Citation: Yonghong Zhong, Richard I.D. Harris, Shuhong Deng. The spillover effects among offshore and onshore RMB exchange rate markets, RMB Hibor market[J]. Quantitative Finance and Economics, 2020, 4(2): 294-309. doi: 10.3934/QFE.2020014

| [1] |
Bai J, Perron P (1998) Estimating and testing linear models with multiple structural changes. Econometrica: 47-78. doi: 10.2307/2998540

|
| [2] |
Chen L, Du Z, Tan Y (2019) Sustainable exchange rates in China: Is there the heterogeneous effect of economic policy uncertainty? Green Financ 1: 346-363. doi: 10.3934/GF.2019.4.346
|
| [3] |
Cheung YW, Rime D (2014) The offshore renminbi exchange rate: Microstructure and links to the onshore market. J Int Money Financ 49: 170-189. doi: 10.1016/j.jimonfin.2014.05.012
|
| [4] |
Engle RF, Kroner KF (1995) Multivariate Simultaneous Generalized ARCH. Econometric Theor 11: 122-150. doi: 10.1017/S0266466600009063
|
| [5] |
Fatum R, Pedersen J, Sørensen PN (2013) The intraday effects of central bank intervention on exchange rate spreads. J Int Money Financ 33: 103-117. doi: 10.1016/j.jimonfin.2012.10.006
|
| [6] |
Funke M, Shu C, Cheng X, et al. (2015) Assessing the CNH-CNY pricing differential: Role of fundamentals, contagion and policy. J Int Money Financ 59: 245-262. doi: 10.1016/j.jimonfin.2015.07.008
|
| [7] | HKEX (2017) The Liquidity Provision Mechanism for Offshore RMB Market-Current Status, Impact and Possible Improvements. Research Report, No. 2017, Hong Kong Exchanges and Clearing Limited, Hong Kong. |
| [8] |
Hung-Gay F, Leung WK, Jiang ZHU (2004) Nondeliverable forward market for Chinese RMB: A first look. China Economic Rev 15: 348-352. doi: 10.1016/j.chieco.2004.03.004
|
| [9] | Kou C, Kong L (2014) The Effect of CNH Market on Relationship of RMB Spot Exchange Rate and NDF. In Proceedings of the Seventh International Conference on Management Science and Engineering Management, ed. Xu J., Fry J., and Lev B., Hajiyev, 1387-1394. Berlin Heidelberg: Springer. |
| [10] | Leung D, Fu J (2014) Interactions between CNY and CNH Money and Forward Exchange Markets. Working Papers No. 13/2014, Hong Kong Institute for Monetary Research, Hong Kong. |
| [11] |
Li Z, Dong H, Huang Z, et al. (2018) Asymmetric effects on risks of Virtual Financial Assets (VFAs) in different regimes: A Case of Bitcoin. Quant Financ Econ 2: 860-883. doi: 10.3934/QFE.2018.4.860
|
| [12] | Li Z, Liao G, Albitar K (2019) Does corporate environmental responsibility engagement affect firm value? The mediating role of corporate innovation. Bus Strateg Environ, [in press]. |
| [13] | Li Z, Zhong J (2019) Impact of economic policy uncertainty shocks on China's financial conditions. Financ Res Lett, [in press]. |
| [14] |
Liang Y, Shi K, Wang L, et al. (2019) Fluctuation and reform: A tale of two RMB markets. China Economic Rev 53: 30-52. doi: 10.1016/j.chieco.2018.08.003
|
| [15] | Maziad S, Kang JS (2012) RMB Internationalization: Onshore/Offshore Links. Working paper No. 12-133, International Monetary Fund, Washington DC. |
| [16] |
McKinnon R, Schnabl G (2009) The case for stabilizing China's exchange rate: Setting the stage for fiscal expansion. China World Econ 17: 1-32. doi: 10.1111/j.1749-124X.2009.01128.x
|
| [17] |
Owyong D, Wong WK, Horowitz I (2015) Cointegration and Causality among the Onshore and Offshore Markets for China's Currency. J Asian Econ 41: 20-38. doi: 10.1016/j.asieco.2015.10.004
|
| [18] |
Peng W, Shu C, Yip R (2007) Renminbi derivatives: recent development and issues. China World Econ 15: 1-17. doi: 10.1111/j.1749-124X.2007.00082.x
|
| [19] |
Schwarz G (1978) Estimating the Dimension of a Model. Ann Stat 6: 461-464. doi: 10.1214/aos/1176344136
|
| [20] | Shen J (2014) The Price Discovery and Volatility Spillover Effects of RMB Exchange Rates between Onshore and Offshore Markets. Shanghai Financ 405: 84-86. (in Chinese). |
| [21] |
Shibata R (1976) Selection of the Order of an Autoregressive Model by Akaike's Information Criterion. Biometrika 63: 117-126. doi: 10.1093/biomet/63.1.117
|
| [22] |
Takaishi T (2018) Volatility Estimation Using A Rational GARCH Model. Quant Financ Econ 2: 127-136. doi: 10.3934/QFE.2018.1.127
|
| [23] | Wu G, Pei C (2012) The Quantitative Study of Onshore and Offshore Exchange Rate. J Financ Res 387: 62-73. (in Chinese). |
| [24] | Wu Z, Chen X (2013) Dynamic Correlation of RMB Exchange Rate between Onshore and Offshore Market Based on MGARCH-BEKK Model-Evidence from Hong Kong Offshore RMB Market after Its Establishment. Forum World Econ Polit 261: 110-123. (in Chinese). |
| [25] |
Xu HC, Zhou WX, Sornette D (2017) Time-dependent lead-lag relationship between the onshore and offshore Renminbi exchange rates. J Int Financ Markets Inst Money 49: 173-183. doi: 10.1016/j.intfin.2017.05.001
|
| [26] | Yan J, Sun L, Huang W (2015) The Linkage Effects of Interest Rate and Exchange Rate in Hong Kong RMB Offshore Market. Financ Forum 236: 57-65. (in Chinese). |
| [27] |
Yang J, Leatham DJ (2001) Currency Convertibility and Linkage between Chinese Official and Swap Market Exchange Rates. Contem Econ Pol 19: 347-359. doi: 10.1093/cep/19.3.347
|
| [28] | Zhou J (2005) The Researches on the Test Power and Features on the Lagging Number Selecting Criteria about the Time Series Models. Sys Engin Theor Pract 24: 22-29. (in Chinese). |
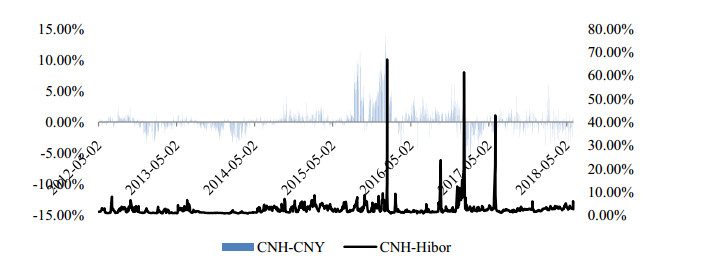


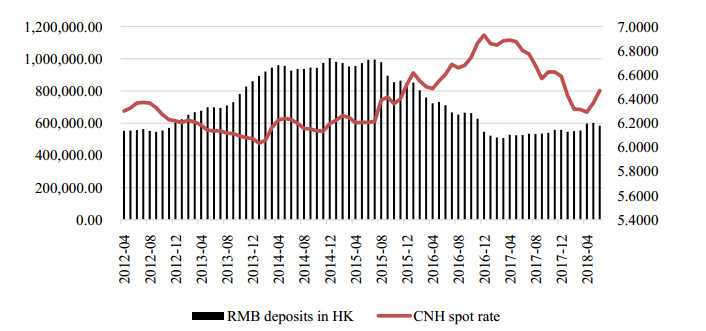
Figures(4) / Tables(6)

Yonghong Zhong, Richard I.D. Harris, Shuhong Deng. The spillover effects among offshore and onshore RMB exchange rate markets, RMB Hibor market[J]. Quantitative Finance and Economics, 2020, 4(2): 294-309. doi: 10.3934/QFE.2020014







 DownLoad:
DownLoad: