Citation: Snezhana Hristova, Kremena Stefanova, Angel Golev. Dynamic modeling of discrete leader-following consensus with impulses[J]. AIMS Mathematics, 2019, 4(5): 1386-1402. doi: 10.3934/math.2019.5.1386

| [1] | R. Agarwal, Difference Equations and Inequalities: Theory, Methods, and Applications, 2 Eds, New York: CRC Press, 2000. |
| [2] | R. Agarwal, S. Hristova, A. Golev, et al., Monotone-iterative method for mixed boundary value problems for generalized difference equations with "maxima", J. Appl. Math. Comput., 43 (2013), 213-233. |
| [3] | L. J. S. Allen, Some discrete-time SI, SIR, and SIS epidemic models, Math. Biosci., 124 (1994), 83-105. |
| [4] | J. Almeida, C. Silvestre, A. Pascoa, Continuous-time consensus with discrete-time communications, Syst. Control Lett., 61 (2012), 788-796. |
| [5] | S. Elaydi, An Introduction to Difference Equations, 3 Eds., Springer, 2005. |
| [6] | W. Hu, Q. Zhu, Moment exponential stability of stochastic nonlinear delay systems with impulse effects at random times, Intern. J. Robust Nonl. Contr., 29 (2019), 3809-3820. |
| [7] | G. Jing, Y. Zheng, L. Wang, Consensus of multiagent systems with distance-dependent communication networks, IEEE T. Neur. Net. Lear., 28 (2017), 2712-2726. |
| [8] | W. G. Kelley, A. C. Peterson, Difference Equations: An Introduction with Applications, 2 Eds., Academic Press, 2001. |
| [9] | U. Krause, A discrete nonlinear and non-autonomous model of consensus formation, Commun. Differ. Equations, 2000 (2000), 227-236. |
| [10] | J. L. Li, J. H. Shen, Positive solutions for first order difference equations with impulses, Int. J. Differ. Equations, 1 (2006), 225-239. |
| [11] | B. Liu, W. Lu, L. Jiao, et al., Consensus in networks of multi-agents with stochastically switching topology and time-varying delays, SIAM J. Control Optim., 56 (2018), 1884-1911. |
| [12] | J. Ma, Y. Zheng, L. Wang, LQR-based optimal topology of leader following consensus, J. Robust Nonlinear Control, 25 (2015), 3404-3421. |
| [13] | A. B. Malinowska, E. Schmeidel, M. Zdanowicz, Discrete leader-following consensus, Math. Meth. Appl. Sci., 40 (2017), 7307-7315. |
| [14] | S. Mohamad, K. Gopalsamy, Exponential stability of continuoustime and discrete-time cellular neural networks with delays, Appl. Math. Comput., 135 (2003), 17-38. |
| [15] | R. Olfati-Saber, J. Fax, R. Murray, Consensus and cooperation in networked multi-agent systems, Proc. of the IEEE, 95 (2007), 215-233. |
| [16] | L. Wang, F. Xiao, A new approach to consensus problems in discrete-time multi-agent systems with time-delays, F. Sci. China Ser. F, 50 (2007), 625-635. |
| [17] | W. Ni, D. Z. Cheng, Leader-following consensus of multi-agent systems under fixed and switching topologies, Syst. Control Lett., 59 (2010), 209-217. |
| [18] | Z. Yu, H. Jiangn, C. Hu, Leader-following consensus of fractional-order multi-agent systems under fixed topology, Neurocomputing, 149 (2015), 613-620. |
| [19] | Q. Zhu, pth Moment exponential stability of impulsive stochastic functional differential equations with Markovian switching, J. Franklin Inst., 351 (2014), 3965-3986. |
| [20] | Q. Zhu, J. Cao, Stability analysis of Markovian jump stochastic BAM neural networks with impulse control and mixed time delays, IEEE T. Neur. Net. Lear., 23 (2012), 467-479. |
| [21] | Q. Zhu, J. Cao, R. Rakkiyappan, Exponential input-to-state stability of stochastic CohenGrossberg neural networks with mixed delays, Nonlinear Dyn., 79 (2015), 1085-1098. |
| [22] | Q. Zhu, B. Song, Exponential stability of impulsive nonlinear stochastic differential equations with mixed delays, Nonlinear Anal. Real World Appl., 12 (2011), 2851-2860. |
| [23] | W. Zou, P. Shi, Z. Xiang, et al., Consensus tracking control of switched stochastic nonlinear multiagent systems via event-triggered strategy, IEEE T. Neur. Net. Lear., DOI: 10.1109/TNNLS.2019.2917137. |
| [24] | W. Zou, Z. Xiang, C. K. Ahn, Mean square leader-following consensus of second-order nonlinear multi-agent systems with noises and unmodeled dynamics, IEEE T. Sys. Man Cybern., DOI: 10.1109/TSMC.2018.2862140. |
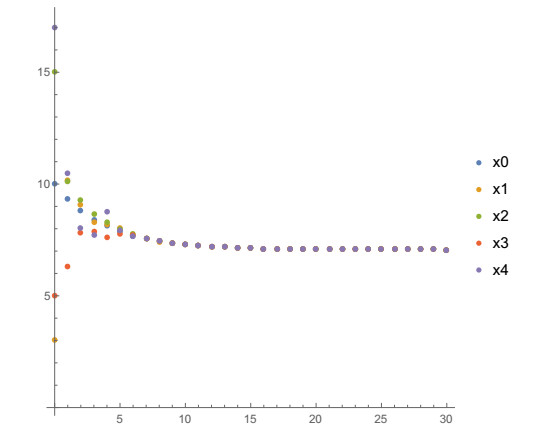
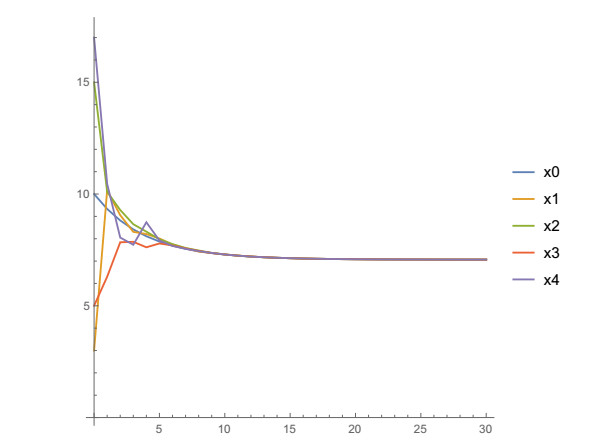
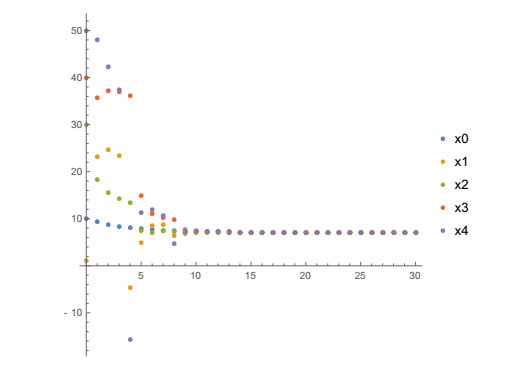
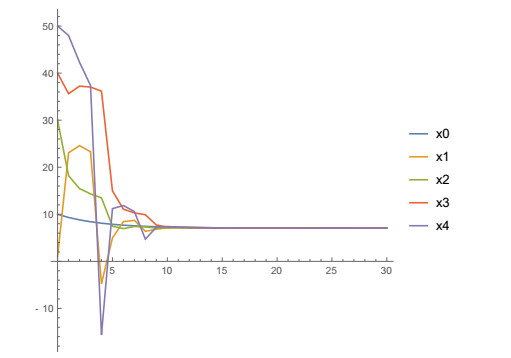
Figures(12) / Tables(5)

Snezhana Hristova, Kremena Stefanova, Angel Golev. Dynamic modeling of discrete leader-following consensus with impulses[J]. AIMS Mathematics, 2019, 4(5): 1386-1402. doi: 10.3934/math.2019.5.1386







 DownLoad:
DownLoad: