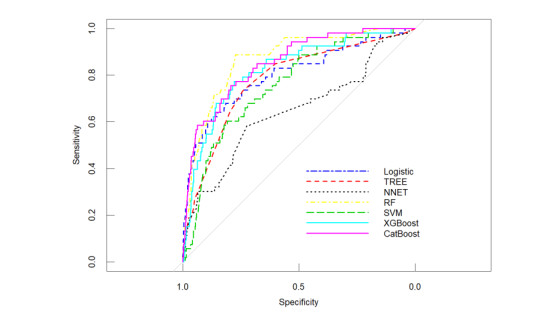
Artificial intelligence (AI) models can effectively identify the financial risks existing in Chinese manufacturing enterprises. We use the financial ratios of 1668 Chinese A-share listed manufacturing enterprises from 2016 to 2021 for our empirical analysis. An AI model is used to obtain the financial distress prediction value for the listed manufacturing enterprises. Our results show that the random forest model has high accuracy in terms of the empirical prediction of the financial distress of Chinese manufacturing enterprises, which reflects the effectiveness of the AI model in predicting the financial distress of the listed manufacturing enterprises. Profitability has the highest degree of importance for predicting financial distress in manufacturing firms, especially the return on equity. The results in this paper have good policy implications for how to use the AI model to improve the early warning and monitoring system of financial risks and enhance the ability of financial risk prevention and control.
Citation: Junhao Zhong, Zhenzhen Wang. Artificial intelligence techniques for financial distress prediction[J]. AIMS Mathematics, 2022, 7(12): 20891-20908. doi: 10.3934/math.20221145
Artificial intelligence (AI) models can effectively identify the financial risks existing in Chinese manufacturing enterprises. We use the financial ratios of 1668 Chinese A-share listed manufacturing enterprises from 2016 to 2021 for our empirical analysis. An AI model is used to obtain the financial distress prediction value for the listed manufacturing enterprises. Our results show that the random forest model has high accuracy in terms of the empirical prediction of the financial distress of Chinese manufacturing enterprises, which reflects the effectiveness of the AI model in predicting the financial distress of the listed manufacturing enterprises. Profitability has the highest degree of importance for predicting financial distress in manufacturing firms, especially the return on equity. The results in this paper have good policy implications for how to use the AI model to improve the early warning and monitoring system of financial risks and enhance the ability of financial risk prevention and control.

| [1] |
E. I. Altman, Financial ratios, discriminant analysis and the prediction of corporate bankruptcy, The Journal of Finance, 23 (1968), 589–609. https://doi.org/10.1111/j.1540-6261.1968.tb00843.x doi: 10.1111/j.1540-6261.1968.tb00843.x

|
| [2] |
S. B. Jabeur, C. Gharib, S. Mefteh-Wali, W. B. Arfi, CatBoost model and artificial intelligence techniques for corporate failure prediction, Technol. Forecast. Soc., 166 (2021), 120658. https://doi.org/10.1016/j.techfore.2021.120658 doi: 10.1016/j.techfore.2021.120658
|
| [3] |
K. Peng, G. Yan, A survey on deep learning for financial risk prediction, Quant. Financ. Econ., 5 (2021), 716–737. https://doi.org/10.3934/QFE.2021032 doi: 10.3934/QFE.2021032
|
| [4] |
T. M. Awan, M. S. Khan, I. U. Haq, S. Kazmi, Oil and stock markets volatility during pandemic times: a review of G7 countries, Green Finance, 3 (2021), 15–27. https://doi.org/10.3934/GF.2021002 doi: 10.3934/GF.2021002
|
| [5] | E. I. Altman, Predicting financial distress of companies: revisiting the Z-score and ZETA® models, In: Handbook of research methods and applications in empirical finance, Edward Elgar Publishing, 2013,428–456. https://doi.org/10.4337/9780857936080.00027 |
| [6] |
T. H. Li, X. Li, G. K. Liao, Business cycles and energy intensity. Evidence from emerging economies, Borsa Istanb. Rev., 22 (2022), 560–570. https://doi.org/10.1016/j.bir.2021.07.005 doi: 10.1016/j.bir.2021.07.005
|
| [7] |
S. L. Chen, J. H. Zhong, P. Failler, Does China transmit financial cycle spillover effects to the G7 countries?, Economic Research-Ekonomska Istrazivanja, 35 (2022), 5184–5201. https://doi.org/10.1080/1331677x.2021.2025123 doi: 10.1080/1331677x.2021.2025123
|
| [8] |
Y. Liu, Z. H. Li, M. R. Xu, The influential factors of financial cycle spillover: evidence from China, Emerg. Mark. Financ. Tr., 56 (2020), 1336–1350. https://doi.org/10.1080/1540496x.2019.1658076 doi: 10.1080/1540496x.2019.1658076
|
| [9] |
F. Mai, S. N. Tian, C. Lee, L. Ma, Deep learning models for bankruptcy prediction using textual disclosures, Eur. J. Oper. Res., 274 (2019), 743–758. https://doi.org/10.1016/j.ejor.2018.10.024 doi: 10.1016/j.ejor.2018.10.024
|
| [10] |
D. Qiu, D. Li, Comments on the "SSF Report" from the perspective of economic statistics, Green Finance, 3 (2021), 403–463. https://doi.org/ 10.3934/GF.2021020 doi: 10.3934/GF.2021020
|
| [11] |
Z. H. Li, J. H. Zhong, Impact of economic policy uncertainty shocks on China's financial conditions, Financ. Res. Lett., 35 (2020), 101303. https://doi.org/10.1016/j.frl.2019.101303 doi: 10.1016/j.frl.2019.101303
|
| [12] |
S. P. Zhao, K. Xu, Z. Wang, C. Liang, W. Lu, B. Chen, Financial distress prediction by combining sentiment tone features, Econ. Model., 106 (2022), 105709. https://doi.org/10.1016/j.econmod.2021.105709 doi: 10.1016/j.econmod.2021.105709
|
| [13] |
Z. H. Li, H. Dong, C. Floros, A. Charemis, P. Failler, Re-examining Bitcoin volatility: A CAViaR-based approach, Emerg. Mark. Financ. Tr., 58 (2022), 1320–1338. https://doi.org/10.1080/1540496x.2021.1873127 doi: 10.1080/1540496x.2021.1873127
|
| [14] |
Z. Huang, H. Dong, S. Jia, Equilibrium pricing for carbon emission in response to the target of carbon emission peaking, Energ. Econ., 112 (2022), 106160. https://doi.org/10.1016/j.eneco.2022.106160 doi: 10.1016/j.eneco.2022.106160
|
| [15] |
T. T. Chen, S. J. Lee, A weighted LS-SVM based learning system for time series forecasting, Inform. Sciences, 299 (2015), 99–116. https://doi.org/10.1016/j.ins.2014.12.031 doi: 10.1016/j.ins.2014.12.031
|
| [16] |
E. Dumitrescu, S. Hue, C. Hurlin, S. Tokpavi, Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects, Eur. J. Oper. Res., 297 (2022), 1178–1192. https://doi.org/10.1016/j.ejor.2021.06.053 doi: 10.1016/j.ejor.2021.06.053
|
| [17] |
J. M. Liu, S. C. Zhang, H. Y. Fan, A two-stage hybrid credit risk prediction model based on XGBoost and graph-based deep neural network, Expert Syst. Appl., 195 (2022), 116624. https://doi.org/10.1016/j.eswa.2022.116624 doi: 10.1016/j.eswa.2022.116624
|
| [18] |
S. Bag, S. Gupta, A. Kumar, U. Sivarajah, An integrated artificial intelligence framework for knowledge creation and B2B marketing rational decision making for improving firm performance, Ind. Market. Manag., 92 (2021), 178–189. https://doi.org/10.1016/j.indmarman.2020.12.001 doi: 10.1016/j.indmarman.2020.12.001
|
| [19] |
F. Barboza, H. Kimura, E. Altman, Machine learning models and bankruptcy prediction, Expert Syst. Appl., 83 (2017), 405–417. https://doi.org/10.1016/j.eswa.2017.04.006 doi: 10.1016/j.eswa.2017.04.006
|
| [20] |
S. Papadopoulos, C. E. Kontokosta, Grading buildings on energy performance using city benchmarking data, Appl. Energ., 233 (2019), 244–253. https://doi.org/10.1016/j.apenergy.2018.10.053 doi: 10.1016/j.apenergy.2018.10.053
|
| [21] |
R. Kellner, M. Nagl, D. Rosch, Opening the black box—Quantile neural networks for loss given default prediction, J. Bank. Financ., 134 (2022), 106334. https://doi.org/10.1016/j.jbankfin.2021.106334 doi: 10.1016/j.jbankfin.2021.106334
|
| [22] |
D. Qiu, D. Li, Paradox in deviation measure and trap in method improvement—take international comparison as an example, Quant. Financ. Econ., 5 (2021), 591–603. https://doi.org/10.3934/QFE.2021026 doi: 10.3934/QFE.2021026
|
| [23] | T. Q. Chen, C. Guestrin, XGBoost: a scalable tree boosting system, In: KDD'16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco: Assoc Computing Machinery, 2016,785–794. https://doi.org/10.1145/2939672.2939785 |
| [24] |
P. Carmona, F. Climent, A. Momparler, Predicting failure in the U.S. banking sector: an extreme gradient boosting approach, Int. Rev. Econ. Financ., 61 (2019), 304–323. https://doi.org/10.1016/j.iref.2018.03.008 doi: 10.1016/j.iref.2018.03.008
|
| [25] |
D. Ardila, A. Ahmed, D. Sornette, Comparing ask and transaction prices in the Swiss housing market, Quant. Financ. Econ., 5 (2021), 67–93. https://doi.org/10.3934/QFE.2021004 doi: 10.3934/QFE.2021004
|
| [26] | Z. H. Li, H. Chen, B. Mo, Can digital finance promote urban innovation? Evidence from China, Borsa Istanb. Rev., in press. https://doi.org/10.1016/j.bir.2022.10.006 |
| [27] |
L. Breiman, Random forests, Machine Learning, 45 (2001), 5–32. https://doi.org/10.1023/a:1010933404324 doi: 10.1023/a:1010933404324
|
| [28] |
R. Katuwal, P. N. Suganthan, L. Zhang, Heterogeneous oblique random forest, Pattern Recogn., 99 (2020), 107078. https://doi.org/10.1016/j.patcog.2019.107078 doi: 10.1016/j.patcog.2019.107078
|
| [29] |
E. I. Altman, M. Iwanicz-Drozdowska, E. K. Laitinen, A. Suvas, Financial distress prediction in an international context: a review and empirical analysis of Altman's Z-score model, J. Int. Fin. Manag. Acc., 28 (2017), 131–171. https://doi.org/10.1111/jifm.12053 doi: 10.1111/jifm.12053
|
| [30] |
G. K. Liao, P. Hou, X. Y. Shen, K. Albitar, The impact of economic policy uncertainty on stock returns: the role of corporate environmental responsibility engagement, Int. J. Financ. Econ., 26 (2021), 4386–4392. https://doi.org/10.1002/ijfe.2020 doi: 10.1002/ijfe.2020
|
| [31] |
R. B. Geng, I. Bose, X. Chen, Prediction of financial distress: an empirical study of listed Chinese companies using data mining, Eur. J. Oper. Res., 241 (2015), 236–247. https://doi.org/10.1016/j.ejor.2014.08.016 doi: 10.1016/j.ejor.2014.08.016
|
| [32] |
X. B. Tang, S. X. Li, M. L. Tan, W. X. Shi, Incorporating textual and management factors into financial distress prediction: a comparative study of machine learning methods, J. Forecasting, 39 (2020), 769–787. https://doi.org/10.1002/for.2661 doi: 10.1002/for.2661
|
| [33] |
H. Li, C. J. Li, X. J. Wu, J. Sun, Statistics-based wrapper for feature selection: an implementation on financial distress identification with support vector machine, Appl. Soft Comput., 19 (2014), 57–67. https://doi.org/10.1016/j.asoc.2014.01.018 doi: 10.1016/j.asoc.2014.01.018
|
| [34] |
S. Liu, X. Shen, T. Jiang, P. Failler, Impacts of the financialization of manufacturing enterprises on total factor productivity: empirical examination from China's listed companies, Green Finance, 3 (2021), 59–89. https://doi.org/10.3934/GF.2021005 doi: 10.3934/GF.2021005
|
| [35] |
Y. Xia, L. He, Y. Li, N. Liu, Y. Ding, Predicting loan default in peer-to-peer lending using narrative data, J. Forecasting, 39 (2020), 260–280. https://doi.org/10.1002/for.2625 doi: 10.1002/for.2625
|
| [36] |
E. A. Mohamed, I. E. Ahmed, R. Mehdi, H. Hussain, Impact of corporate performance on stock price predictions in the UAE markets: Neuro-fuzzy model, Intell. Syst. Account., 28 (2021), 52–71. https://doi.org/10.1002/isaf.1484 doi: 10.1002/isaf.1484
|
| [37] |
M. Zhou, H. Liu, Y. Hu, Research on corporate financial performance prediction based on self-organizing and convolutional neural networks, Expert Syst., 39 (2022), e13042. https://doi.org/10.1111/exsy.13042 doi: 10.1111/exsy.13042
|






Figures(7) / Tables(9)

Junhao Zhong, Zhenzhen Wang. Artificial intelligence techniques for financial distress prediction[J]. AIMS Mathematics, 2022, 7(12): 20891-20908. doi: 10.3934/math.20221145







 DownLoad:
DownLoad: