3 Eds., Chapman and Hall/CRC, London, UK, 2013. |
| [35] |
S. K. Singh, U. Singh, M. Kumar, Bayesian estimation for Poisson-exponential model under progressive Type-Ⅱ censoring data with binomial removal and its application to ovarian cancer data, Commun. Stat.-Simul. C., 45 (2016), 3457–3475. https://doi.org/10.1080/03610918.2014.948189 doi: 10.1080/03610918.2014.948189
|
| [36] |
J. E. Contreras-Reyes, F. O. L. Quintero, R. Wiff, Bayesian modeling of individual growth variability using back-calculation: Application to pink cusk-eel (Genypterus blacodes) off Chile, Ecol. Model., 385 (2018), 145–153. https://doi.org/10.1016/j.ecolmodel.2018.07.002 doi: 10.1016/j.ecolmodel.2018.07.002
|
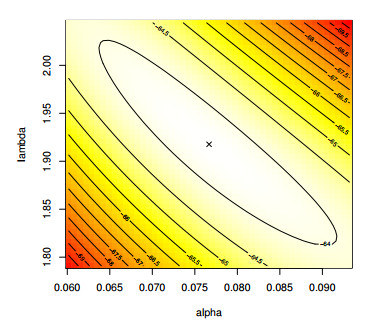
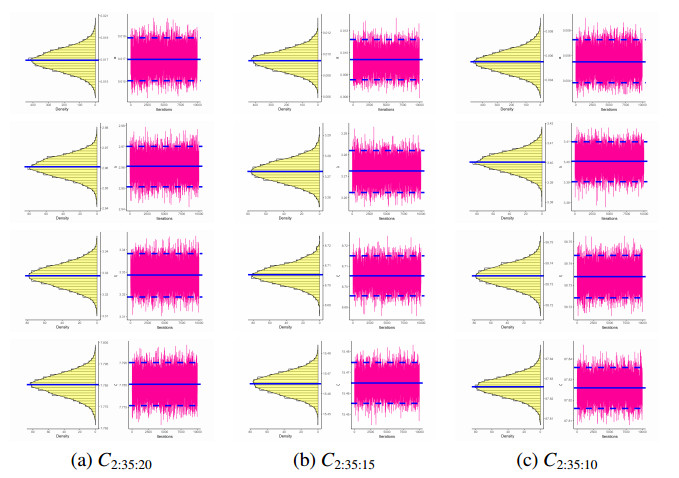
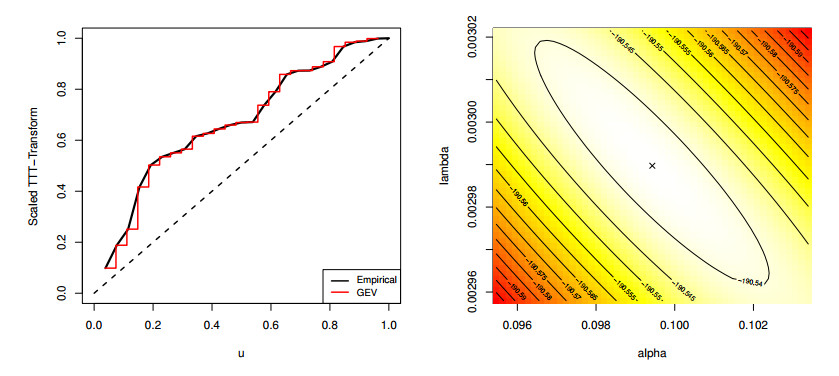
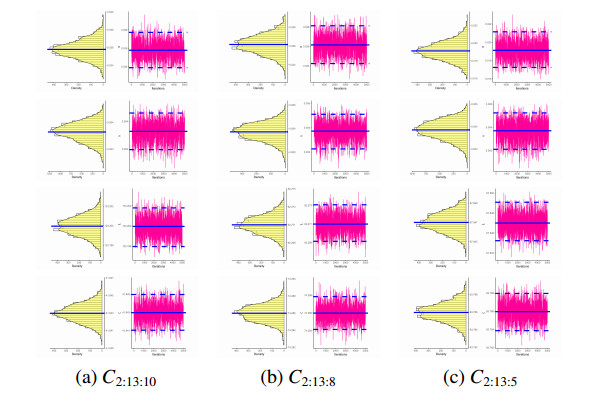
Figures(4) / Tables(15)

Ahmed Elshahhat, Vikas Kumar Sharma, Heba S. Mohammed. Statistical analysis of progressively first-failure-censored data via beta-binomial removals[J]. AIMS Mathematics, 2023, 8(9): 22419-22446. doi: 10.3934/math.20231144







 DownLoad:
DownLoad: