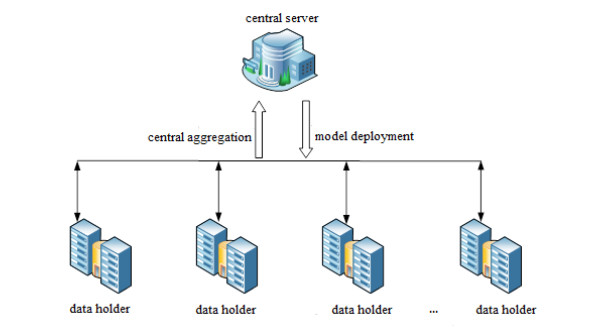
With the rapid progress of artificial intelligence (AI) technology in medical scenarios, it becomes a trend for medical services to adopt various AI algorithms for auxiliary diagnosis and health care of patients. However, medical data is often sensitive and possibly owned by multiple participants without the willingness of data sharing. To solve this problem under the vertical partition scenario of medical data, a differentially private distributed collaborative XGBoost method named DP-DCXGBoost was proposed and applied for disease classification in the paper. Initially, a reputation-based participant selection algorithm was designed, which evaluated the contribution of participants to the global model and used it for reputation calculation to select proper participants. Then, in the collaborative training phase, the proposed method utilized the local vertical dataset of each participant to calculate feature buckets and splitting gains in order to collaboratively construct a differentially private global XGBoost classification model. Finally, the experimental analysis for two real disease datasets showed that the proposed method had good classification accuracy on the basis of preserving participants' data privacy.
Citation: Xiongfei Li, Shuyu Li, Hao Xu, Yixuan Zhang. A differentially private distributed collaborative XGBoost method[J]. Electronic Research Archive, 2024, 32(4): 2865-2879. doi: 10.3934/era.2024130
With the rapid progress of artificial intelligence (AI) technology in medical scenarios, it becomes a trend for medical services to adopt various AI algorithms for auxiliary diagnosis and health care of patients. However, medical data is often sensitive and possibly owned by multiple participants without the willingness of data sharing. To solve this problem under the vertical partition scenario of medical data, a differentially private distributed collaborative XGBoost method named DP-DCXGBoost was proposed and applied for disease classification in the paper. Initially, a reputation-based participant selection algorithm was designed, which evaluated the contribution of participants to the global model and used it for reputation calculation to select proper participants. Then, in the collaborative training phase, the proposed method utilized the local vertical dataset of each participant to calculate feature buckets and splitting gains in order to collaboratively construct a differentially private global XGBoost classification model. Finally, the experimental analysis for two real disease datasets showed that the proposed method had good classification accuracy on the basis of preserving participants' data privacy.

| [1] |
C. Wang, C. Jiang, J. Wang, S. Shen, S. Guo, P. Zhang, Blockchain-aided network resource orchestration in intelligent internet of things, IEEE Int. Things J., 10 (2022), 6151–6163. https://doi.org/10.1109/JIOT.2022.3222911 doi: 10.1109/JIOT.2022.3222911

|
| [2] |
J. Lu, H. Liu, R. Jia, J. Wang, L. Sun, S. Wan, Towards personalized federated learning via group collaboration in IIoT, IEEE Trans. Ind. Inform., 19 (2023), 8923–8932. https://doi.org/10.1109/TII.2022.3223234 doi: 10.1109/TII.2022.3223234
|
| [3] |
G. Wu, L. Xie, H. Zhang, J. Wang, S. Shen, S. Yu, STSIR: An individual-group game-based model for disclosing virus spread in Social Internet of Things, J. Netw. Comput. Appl., 214 (2023), 103608. https://doi.org/10.1016/j.jnca.2023.103608 doi: 10.1016/j.jnca.2023.103608
|
| [4] |
A. Yaqoob, R. M. Aziz, N. K. Verma, P. Lalwani, A. Makrariya, P. Kumar, A review on nature-inspired algorithms for cancer disease prediction and classification, Mathematics, 11 (2023), 1081. https://doi.org/10.3390/math11051081 doi: 10.3390/math11051081
|
| [5] |
B. Dou, Z. Zhu, E. Merkurjev, L. Ke, L. Chen, J. Jiang, et al., Machine learning methods for small data challenges in molecular science, Chem. Rev., 123 (2023), 8736–8780. https://doi.org/10.1021/acs.chemrev.3c00189 doi: 10.1021/acs.chemrev.3c00189
|
| [6] |
N. Liu, X. Li, E. Qi, M. Xu, L. Li, B. Gao, A novel ensemble learning paradigm for medical diagnosis with imbalanced data, IEEE Access, 8 (2020), 171263–171280. https://doi.org/10.1109/ACCESS.2020.3014362 doi: 10.1109/ACCESS.2020.3014362
|
| [7] |
Y. Yang, H. Lv, N. Chen, A survey on ensemble learning under the era of deep learning, Artif. Intell. Rev., 56 (2023), 5545–5589. https://doi.org/10.1007/s10462-022-10283-5 doi: 10.1007/s10462-022-10283-5
|
| [8] | T. Nishio, R. Yonetani, Client selection for federated learning with heterogeneous resources in mobile edge, in ICC 2019-2019 IEEE international conference on communications (ICC), IEEE, (2019), 1–7. https://doi.org/10.1109/ICC.2019.8761315 |
| [9] |
J. Kang, Z. Xiong, D. Niyato, S. Xie, J. Zhang, Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory, IEEE Int. Things J., 6 (2019), 10700–10714. https://doi.org/10.1109/JIOT.2019.2940820 doi: 10.1109/JIOT.2019.2940820
|
| [10] | M. S. Wibawa, I. M. D. Maysanjaya, I. M. A. W. Putra, Boosted classifier and features selection for enhancing chronic kidney disease diagnose, in 2017 5th International Conference on Cyber and IT Service Management, IEEE, (2017), 1–6. https://doi.org/10.1109/CITSM.2017.8089245 |
| [11] |
Y. Yang, L. Wei, Y. Hu, Y. Wu, L. Hu, S. Nie, Classification of Parkinson's disease based on multi-modal features and stacking ensemble learning, J. Neurosci. Meth., 350 (2021), 109019. https://doi.org/10.1016/j.jneumeth.2020.109019 doi: 10.1016/j.jneumeth.2020.109019
|
| [12] |
T. R. Mahesh, V. Vinoth Kumar, V. Vivek, K. M. Karthick Raghunath, G. Sindhu Madhuri, Early predictive model for breast cancer classification using blended ensemble learning, Int. J. Syst. Assur. Eng. Manag., 15 (2024), 188–197. https://doi.org/10.1007/s13198-022-01696-0 doi: 10.1007/s13198-022-01696-0
|
| [13] |
S. Kannan, An automated clinical decision support system for predicting cardiovascular disease using ensemble learning approach, Concurr. Comp.—Pract. E., 34 (2022), e7007. https://doi.org/10.1002/cpe.7007 doi: 10.1002/cpe.7007
|
| [14] | C. Dwork, Differential privacy, in International Colloquium on Automata, Languages, and Programming, Springer, (2006), 1–12. https://doi.org/10.1007/11787006_1 |
| [15] | Q. Li, Z. Wu, Z. Wen, B. He, Privacy-preserving gradient boosting decision trees, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 784–791. https://doi.org/10.1609/aaai.v34i01.5422 |
| [16] | N. Chaudhary, V. Gupta, K. Sandhir, R. Gupta, S. Chhabra, A. K. Singh, Privacy preserving ensemble learning classification model for mental healthcare, in 2022 Seventh International Conference on Parallel, Distributed and Grid Computing (PDGC), IEEE, (2022), 513–518. https://doi.org/10.1109/PDGC56933.2022.10053268 |
| [17] |
X. Li, J. Liu, S. Liu, J. Wang, Differentially private ensemble learning for classification, Neurocomputing, 430 (2021), 34–46. https://doi.org/10.1016/j.neucom.2020.12.051 doi: 10.1016/j.neucom.2020.12.051
|
| [18] | Z. Tian, R. Zhang, X. Hou, J. Liu, K. Ren, Federboost: Private federated learning for gbdt, preprint, arXiv: 2011.02796. |
| [19] | L. Zhao, L. Ni, S. Hu, Y. Chen, P. Zhou, F. Xiao, et al., Inprivate digging: Enabling tree-based distributed data mining with differential privacy, in IEEE INFOCOM 2018—IEEE Conference on Computer Communications, IEEE, (2018), 2087–2095. https://doi.org/10.1109/INFOCOM.2018.8486352 |
| [20] | Cardiovascular Diseases Dataset (clean). Available from: https://www.kaggle.com/datasets/aiaiaidavid/cardio-data-dv13032020. |
| [21] | Diabetes 130-US Hospitals for Years 1999-2008, 2014, Available from: https://archive.ics.uci.edu/ml/datasets/Diabetes+130-US+Hospitals+For+Years+1999-2008. |
| [22] | X. Zhu, Research and Implementation of Differential Privacy Protection Technology under Federated Learning, Master thesis, Nanjing University of Posts and Telecommunications in Nanjing, 2021. https://doi.org/10.27251/d.cnki.gnjdc.2021.000896 |



Figures(4) / Tables(1)
Xiongfei Li, Shuyu Li, Hao Xu, Yixuan Zhang. A differentially private distributed collaborative XGBoost method[J]. Electronic Research Archive, 2024, 32(4): 2865-2879. doi: 10.3934/era.2024130







 DownLoad:
DownLoad: