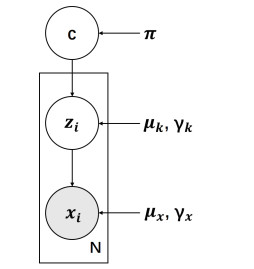
We presented a novel deep generative clustering model called Variational Deep Embedding based on Pairwise constraints and the Von Mises-Fisher mixture model (VDEPV). VDEPV consists of fully connected neural networks capable of learning latent representations from raw data and accurately predicting cluster assignments. Under the assumption of a genuinely non-informative prior, VDEPV adopted a von Mises-Fisher mixture model to depict the hyperspherical interpretation of the data. We defined and established pairwise constraints by employing a random sample mining strategy and applying data augmentation techniques. These constraints enhanced the compactness of intra-cluster samples in the spherical embedding space while improving inter-cluster samples' separability. By minimizing Kullback-Leibler divergence, we formulated a clustering loss function based on pairwise constraints, which regularized the joint probability distribution of latent variables and cluster labels. Comparative experiments with other deep clustering methods demonstrated the excellent performance of VDEPV.
Citation: He Ma, Weipeng Wu. A deep clustering framework integrating pairwise constraints and a VMF mixture model[J]. Electronic Research Archive, 2024, 32(6): 3952-3972. doi: 10.3934/era.2024177
We presented a novel deep generative clustering model called Variational Deep Embedding based on Pairwise constraints and the Von Mises-Fisher mixture model (VDEPV). VDEPV consists of fully connected neural networks capable of learning latent representations from raw data and accurately predicting cluster assignments. Under the assumption of a genuinely non-informative prior, VDEPV adopted a von Mises-Fisher mixture model to depict the hyperspherical interpretation of the data. We defined and established pairwise constraints by employing a random sample mining strategy and applying data augmentation techniques. These constraints enhanced the compactness of intra-cluster samples in the spherical embedding space while improving inter-cluster samples' separability. By minimizing Kullback-Leibler divergence, we formulated a clustering loss function based on pairwise constraints, which regularized the joint probability distribution of latent variables and cluster labels. Comparative experiments with other deep clustering methods demonstrated the excellent performance of VDEPV.

| [1] |
A. E. Ezugwu, A. M. Ikotun, O. O. Oyelade, L. Abualigah, J. O. Agushaka, C. I. Eke, et al., A comprehensive survey of clustering algorithms: State-of-the-art machine learning applications, taxonomy, challenges, and future research prospects, Eng. Appl. Artif. Intell., 110 (2022), 73–89. https://doi.org/10.1016/j.engappai.2022.104743 doi: 10.1016/j.engappai.2022.104743

|
| [2] | S. Zhou, H. Xu, Z. Zheng, J. Chen, Z. li, J. Bu, et al., A comprehensive survey on deep clustering: Taxonomy, challenges, and future directions, preprint, arXiv: 2206.07579. https://doi.org/10.48550/arXiv.2206.07579 |
| [3] |
K. A. István, F. Róbert, G. Péter, Unsupervised clustering for deep learning: A tutorial survey, Acta Polytech. Hung., 15 (2018), 29–53. https://doi.org/10.12700/APH.15.8.2018.8.2 doi: 10.12700/APH.15.8.2018.8.2
|
| [4] | T. R. Davidson, L. Falorsi, N. D. Cao, T. Kipf, J. M. Tomczak, Hyperspherical variational auto-encoders, in 34th Conference on Uncertainty in Artificial Intelligence 2018, UAI 2018, (2018), 856–865. |
| [5] | K. V. Mardia, P. E. Jupp, K. V. Mardia, Directional Statistics, John Wiley & Sons, 2000. https://doi.org/10.1002/9780470316979 |
| [6] |
J. Taghia, Z. Ma, A. Leijon, Bayesian estimation of the von-Mises Fisher mixture model with variational inference, IEEE Trans. Pattern Anal. Mach. Intell., 36 (2014), 1701–1715. https://doi.org/10.1109/TPAMI.2014.2306426 doi: 10.1109/TPAMI.2014.2306426
|
| [7] |
F. Yuan, L. Zhang, J. She, X. Xia, G. Li, Theories and applications of auto-encoder neural networks: A literature survey, Chin. J. Comput., 42 (2019), 203–230. https://doi.org/10.11897/SP.J.1016.2019.00203 doi: 10.11897/SP.J.1016.2019.00203
|
| [8] | S. Zhang, C. You, R. Vidal, C. Li, Learning a self-expressive network for subspace clustering, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 12393–12403. https://doi.org/10.1109/CVPR46437.2021.01221 |
| [9] | Y. Tao, K. Takagi, K. Nakata, Clustering-friendly representation learning via instance discrimination and feature decorrelation, preprint, arXiv: 2106.00131. https://doi.org/10.48550/arXiv.2106.00131 |
| [10] | Z. Dang, C. Deng, X. Yang, K. Wei, H. Huang, Nearest neighbor matching for deep clustering, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 13693–13702. https://doi.org/10.1109/CVPR46437.2021.01348 |
| [11] |
M. Nasrazadani, A. Fatemi, M. Nematbakhsh, Sign prediction in sparse social networks using clustering and collaborative filtering, J. Supercomput., 78 (2022), 596–615. https://doi.org/10.1007/s11227-021-03902-5 doi: 10.1007/s11227-021-03902-5
|
| [12] | N. Alami, M. Meknassi, N. En-nahnahi, Y. E. Adlouni, O. Ammor, Unsupervised neural networks for automatic arabic text summarization using document clustering and topic modeling, Expert Syst. Appl., 172 (2021). https://doi.org/10.1016/j.eswa.2021.114652 |
| [13] | J. Xie, R. Girshick, A. Farhad, Unsupervised deep embedding for clustering analysis, in International Conference on Machine Learning, (2016), 478–487. |
| [14] | X. Ye, C. Wang, A. Imakura, T. Sakurai, Spectral clustering joint deep embedding learning by autoencoder, in 2021 International Joint Conference on Neural Networks (IJCNN), 2021. https://doi.org/10.1109/IJCNN52387.2021.9533825 |
| [15] | K. Thirumoorthy, K. Muneeswaran, A hybrid approach for text document clustering using Jaya optimization algorithm, Expert Syst. Appl., 178 (2021). https://doi.org/10.1016/j.eswa.2021.115040 |
| [16] | J. Cai, J. Fan, W. Guo, S. Wang, Y. Zhang, Z. Zhang, Efficient deep embedded subspace clustering, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022. https://doi.org/10.1109/CVPR52688.2022.00012 |
| [17] | Y. Li, P. Hu, Z. Liu, D. Peng, J. T. Zhou, X. Peng, Contrastive clustering, in Proceedings of the AAAI Conference on Artificial Intelligence, 35 (2021), 8547–8555. https://doi.org/10.1609/aaai.v35i10.17037 |
| [18] | K. Do, T. Tran, S. Venkatesh, Clustering by maximizing mutual information across views, in Proceedings of the AAAI Conference on Artificial Intelligence, (2021), 9928–9938. https://doi.org/10.1109/ICCV48922.2021.00978 |
| [19] | Y. Shen, Z. Shen, M. Wang, J. Qin, P. H. S. Torr, L. Shao, You never cluster alone, Adv. Neural Inf. Process. Syst., 34 (2021), 27734–27746. |
| [20] | H. Zhong, J. Wu, C. Chen, J. Huang, M. Deng, L. Nie, et al., Graph contrastive clustering, in Proceedings of the AAAI Conference on Artificial Intelligence, (2021), 9224–9233. https://doi.org/10.1109/ICCV48922.2021.00909 |
| [21] |
Q. Ji, Y. Sun, J. Gao, Y. Hu, B. Yin, A decoder-free variational deep embedding for unsupervised clustering, IEEE Trans. Neural Networks Learn. Syst., 33 (2021), 5681–5693. https://doi.org/10.1109/TNNLS.2021.3071275 doi: 10.1109/TNNLS.2021.3071275
|
| [22] |
W. Wang, J. Bao, S. Guo, Neural generative model for clustering by separating particularity and commonality, Inf. Sci., 589 (2022), 813–826. https://doi.org/10.1016/j.ins.2021.12.037 doi: 10.1016/j.ins.2021.12.037
|
| [23] | J. Mirecka, M. Famili, A. Kota'nska, N. Juraschko, B. Costa-Gomes, C. Palmer, et al., Affinity-VAE for disentanglement, clustering and classification of objects in multidimensional image data, preprint, arXiv: 2209.04517. https://doi.org/10.48550/arXiv.2209.04517 |
| [24] | J. Xu, Y. Ren, H. Tang, X. Pu, X. Zhu, M. Zeng, et al., Multi-VAE: Learning disentangled view-common and view-peculiar visual representations for multi-view clustering, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 9234–9243. https://doi.org/10.1109/ICCV48922.2021.00910 |
| [25] | G. Chen, S. Long, Z. Yuan, W. Zhu, Q. Chen, Y. Wu, Ising granularity image analysis on VAE–GAN, Mach. Vision Appl., 33 (2022). https://doi.org/10.1007/s00138-022-01338-2 |
| [26] | E. Palumbo, S. Laguna, D. Chopard, J. E. Vog, Deep generative clustering with multimodal variational autoencoders, in ICML 2023 Workshop on Structured Probabilistic Inference & Generative Modeling, 2023. |
| [27] | L. Yang, C. Cheung, J. Li, J. Fang, Deep clustering by gaussian mixture variational autoencoders with graph embedding, in Proceedings of the AAAI Conference on Artificial Intelligence, (2019), 6440–6449. |
| [28] | Y. Liang, Z. Lin, F. Yuan, H. Zhang, L. Wang, W. Wang, Towards polymorphic adversarial examples generation for short text, in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023. https://doi.org/10.1109/ICASSP49357.2023.10095612 |
| [29] | K. Yonekura, Quantitative analysis of latent space in airfoil shape generation using variational autoencoders, Trans. JSME, 87 (2021). https://doi.org/10.1299/transjsme.21-00212 |
| [30] | T. Nishida, T. Endo, Y. Kawaguchi, Zero-Shot domain adaptation of anomalous samples for semi-supervised anomaly detection, in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023. https://doi.org/10.1109/ICASSP49357.2023.10095897 |
| [31] | D. Nat, A. M. M. Pedro, G. Marta, C. H. L. Matthew, H. Salimbeni, A. Kai, et al., Deep unsupervised clustering with gaussian mixture variational autoencoders, preprint, arXiv: 1611.02648. https://doi.org/10.48550/arXiv.1611.02648 |
| [32] | W. Wu, Y. Liu, M. Guo, Constructing training distribution by minimizing variance of risk criterion for visual category learning, in 2012 19th IEEE International Conference on Image Processing, (2012), 101–104. https//doi.org/10.1109/ICIP.2012.6466805 |
| [33] | W. Wu, Y. Liu, W. Zeng, M. Guo, C. Wang, X. Liu, Effective constructing training sets for object detection, in 2013 IEEE International Conference on Image Processing, (2013), 3377–3380. https//doi.org/10.1109/ICIP.2013.6738696 |
| [34] | Z. Jiang, Y. Zheng, H. Tan, B. Tang, H. Zhou, Variational deep embedding: An unsupervised and generative approach to clustering, preprint, arXiv: 1611.05148. https://doi.org/10.48550/arXiv.1611.05148 |
| [35] | W. Liu, Y. Zhang, X. Li, Z. Liu, B. Dai, T. Zhao, et al., Deep hyperspherical learning, Adv. Neural Inf. Process. Syst., 30 (2017). |
| [36] | Q. Li, W. Fan, Mixture density hyperspherical generative adversarial networks, in Proceedings of the 2022 6th International Conference on Innovation in Artificial Intelligence, (2022), 31–37. https://doi.org/10.1145/3529466.3529475 |
| [37] |
L. Yang, W. Fan, N. Bouguila, Deep clustering analysis via dual variational autoencoder with spherical latent embeddings, IEEE Trans. Neural Networks Learn. Syst., 34 (2021), 6303–6312. https://doi.org/10.1109/TNNLS.2021.3135460 doi: 10.1109/TNNLS.2021.3135460
|
| [38] |
W. Fan, H. Huang, C. Liang, X. Liu, S. Peng, Unsupervised meta-learning via spherical latent representations and dual VAE-GAN, Appl. Intell., 53 (2023), 22775–22788. https://doi.org/10.1007/s10489-023-04760-9 doi: 10.1007/s10489-023-04760-9
|
| [39] | S. Basu, A. Banerjee, R. Mooney, Active semi-supervision for pairwise constrained clustering, in Proceedings of the 2004 SIAM International Conference on Data Mining, (2004), 333–344. https://doi.org/10.1137/1.9781611972740.31 |
| [40] | K. Wagstaff, C. Cardie, S. Rogers, S. Schroedl, Constrained k-means clustering with background knowledge, in Proceedings of the Eighteenth International Conference on Machine Learning, 1 (2001), 577–584. |
| [41] | J. Goschenhofer, B. Bischl, Z. Kira, ConstraintMatch for semi-constrained clustering, in 2023 International Joint Conference on Neural Networks (IJCNN), (2023). https://doi.org/10.1109/IJCNN54540.2023.10191186 |
| [42] | L. Manduchi, K. Chin-Cheong, H. Michel, S. Wellmann, J. E. Vogt, Deep conditional gaussian mixture model for constrained clustering, Neural Inf. Process. Syst., 34 (2021), 11303–11314. |
| [43] |
S. E. Hajjar, F. Dornaika, F. Abdallah, Multi-view spectral clustering via constrained nonnegative embedding, Inf. Fusion, 78 (2021), 209–217. https://doi.org/10.1016/j.inffus.2021.09.009 doi: 10.1016/j.inffus.2021.09.009
|
| [44] |
J. Lv, Z. Kang, X. Lu, Z. Xu, Pseudo-Supervised deep subspace clustering, IEEE Trans. Image Process., 30 (2021), 5252–5263. https://doi.org/10.1109/TIP.2021.3079800 doi: 10.1109/TIP.2021.3079800
|
| [45] |
L. Bai, J. Liang, Y. Zhao, Self-Constrained spectral clustering, IEEE Trans. Pattern Anal. Mach. Intell., 45 (2022), 5126–5138. https://doi.org/10.1109/TPAMI.2022.3188160 doi: 10.1109/TPAMI.2022.3188160
|
| [46] |
C. Hinojosa, E. Vera, H. Arguello, A fast and accurate similarity-constrained subspace clustering algorithm for hyperspectral image, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 14 (2021), 10773–10783. https//doi.org/10.1109/JSTARS.2021.3120071 doi: 10.1109/JSTARS.2021.3120071
|






Figures(7) / Tables(2)
He Ma, Weipeng Wu. A deep clustering framework integrating pairwise constraints and a VMF mixture model[J]. Electronic Research Archive, 2024, 32(6): 3952-3972. doi: 10.3934/era.2024177







 DownLoad:
DownLoad: