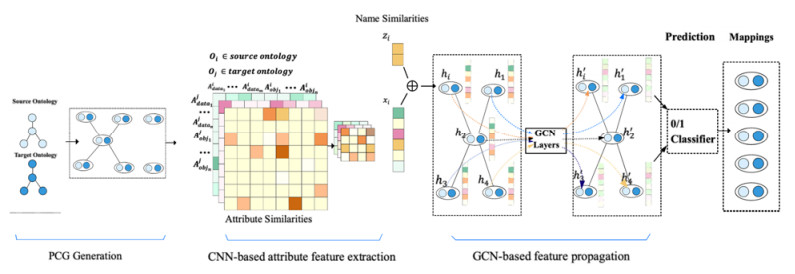
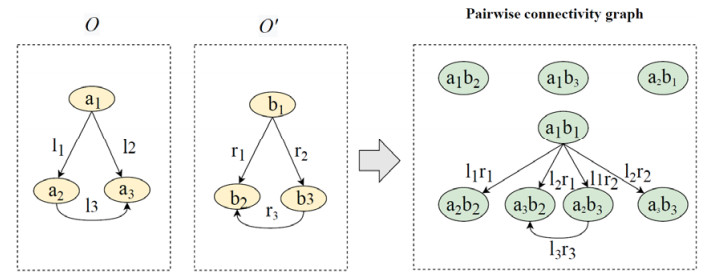
With an increasing number of biomedical ontologies being evolved independently, matching these ontologies to solve the interoperability problem has become a critical issue in biomedical applications. Traditional biomedical ontology matching methods are mostly based on rules or similarities for concepts and properties. These approaches require manually designed rules that not only fail to address the heterogeneity of domain ontology terminology and the ambiguity of multiple meanings of words, but also make it difficult to capture structural information in ontologies that contain a large amount of semantics during matching. Recently, various knowledge graph (KG) embedding techniques utilizing deep learning methods to deal with the heterogeneity in knowledge graphs (KGs), have quickly gained massive attention. However, KG embedding focuses mainly on entity alignment (EA). EA tasks and ontology matching (OM) tasks differ dramatically in terms of matching elements, semantic information and application scenarios, etc., hence these methods cannot be applied directly to biomedical ontologies that contain abstract concepts but almost no entities. To tackle these issues, this paper proposes a novel approach called BioOntGCN that directly learns embeddings of ontology-pairs for biomedical ontology matching. Specifically, we first generate a pair-wise connectivity graph (PCG) of two ontologies, whose nodes are concept-pairs and edges correspond to property-pairs. Subsequently, we learn node embeddings of the PCG to predicate the matching results through following phases: 1) A convolutional neural network (CNN) to extract the similarity feature vectors of nodes; 2) A graph convolutional network (GCN) to propagate the similarity features and obtain the final embeddings of concept-pairs. Consequently, the biomedical ontology matching problem is transformed into a binary classification problem. We conduct systematic experiments on real-world biomedical ontologies in Ontology Alignment Evaluation Initiative (OAEI), and the results show that our approach significantly outperforms other entity alignment methods and achieves state-of-the-art performance. This indicates that BioOntGCN is more applicable to ontology matching than the EA method. At the same time, BioOntGCN substantially achieves superior performance compared with previous ontology matching (OM) systems, which suggests that BioOntGCN based on the representation learning is more effective than the traditional approaches.
Citation: Peng Wang, Shiyi Zou, Jiajun Liu, Wenjun Ke. Matching biomedical ontologies with GCN-based feature propagation[J]. Mathematical Biosciences and Engineering, 2022, 19(8): 8479-8504. doi: 10.3934/mbe.2022394
With an increasing number of biomedical ontologies being evolved independently, matching these ontologies to solve the interoperability problem has become a critical issue in biomedical applications. Traditional biomedical ontology matching methods are mostly based on rules or similarities for concepts and properties. These approaches require manually designed rules that not only fail to address the heterogeneity of domain ontology terminology and the ambiguity of multiple meanings of words, but also make it difficult to capture structural information in ontologies that contain a large amount of semantics during matching. Recently, various knowledge graph (KG) embedding techniques utilizing deep learning methods to deal with the heterogeneity in knowledge graphs (KGs), have quickly gained massive attention. However, KG embedding focuses mainly on entity alignment (EA). EA tasks and ontology matching (OM) tasks differ dramatically in terms of matching elements, semantic information and application scenarios, etc., hence these methods cannot be applied directly to biomedical ontologies that contain abstract concepts but almost no entities. To tackle these issues, this paper proposes a novel approach called BioOntGCN that directly learns embeddings of ontology-pairs for biomedical ontology matching. Specifically, we first generate a pair-wise connectivity graph (PCG) of two ontologies, whose nodes are concept-pairs and edges correspond to property-pairs. Subsequently, we learn node embeddings of the PCG to predicate the matching results through following phases: 1) A convolutional neural network (CNN) to extract the similarity feature vectors of nodes; 2) A graph convolutional network (GCN) to propagate the similarity features and obtain the final embeddings of concept-pairs. Consequently, the biomedical ontology matching problem is transformed into a binary classification problem. We conduct systematic experiments on real-world biomedical ontologies in Ontology Alignment Evaluation Initiative (OAEI), and the results show that our approach significantly outperforms other entity alignment methods and achieves state-of-the-art performance. This indicates that BioOntGCN is more applicable to ontology matching than the EA method. At the same time, BioOntGCN substantially achieves superior performance compared with previous ontology matching (OM) systems, which suggests that BioOntGCN based on the representation learning is more effective than the traditional approaches.

| [1] |
O. Bodenreider, The unified medical language system (UMLS): Integrating biomedical terminology, Nucleic Acids Res., 32 (2004), D267-D270. https://doi.org/10.1093/nar/gkh061 doi: 10.1093/nar/gkh061

|
| [2] |
J. Cimino, X. Zhu, The practical impact of ontologies on biomedical informatics, Yearb. Med. Inf., 15 (2006), 124-135. https://doi.org/10.1055/s-0038-1638470 doi: 10.1055/s-0038-1638470
|
| [3] |
D. Isern, D. Sánchez, A. Moreno, Ontology-driven execution of clinical guidelines, Comput. Methods Programs Biomed., 107 (2012), 122-139. https://doi.org/10.1016/j.cmpb.2011.06.006 doi: 10.1016/j.cmpb.2011.06.006
|
| [4] |
P. Potter, H. Cools, K. Depraetere, G. Mels, P. Debevere, J. Roo, et al., Semantic patient information aggregation and medicinal decision support, Comput. Methods Programs Biomed., 108 (2012), 724-735. https://doi.org/10.1016/j.cmpb.2012.04.002 doi: 10.1016/j.cmpb.2012.04.002
|
| [5] | Q. Zhang, Z. Sun, W. Hu, M. Chen, L. Guo, Y. Qu, Multi-view knowledge graph embedding for entity alignment, preprint, arXiv: 1906.02390. |
| [6] | J. Euzenat, P. Shvaiko, Ontology Matching, 2nd edition, Springer, 2007. https://doi.org/10.1007/978-3-540-49612-0 |
| [7] |
C. Rosse, J. Mejino Jr, A reference ontology for biomedical informatics: the foundational model of anatomy, J. Biomed. Inf., 36 (2003), 478-500. https://doi.org/10.1016/j.jbi.2003.11.007 doi: 10.1016/j.jbi.2003.11.007
|
| [8] | D. Faria, C. Pesquita, E. Santos, M. Palmonari, I. Cruz, F. Couto, The agreementmakerlight ontology matching system, in Proceedings of Confederated International Conferences: CoopIS, DOA-Trusted Cloud, (2013), 527-541. https://doi.org/10.1007/978-3-642-41030-7_38 |
| [9] | E. Jiménez-Ruiz, B. Grau, Logmap: Logic-based and scalable ontology matching, in International Semantic Web Conference, (2011), 273-288. https://doi.org/10.1007/978-3-642-25073-6_18 |
| [10] | P. Kolyvakis, A. Kalousis, D. Kiritsis, Deepalignment: Unsupervised ontology matching with refined word vectors, 1 (2018), 787-798. https://doi.org/10.18653/v1/n18-1072 |
| [11] |
S. Bergamaschi, S. Castano, M. Vincini, D. Beneventano, Semantic integration of heterogeneous information sources, Data Knowl. Eng., 36 (2001), 215-249. https://doi.org/10.1016/S0169-023X(00)00047-1 doi: 10.1016/S0169-023X(00)00047-1
|
| [12] |
D. Embley, D. Jackman, L. Xu, Attribute match discovery in information integration: Exploiting multiple facets of metadata, J. Braz. Comput. Soc., 8 (2002), 32-43. https://doi.org/10.1590/S0104-65002002000200004 doi: 10.1590/S0104-65002002000200004
|
| [13] | J. Gracia, V. Lopez, M. d'Aquin, M. Sabou, E. Motta, E. Mena, Solving semantic ambiguity to improve semantic web based ontology matching, in the 2nd International Workshop on Ontology Matching, (2007), 1-12. |
| [14] |
Y. Jean-Mary, E. Shironoshita, M. Kabuka, Ontology matching with semantic verification, J. Web Semant., 7 (2009), 235-251. https://doi.org/10.1016/j.websem.2009.04.001 doi: 10.1016/j.websem.2009.04.001
|
| [15] |
P. Kolyvakis, A. Kalousis, B. Smith, D. Kiritsis, Biomedical ontology alignment: An approach based on representation learning, J. Biomed. Semant., 9 (2018), 1-20. https://doi.org/10.1186/s13326-018-0187-8 doi: 10.1186/s13326-018-0187-8
|
| [16] | M. Chen, Y. Tian, M. Yang, C. Zaniolo, Multilingual knowledge graph embeddings for cross-lingual knowledge alignment, preprint, arXiv: 1611.03954. |
| [17] | Z. Sun, W. Hu, C. Li, Cross-lingual entity alignment via joint attribute-preserving embedding, in International Semantic Web Conference, 10587 (2017), 628-644. https://doi.org/10.1007/978-3-319-68288-4_37 |
| [18] | Z. Wang, J. Yang, X. Ye, Knowledge graph alignment with entity-pair embedding, in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), (2020), 1672-1680. https://doi.org/10.18653/v1/2020.emnlp-main.130 |
| [19] | Z. Wang, Q. Lv, X. Lan, Y. Zhang, Cross-lingual knowledge graph alignment via graph convolutional networks, in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, (2018), 349-357. https://doi.org/10.18653/v1/d18-1032 |
| [20] | Y. Wu, X. Liu, Y. Feng, Z. Wang, R. Yan, D. Zhao, Relation-aware entity alignment for heterogeneous knowledge graphs, preprint, arXiv: 1908.08210. |
| [21] | Q. Zhang, Z. Sun, W. Hu, M. Chen, L. Guo, Y. Qu, Multi-view knowledge graph embedding for entity alignment, preprint, arXiv: 1906.02390. |
| [22] | Q. Zhong, H. Li, J. Li, G. Xie, J. Tang, L. Zhou, et al., A gauss function-based approach for unbalanced ontology matching, in Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, (2009), 669-680. https://doi.org/10.1145/1559845.1559915 |
| [23] |
J. Wu, J. Lv, H. Guo, S. Ma, DAEOM: A deep attentional embedding approach for biomedical ontology matching, Appl. Sci., 10 (2020), 7909. https://doi.org/10.3390/app10217909 doi: 10.3390/app10217909
|
| [24] | L. Wang, C. Bhagavatula, M. Neumann, K. Lo, C. Wilhelm, W. Ammar, Ontology alignment in the biomedical domain using entity definitions and context, in Proceedings of the BioNLP 2018 Workshop, (2018), 47-55. https://doi.org/10.18653/v1/w18-2306 |
| [25] |
P. Wang, Y. Hu, S. Bai, S. Zou, Matching biomedical ontologies: Construction of matching clues and systematic evaluation of different combinations of matchers, JMIR Med. Inf., 9 (2021), e28212. https://doi.org/10.2196/28212 doi: 10.2196/28212
|
| [26] |
F. Chen, Y. C. Wang, B. Wang, C. C. J. Kuo, Graph representation learning: A survey, APSIPA Trans. Signal Inf. Process., 9 (2020), 1-21. https://doi.org/10.1017/ATSIP.2020.13 doi: 10.1017/ATSIP.2020.13
|
| [27] | Z. Wang, J. Yang, X. Ye, Knowledge graph alignment with entity-pair embedding, in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), (2020), 1672-1680. https://doi.org/10.18653/v1/2020.emnlp-main.130 |
| [28] |
P. Wang, B. Xu, Matching weak informative ontologies, Sci. China Inf. Sci., 64 (2021), 1-2. https://doi.org/10.1007/s11432-020-3214-2 doi: 10.1007/s11432-020-3214-2
|
| [29] |
S. Song, X. Zhang, G. Qin, Multi-domain ontology mapping based on semantics, Clust. Comput., 20 (2017), 3379-3391. https://doi.org/10.1007/s10586-017-1087-x doi: 10.1007/s10586-017-1087-x
|
| [30] |
P. Lambrix, H. Tan, SAMBO—a system for aligning and merging biomedical ontologies, J. Web Semant., 4 (2006), 196-206. https://doi.org/10.1016/j.websem.2006.05.003 doi: 10.1016/j.websem.2006.05.003
|
| [31] |
G. Miller, WordNet: A lexical database for English, Commun. ACM, 38 (1995), 39-41. http://doi.acm.org/10.1145/219717.219748 doi: 10.1145/219717.219748
|
| [32] |
M. Gulić, B. Vrdoljak, M. Banek, Cromatcher: An ontology matching system based on automated weighted aggregation and iterative final alignment, J. Web Semant., 41 (2016), 50-71. https://doi.org/10.1016/j.websem.2016.09.001 doi: 10.1016/j.websem.2016.09.001
|
| [33] |
W. Hu, Y. Qu, Falcon-AO: A practical ontology matching system, J. Web Semant., 6 (2008), 237-239. https://doi.org/10.1016/j.websem.2008.02.006 doi: 10.1016/j.websem.2008.02.006
|
| [34] |
M. Zhao, S. Zhang, W. Li, G. Chen, Matching biomedical ontologies based on formal concept analysis, J. Biomed. Semant., 9 (2018), 1-27. https://doi.org/10.1186/s13326-018-0178-9 doi: 10.1186/s13326-018-0178-9
|
| [35] |
N. F. Noy, N. H. Shah, P. L. Whetzel, B. Dai, M. Dorf, N. Griffith, et al., BioPortal: Ontologies and integrated data resources at the click of a mouse, Nucleic Acids Res., 37 (2009), W170-W173. https://doi.org/10.1093/nar/gkp440 doi: 10.1093/nar/gkp440
|
| [36] | E. Jiménez-Ruiz, B. C. Grau, V. Cross, LogMap family participation in the OAEI 2017, in CEUR Workshop Proceedings, 2032 (2017), 153-157. |
| [37] |
D. Faria, C. Pesquita, E. Santos, I. Cruz, F. Couto, Automatic background knowledge selection for matching biomedical ontologies, PloS One, 9 (2014), e111226. https://doi.org/10.1371/journal.pone.0111226 doi: 10.1371/journal.pone.0111226
|
| [38] | Y. Zhang, X. Wang, S. Lai, S. He, K. Liu, J. Zhao, et al., Ontology matching with word embeddings, in Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data, Springer, Cham, (2014), 34-45. https://doi.org/10.1007/978-3-319-12277-9_4 |
| [39] | M. Sun, H. Zhu, R. Xie, Z. Liu, Iterative entity alignment via joint knowledge embeddings, in Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), (2017), 4258-4264. https://doi.org/10.24963/ijcai.2017/595 |
| [40] |
X. Xue, A compact firefly algorithm for matching biomedical ontologies, Knowl. Inf. Syst., 62 (2020), 1-17. https://doi.org/10.1007/s10115-020-01443-6 doi: 10.1007/s10115-020-01443-6
|
| [41] | Y. Bengio, P. Lamblin, D. Popovici, H. Larochelle, Greedy layer-wise training of deep networks, in Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems, 19 (2006), 4-7. |
| [42] | A. Coates, A. Ng, H. Lee, An analysis of single-layer networks in unsupervised feature learning, J. Mach. Learn. Res., 15 (2011), 215-223. |
| [43] | W. Li, X. Duan, M. Wang, X. Zhang, G. Qi, Multi-view embedding for biomedical ontology matching, in Proceedings of the 14th International Workshop on Ontology Matching collocated with the 18th International Semantic Web Conference, 2536 (2019), 13-24. |
| [44] | P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y. Bengio, Graph attention networks, preprint, arXiv: 1710.10903. |
| [45] | D. K. Duvenaud, D. Maclaurin, J. Iparraguirre, R. Bombarelli, T. Hirzel, A. Aspuru-Guzik, et al., Convolutional networks on graphs for learning molecular fingerprints, in Advances in Neural Information Processing Systems 28 (NIPS 2015), (2015), 2224-2232. |
| [46] |
S. Kearnes, K. McCloskey, M. Berndl, V. Pande, P. Riley, Molecular graph convolutions: Moving beyond fingerprints, J. Comput. Aided Mol. Des., 30 (2016), 595-608. https://doi.org/10.1007/s10822-016-9938-8 doi: 10.1007/s10822-016-9938-8
|
| [47] |
T. Hayamizu, M. Mangan, J. Corradi, J. Kadin, M. Ringwald, The adult mouse anatomical dictionary: A tool for annotating and integrating data, Genome Biol., 6 (2005), 1-8. https://doi.org/10.1186/gb-2005-6-3-r29 doi: 10.1186/gb-2005-6-3-r29
|
| [48] |
J. Golbeck, G. Fragoso, F. Hartel, J. Hendler, J. Oberthaler, B. Parsia, The national cancer institute's thesaurus and ontology, J. Web Semant., 1 (2003), 75-80. https://doi.org/10.1016/j.websem.2003.07.007 doi: 10.1016/j.websem.2003.07.007
|
| [49] |
S. Schulz, R. Cornet, K. Spackman, Consolidating SNOMED CT's ontological commitment, Appl. Ontol., 6 (2011), 1-11. https://doi.org/10.3233/AO-2011-0084 doi: 10.3233/AO-2011-0084
|
| [50] | H. Sven, H. Paulheim, DOME results for OAEI 2018, in Proceedings of the 13th International Workshop on Ontology Matching Collocated with the 17th International Semantic Web Conference, 2288 (2018), 144-151. |
| [51] |
X. Xue, J. Zhang, Matching large-scale biomedical ontologies with central concept based partitioning algorithm and adaptive compact evolutionary algorithm, Appl. Soft Comput., 106 (2021), 107343. https://doi.org/10.1016/j.asoc.2021.107343 doi: 10.1016/j.asoc.2021.107343
|
| [52] | M. Cheatham, P. Hitzler, String similarity metrics for ontology alignment, in Proceedings of the Twelfth International Semantic Web Conference, (2013), 294-309. https://doi.org/10.1007/978-3-642-41338-4_19 |
| [53] | B. Li, H. Zhou, J. He, M. Wang, Y. Yang, On the sentence embeddings from pre-trained language models, preprint, arXiv: 2011.05864. |
Figures(4) / Tables(8)

Peng Wang, Shiyi Zou, Jiajun Liu, Wenjun Ke. Matching biomedical ontologies with GCN-based feature propagation[J]. Mathematical Biosciences and Engineering, 2022, 19(8): 8479-8504. doi: 10.3934/mbe.2022394







 DownLoad:
DownLoad: