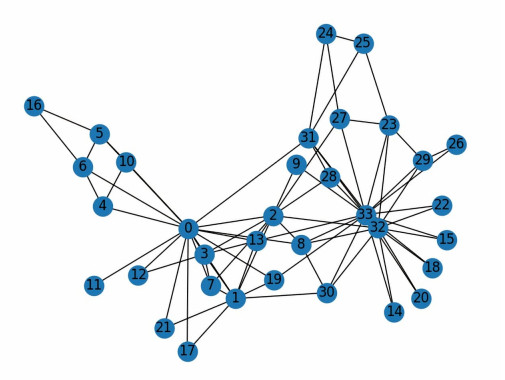
Due to the advent of the expressions of data other than tabular formats, the topological compositions which make samples interrelated came into prominence. Analogically, those networks can be interpreted as social connections, dataflow maps, citation influence graphs, protein bindings, etc. However, in the case of social networks, it is highly crucial to evaluate the labels of discrete communities. The reason for such a study is the importance of analyzing graph networks to partition the vertices by only using the topological features of network graphs. For each interaction-based entity, a social graph, a mailing dataset, and two citation sets are selected as the testbench repositories. The research mainly focused on evaluating the significance of three artificial intelligence approaches on four different datasets consisting of vertices and edges. Overall, one of these methods so-called "harmonic functions", resulted in the best form to classify those constituents of graph-shaped datasets. This research not only accessed the most valuable method but also determined how graph neural networks work and the need to improve against non-neural network approaches which are faster and computationally cost-effective. Also in this paper, we will show that there is a limit to be accessed by prospective graph neural network variations by using the topological features of trialed networks.
Citation: Hacı İsmail Aslan, Hoon Ko, Chang Choi. Classification of vertices on social networks by multiple approaches[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12146-12159. doi: 10.3934/mbe.2022565
Due to the advent of the expressions of data other than tabular formats, the topological compositions which make samples interrelated came into prominence. Analogically, those networks can be interpreted as social connections, dataflow maps, citation influence graphs, protein bindings, etc. However, in the case of social networks, it is highly crucial to evaluate the labels of discrete communities. The reason for such a study is the importance of analyzing graph networks to partition the vertices by only using the topological features of network graphs. For each interaction-based entity, a social graph, a mailing dataset, and two citation sets are selected as the testbench repositories. The research mainly focused on evaluating the significance of three artificial intelligence approaches on four different datasets consisting of vertices and edges. Overall, one of these methods so-called "harmonic functions", resulted in the best form to classify those constituents of graph-shaped datasets. This research not only accessed the most valuable method but also determined how graph neural networks work and the need to improve against non-neural network approaches which are faster and computationally cost-effective. Also in this paper, we will show that there is a limit to be accessed by prospective graph neural network variations by using the topological features of trialed networks.

| [1] |
A. Hogan, E. Blomqvist, M. Cochez, C. D'amato, G. De Melo, C. Gutierrez, et al., Knowledge graphs, ACM Comput. Surv., 54 (2022), 1–37. https://doi.org/10.1145/3447772 doi: 10.1145/3447772

|
| [2] |
M. M. Bronstein, J. Bruna, Y. LeCun, A. Szlam, P. Vandergheynst, Geometric deep learning: going beyond euclidean data, IEEE Signal Process Mag., 34 (2017), 18–42. https://doi.org/10.1109/MSP.2017.2693418 doi: 10.1109/MSP.2017.2693418
|
| [3] |
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, P. S. Yu, A comprehensive survey on graph neural networks, IEEE Trans. Neural Networks Learn. Syst., 32 (2021), 4–24. https://doi.org/10.1109/TNNLS.2020.2978386 doi: 10.1109/TNNLS.2020.2978386
|
| [4] |
S. Kearnes, K. McCloskey, M. Berndl, V. Pande, P. Riley, Molecular graph convolutions: moving beyond fingerprints, J. Comput.-Aided Mol. Des., 30 (2016), 595–608. https://doi.org/10.1007/s10822-016-9938-8 doi: 10.1007/s10822-016-9938-8
|
| [5] | A. Fout, J. Byrd, B. Shariat, A. Ben-Hur, Protein interface prediction using graph convolutional networks, in Advances in Neural Information Processing Systems, 30 (2017), 6533–6542. Available from: https://proceedings.neurips.cc/paper/2017/file/f507783927f2ec2737ba40afbd17efb5-Paper.pdf. |
| [6] | E. Choi, Z. Xu, Y. Li, M. Dusenberry, G. Flores, E. Xue, et al., Learning the graphical structure of electronic health records with graph convolutional transformer, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 606–613. https://doi.org/10.1609/aaai.v34i01.5400 |
| [7] | M. Zhang, Y. Chen, Link prediction based on graph neural networks, in Advances in Neural Information Processing Systems, 31 (2018), 5171–5181. Available from: https://proceedings.neurips.cc/paper/2018/file/53f0d7c537d99b3824f0f99d62ea2428-Paper.pdf. |
| [8] | C. Li, D. Goldwasser, Encoding social information with graph convolutional networks forPolitical perspective detection in news media, in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019 (2019), 2594–2604. https://doi.org/10.18653/v1/P19-1247 |
| [9] | T. Bian, X. Xiao, T. Xu, P. Zhao, W. Huang, Y. Rong, et al., Rumor detection on social media with Bi-directional graph convolutional networks, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 549–556. https://doi.org/10.1609/aaai.v34i01.5393 |
| [10] | M. Schlichtkrull, T. N. Kipf, P. Bloem, R. van den Berg, I. Titov, M. Welling, Modeling relational data with graph convolutional networks, in The Semantic Web, (2018), 593–607. https://doi.org/10.1007/978-3-319-93417-4_38. |
| [11] | N. Park, A. Kan, X. L. Dong, T. Zhao, C. Faloutsos, Estimating node importance in knowledge graphs using graph neural networks, in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, (2019), 596–606. https://doi.org/10.1145/3292500.3330855 |
| [12] |
Z. Cui, K. Henrickson, R. Ke, Y. Wang, Traffic graph convolutional recurrent neural network: a deep learning framework for network-scale traffic learning and forecasting, IEEE Trans. Intell. Transp. Syst., 21 (2020), 4883–4894. https://doi.org/10.1109/TITS.2019.2950416 doi: 10.1109/TITS.2019.2950416
|
| [13] | H. Wu, L. Cheng, J. Jin, F. Yuan, Dialog acts classification with semantic and structural information, in 2019 International Conference on Intelligent Computing, Automation and Systems (ICICAS), (2019), 438–442. https://doi.org/10.1109/ICICAS48597.2019.00098 |
| [14] | Y. T. Lin, M. T. Wu, K. Y. Su, Syntax-aware natural language inference with graph matching networks, in 2020 International Conference on Technologies and Applications of Artificial Intelligence (TAAI), (2020), 85–90. https://doi.org/10.1109/TAAI51410.2020.00024 |
| [15] | Z. Wang, H. Chang, 3D mesh deformation using graph convolution network, in 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS), (2019), 375–378. https://doi.org/10.1109/CCOMS.2019.8821790 |
| [16] | P. Pradhyumna, G. P. Shreya, Mohana, Graph Neural Network (GNN) in image and video understanding using deep learning for computer vision applications, in 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), (2021), 1183–1189. https://doi.org/10.1109/ICESC51422.2021.9532631 |
| [17] |
S. Zhang, H. Tong, J. Xu, R. Maciejewski, Graph convolutional networks: a comprehensive review, Comput. Social Networks, 6 (2019), 11. https://doi.org/10.1186/s40649-019-0069-y doi: 10.1186/s40649-019-0069-y
|
| [18] | W. Hamilton, Z. Ying, J. Leskovec, Inductive representation learning on large graphs, in Advances in Neural Information Processing Systems, 30 (2017). Available from: https://proceedings.neurips.cc/paper/2017/file/5dd9db5e033da9c6fb5ba83c7a7ebea9-Paper.pdf. |
| [19] | J. Gasteiger, A. Bojchevski, S. Günnemann, Predict then propagate: graph neural networks meet personalized pageRank, preprint, arXiv: 1810.05997. |
| [20] | L. Page, S. Brin, R. Motwani, T. Winograd, The pageRank citation ranking: bringing order to the web, 1999. Available from: http://ilpubs.stanford.edu:8090/422/. |
| [21] | F. Wu, A. Souza, T. Zhang, C. Fifty, T. Yu, K. Weinberger, Simplifying graph convolutional networks, in Proceedings of the 36th International Conference on Machine Learning, 97 (2019), 6861–6871. Available from: https://proceedings.mlr.press/v97/wu19e.html. |
| [22] | P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, Y. Bengio, Graph attention networks, preprint, arXiv: 1710.10903. |
| [23] | P. Veličković, W. Fedus, W. L. Hamilton, P. Liò, Y. Bengio, R. D. Hjelm, Deep graph infomax, preprint, arXiv: 1809.10341. |
| [24] | G. Nikolentzos, M. Vazirgiannis, Random walk graph neural networks, in Advances in Neural Information Processing Systems, 33 (2020), 16211–16222. Available from: https://proceedings.neurips.cc/paper/2020/file/ba95d78a7c942571185308775a97a3a0-Paper.pdf. |
| [25] | B. Nica, A brief introduction to spectral graph theory, 2016. Available from: https://arXiv.org/pdf/1609.08072.pdf. |
| [26] |
I. Benjamini, L. Lovász, Harmonic and analytic functions on graphs, J. Geom., 76 (2003), 3–15. https://doi.org/10.1007/s00022-033-1697-8 doi: 10.1007/s00022-033-1697-8
|
| [27] |
W. W. Zachary, An information flow model for conflict and fission in small groups, J. Anthropol. Res., 33 (1977), 452–473. https://doi.org/10.1086/jar.33.4.3629752 doi: 10.1086/jar.33.4.3629752
|
| [28] | J. Leskovec, A. Krevl, SNAP datasets: Stanford Large Network Dataset Collection, 2014. Available from: http://snap.stanford.edu/data. |
| [29] |
A. Bharali, An analysis of Email-Eu-Core network, Int. J. Sci. Res. Math. Stat. Sci., 5 (2018), 100–104. https://doi.org/10.26438/ijsrmss/v5i4.100104 doi: 10.26438/ijsrmss/v5i4.100104
|
| [30] |
D. Grattarola, C. Alippi, Graph neural networks in TensorFlow and Keras with Spektral, IEEE Comput. Intell. Mag., 16 (2021), 99–106. https://doi.org/10.1109/MCI.2020.3039072 doi: 10.1109/MCI.2020.3039072
|
| [31] | T. N. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks, preprint, arXiv: 1609.02907. |
| [32] |
F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, G. Monfardini, The graph neural network model, IEEE Trans. Neural Networks, 20 (2009), 61–80. https://doi.org/10.1109/TNN.2008.2005605 doi: 10.1109/TNN.2008.2005605
|
| [33] | X. Zhu, Z. Ghahramani, J. D. Lafferty, Semi-supervised learning using Gaussian fields and harmonic functions, in Proceedings of the Twentieth International Conference on Machine Learning, (2003), 912–919. Available from: https://dl.acm.org/doi/10.5555/3041838.3041953. |
| [34] | A. Hagberg, D. S. Chult, P. J. Swart, Exploring network structure, dynamics, and function using networkx, in Proceedings of the 7th Python in Science conference (SciPy 2008), (2008), 11–15. Available from: https://conference.scipy.org/proceedings/scipy2008/paper_2/. |
| [35] | L. He, C. T. Lu, J. Ma, J. Cao, L. Shen, P. S. Yu, Joint community and structural hole spanner detection via harmonic modularity, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2016), 875–884. https://doi.org/10.1145/2939672.2939807 |
| [36] | S. Luan, C. Hua, Q. Lu, J. Zhu, M. Zhao, S. Zhang, et al., Is heterophily a real nightmare for graph neural networks to do node classification? preprint, arXiv: 2109.05641. |
| [37] |
Q. Yao, R. Y. M. Li, L. Song, Construction safety knowledge sharing on YouTube from 2007 to 2021: Two-step flow theory and semantic analysis, Saf. Sci., 153 (2022), 105796. https://doi.org/10.1016/j.ssci.2022.105796 doi: 10.1016/j.ssci.2022.105796
|
| [38] |
Q. Yao, R. Y. M. Li, L. Song, M. J. C. Crabbe, Construction safety knowledge sharing on Twitter: a social network analysis, Saf. Sci., 143 (2021), 105411. https://doi.org/10.1016/j.ssci.2021.105411 doi: 10.1016/j.ssci.2021.105411
|


Figures(3) / Tables(3)

Hacı İsmail Aslan, Hoon Ko, Chang Choi. Classification of vertices on social networks by multiple approaches[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12146-12159. doi: 10.3934/mbe.2022565







 DownLoad:
DownLoad: