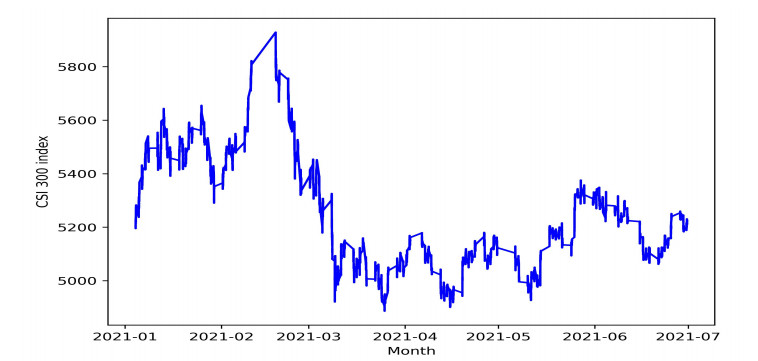
This paper models stochastic process of price time series of $ CSI $ $ 300 $ index in Chinese financial market, analyzes volatility characteristics of intraday high-frequency price data. In the new generalized Barndorff-Nielsen and Shephard model, the lag caused by asynchrony of market information and market microstructure noises are considered, and the problem of lack of long-term dependence is solved. To speed up the valuation process, several machine learning and deep learning algorithms are used to estimate parameter and evaluate forecast results. Tracking historical jumps of different magnitudes offers promising avenues for simulating dynamic price processes and predicting future jumps. Numerical results show that the deterministic component of stochastic volatility processes would always be captured over short and longer-term windows. Research finding could be suitable for influence investors and regulators interested in predicting market dynamics based on high-frequency realized volatility.
Citation: Xianfei Hui, Baiqing Sun, Indranil SenGupta, Yan Zhou, Hui Jiang. Stochastic volatility modeling of high-frequency CSI 300 index and dynamic jump prediction driven by machine learning[J]. Electronic Research Archive, 2023, 31(3): 1365-1386. doi: 10.3934/era.2023070
This paper models stochastic process of price time series of $ CSI $ $ 300 $ index in Chinese financial market, analyzes volatility characteristics of intraday high-frequency price data. In the new generalized Barndorff-Nielsen and Shephard model, the lag caused by asynchrony of market information and market microstructure noises are considered, and the problem of lack of long-term dependence is solved. To speed up the valuation process, several machine learning and deep learning algorithms are used to estimate parameter and evaluate forecast results. Tracking historical jumps of different magnitudes offers promising avenues for simulating dynamic price processes and predicting future jumps. Numerical results show that the deterministic component of stochastic volatility processes would always be captured over short and longer-term windows. Research finding could be suitable for influence investors and regulators interested in predicting market dynamics based on high-frequency realized volatility.

| [1] |
C. T. Albulescu, COVID-19 and the United States financial markets' volatility, Finance Res. Lett., 38 (2021), 101699. https://doi.org/10.1016/j.frl.2020.101699 doi: 10.1016/j.frl.2020.101699

|
| [2] |
S. Corbet, Y. G. Hou, Y. Hu, L. Oxley, D. Xu, Pandemic-related financial market volatility spillovers: Evidence from the Chinese COVID-19 epicentre, Int. Rev. Econ. Finance, 71 (2021), 55–81. https://doi.org/10.1016/j.iref.2020.06.022 doi: 10.1016/j.iref.2020.06.022
|
| [3] |
J. Danielsson, M. Valenzuela, I. Zer, Learning from history: Volatility and financial crises, Rev. Financ. Stud., 31 (2018), 2774–2805. https://doi.org/10.1093/rfs/hhy049 doi: 10.1093/rfs/hhy049
|
| [4] |
X. He, W. Chen, A closed-form pricing formula for european options under a new stochastic volatility model with a stochastic long-term mean, Math. Financ. Econ., 15 (2021), 381–396. https://doi.org/10.1007/s11579-020-00281-y doi: 10.1007/s11579-020-00281-y
|
| [5] |
M. Chauvet, Z. Senyuz, E. Yoldas, What does financial volatility tell us about macroeconomic fluctuations, J. Econ. Dyn. Control, 52 (2015), 340–360. https://doi.org/10.1016/j.jedc.2015.01.002 doi: 10.1016/j.jedc.2015.01.002
|
| [6] |
C. Arellano, Y. Bai, P. J. Kehoe, Financial frictions and fluctuations in volatility, J. Polit. Econ., 127 (2019), 2049–2103. https://doi.org/10.1086/701792 doi: 10.1086/701792
|
| [7] |
M. Lin, I. SenGupta, Analysis of optimal portfolio on finite and small-time horizons for a stochastic volatility market model, SIAM J. Financ. Math., 12 (2021), 1596–1624. https://doi.org/10.1137/21M1412281 doi: 10.1137/21M1412281
|
| [8] |
F. Caselli, M. Koren, M. Lisicky, S. Tenreyro, Diversification through trade, Q. J. Econ., 135 (2020), 449–502. https://doi.org/10.1093/qje/qjz028 doi: 10.1093/qje/qjz028
|
| [9] |
X. He, S. Lin, A new nonlinear stochastic volatility model with regime switching stochastic mean reversion and its applications to option pricing, Expert Syst. Appl., 212 (2023), 118742. https://doi.org/10.1016/j.eswa.2022.118742 doi: 10.1016/j.eswa.2022.118742
|
| [10] |
X. He, S. Lin, A fractional black-scholes model with stochastic volatility and european option pricing, Expert Syst. Appl., 178 (2021), 114983. https://doi.org/10.1016/j.eswa.2021.114983 doi: 10.1016/j.eswa.2021.114983
|
| [11] |
X. He, C. Wnting, Pricing foreign exchange options under a hybrid heston-coxingersoll-ross model with regime switching, IMA J. Manage. Math., 33 (2022), 255–272. https://doi.org/10.1093/imaman/dpab013 doi: 10.1093/imaman/dpab013
|
| [12] |
H. K. Baker, S. Kumar, K. Goyal, A. Sharma, International review of financial analysis: A retrospective evaluation between 1992 and 2020, Int. Rev. Financ. Anal., 78 (2021), 101946. http://doi.org/10.1016/j.irfa.2021.101946 doi: 10.1016/j.irfa.2021.101946
|
| [13] |
J. Baruník, T. Křehlík, Combining high frequency data with non-linear models for forecasting energy market volatility, Expert Syst. Appl., 55 (2016), 222–242. https://doi.org/10.1016/j.eswa.2016.02.008 doi: 10.1016/j.eswa.2016.02.008
|
| [14] |
A. Dutta, E. Bouri, D. Roubaud, Modelling the volatility of crude oil returns: Jumps and volatility forecasts, Int. J. Finance Econ., 26 (2021), 889–897. https://doi.org/10.1002/ijfe.1826 doi: 10.1002/ijfe.1826
|
| [15] |
J. Jacod, Y. Li, X. Zheng, Statistical properties of microstructure noise, Econometrica, 85 (2017), 1133–1174. https://doi.org/10.3982/ECTA13085 doi: 10.3982/ECTA13085
|
| [16] |
O. E. Barndorff-Nielsen, N. Shephard, Power and bipower variation with stochastic volatility and jumps, J. Financ. Econom., 2 (2004), 1–37. https://doi.org/10.1093/jjfinec/nbh001 doi: 10.1093/jjfinec/nbh001
|
| [17] |
O. E. Barndorff-Nielsen, Superposition of ornstein–uhlenbeck type processes, Theory Probab. Appl., 45 (2001), 175–194. https://doi.org/10.1137/S0040585X97978166 doi: 10.1137/S0040585X97978166
|
| [18] |
M. Roberts, I. Sengupta, Sequential hypothesis testing in machine learning, and crude oil price jump size detection, Appl. Math. Finance, 27 (2020), 374–395. https://doi.org/10.1080/1350486X.2020.1859943 doi: 10.1080/1350486X.2020.1859943
|
| [19] |
I. Sengupta, Generalized BN-S stochastic volatility model for option pricing, Int. J. Theor. Appl. Finance, 19 (2016), 1650014. https://doi.org/10.1142/S021902491650014X doi: 10.1142/S021902491650014X
|
| [20] |
I. SenGupta, W. Wilson, W. Nganje, Barndorff-nielsen and shephard model: oil hedging with variance swap and option, Math. Financ. Econ., 13 (2019), 209–226. https://doi.org/10.1007/s11579-018-0225-4 doi: 10.1007/s11579-018-0225-4
|
| [21] |
M. Roberts, I. SenGupta, Infinitesimal generators for two-dimensional Lévy process-driven hypothesis testing, Ann. Finance, 16 (2020), 121–139. https://doi.org/10.1007/s10436-019-00355-y doi: 10.1007/s10436-019-00355-y
|
| [22] | I. SenGupta, Pricing asian options in financial markets using mellin transforms, Electron. J. Differ. Equations, 234 (2014), 1–9. |
| [23] |
T. Arai, Y. Imai, R. Suzuki, Local risk-minimization for barndorff-nielsen and shephard models, Finance Stochastics, 21 (2017), 551–592. https://doi.org/10.1007/s00780-017-0324-8 doi: 10.1007/s00780-017-0324-8
|
| [24] |
S. Mullainathan, J. Spiess, Machine learning: an applied econometric approach, J. Econ. Perspect., 31 (2017), 87–106. https://doi.org/10.1257/jep.31.2.87 doi: 10.1257/jep.31.2.87
|
| [25] |
Y. Qian, K. Zhang, J. Li, X. Wang, Adaptive neural network surrogate model for solving the implied volatility of time-dependent american option via bayesian inference, Electron. Res. Arch., 30 (2022), 2335–2355. https://doi.org/10.3934/era.2022119 doi: 10.3934/era.2022119
|
| [26] |
B. M. Henrique, V. A. Sobreiro, H. Kimura, Literature review: Machine learning techniques applied to financial market prediction, Expert Syst. Appl., 124 (2019), 226–251. https://doi.org/10.1016/j.eswa.2019.01.012 doi: 10.1016/j.eswa.2019.01.012
|
| [27] |
S. A. Monfared, D. Enke, Volatility forecasting using a hybrid gjr-garch neural network model, Procedia Comput. Sci., 36 (2014), 246–253. https://doi.org/10.1016/j.procs.2014.09.087 doi: 10.1016/j.procs.2014.09.087
|
| [28] |
J. Zheng, X. Fu, G. Zhang, Research on exchange rate forecasting based on deep belief network, Neural Comput. Appl., 31 (2019), 573–582. https://doi.org/10.1007/s00521-017-3039-z doi: 10.1007/s00521-017-3039-z
|
| [29] |
Y. Liu, Novel volatility forecasting using deep learning–long short term memory recurrent neural networks, Expert Syst. Appl., 132 (2019), 99–109. https://doi.org/10.1016/j.eswa.2019.04.038 doi: 10.1016/j.eswa.2019.04.038
|
| [30] |
T. Fischer, C. Krauss, Deep learning with long short-term memory networks for financial market predictions, Eur. J. Oper. Res., 270 (2018), 654–669. https://doi.org/10.1016/j.ejor.2017.11.054 doi: 10.1016/j.ejor.2017.11.054
|
| [31] |
H. Zhou, P. S. Kalev, Algorithmic and high frequency trading in asia-pacific, now and the future, Pac. Basin Finance J., 53 (2019), 186–207. https://doi.org/10.1016/j.pacfin.2018.10.006 doi: 10.1016/j.pacfin.2018.10.006
|
| [32] |
N. Todorova, M. Souček, Overnight information flow and realized volatility forecasting, Finance Res. Lett., 11 (2014), 420–428. https://doi.org/10.1016/j.frl.2014.07.001 doi: 10.1016/j.frl.2014.07.001
|
| [33] |
I. SenGupta, W. Nganje, E. Hanson, Refinements of barndorff-nielsen and shephard model: an analysis of crude oil price with machine learning, Ann. Data Sci., 8 (2021), 39–55. https://doi.org/10.1007/s40745-020-00256-2 doi: 10.1007/s40745-020-00256-2
|
| [34] |
K. Grobys, When the blockchain does not block: on hackings and uncertainty in the cryptocurrency market, Quant. Finance, 54 (2020), 1267–1279. https://doi.org/10.1080/14697688.2020.1849779 doi: 10.1080/14697688.2020.1849779
|
| [35] |
D. Xiao, J. Wang, Dynamic complexity and causality of crude oil and major stock markets, Energy, 193 (2020), 116791. https://doi.org/10.1016/j.energy.2019.116791 doi: 10.1016/j.energy.2019.116791
|
| [36] |
S. Habtemicael, M. Ghebremichael, I. SenGupta, Volatility and variance swap using superposition of the barndorff-nielsen and shephard type Lévy processes, Sankhya B, 81 (2019), 75–92. https://doi.org/10.1007/s13571-017-0145-y doi: 10.1007/s13571-017-0145-y
|
| [37] |
T. G. Andersen, T. Bollerslev, F. X. Diebold, P. Labys, Modeling and forecasting realized volatility, Econometrica, 71 (2003), 579–625. https://doi.org/10.1111/1468-0262.00418 doi: 10.1111/1468-0262.00418
|






Figures(7) / Tables(6)
Xianfei Hui, Baiqing Sun, Indranil SenGupta, Yan Zhou, Hui Jiang. Stochastic volatility modeling of high-frequency CSI 300 index and dynamic jump prediction driven by machine learning[J]. Electronic Research Archive, 2023, 31(3): 1365-1386. doi: 10.3934/era.2023070







 DownLoad:
DownLoad: