With the popularity of online social network these have become important platforms for the spread of information. This not only includes correct and useful information, but also false information, and even rumors which could result in panic. Therefore, the containment of rumor spread in social networks is important. In this paper, we propose an effective method that involves selecting a set of nodes in (k, η)-cores and immunize these nodes for rumor containment. First, we study rumor influence propagation in social networks under the extended Independent Cascade (EIC) model, an extension of the classic Independent Cascade (IC) model. Then, we decompose a social network into subgraphs via core decomposition of uncertain graphs and compute the number of immune nodes in each subgraph. Further we greedily select nodes with the Maximum Marginal Covering Neighbors Set as immune nodes. Finally, we conduct experiments using real-world datasets to evaluate our method. Experimental results show the effectiveness of our method.
Citation: Hong Wu, Zhijian Zhang, Yabo Fang, Shaotang Zhang, Zuo Jiang, Jian Huang, Ping Li. Containment of rumor spread by selecting immune nodes in social networks[J]. Mathematical Biosciences and Engineering, 2021, 18(3): 2614-2631. doi: 10.3934/mbe.2021133
With the popularity of online social network these have become important platforms for the spread of information. This not only includes correct and useful information, but also false information, and even rumors which could result in panic. Therefore, the containment of rumor spread in social networks is important. In this paper, we propose an effective method that involves selecting a set of nodes in (k, η)-cores and immunize these nodes for rumor containment. First, we study rumor influence propagation in social networks under the extended Independent Cascade (EIC) model, an extension of the classic Independent Cascade (IC) model. Then, we decompose a social network into subgraphs via core decomposition of uncertain graphs and compute the number of immune nodes in each subgraph. Further we greedily select nodes with the Maximum Marginal Covering Neighbors Set as immune nodes. Finally, we conduct experiments using real-world datasets to evaluate our method. Experimental results show the effectiveness of our method.

| [1] | H. Tankovska, Number of monthly active Facebook users worldwide as of 1st quarter 2020 (in millions), 2021. Available from: http://www.statista.com/statistics/264810/number-of-monthly-active-facebook-users-worldwid/. |
| [2] | L. L. Thomala, Number of monthly active WeChat users from 2nd quarter 2010 to 1st quarter 2020 (in millions), 2020. Available from: http://www.statista.com/statistics/255778/number-of-active-wechat-messenger-accounts/. |
| [3] |
W. Zhou, A. Wang, F. Xia, Y. Xiao, S. Tang, Effects of media reporting on mitigating spread of COVID–19 in the early phase of the outbreak, J. Math. Biosci. Eng., 17 (2020), 2693–2707. doi: 10.3934/mbe.2020147

|
| [4] | P. Domm, False rumor of explosion at White House causes stocks to briefly plunge; AP confirms its Twitter feed was hacked, CNBC. COM, 23 (2013), 2062. |
| [5] | X. He, G. Song, W. Chen, Q. Jiang, Influence blocking maximization in social networks under the competitive linear threshold model, in Proceedings of the 2012 siam international conference on data mining, (2012), 463–474. |
| [6] |
W. Liu, K. Yue, H. Wu, J. Li, D. Liu, D. Tang, Containment of competitive influence spread in social networks, Knowl. Based Syst., 109 (2016), 266–275. doi: 10.1016/j.knosys.2016.07.008
|
| [7] | R. Yan, Y. Li, W. Wu, D. Li, Y. Wang, Rumor blocking through online link deletion on social networks, ACM Trans. Knowl. Discovery Data, 13 (2019), 1–26. |
| [8] | Q. Yao, C. Zhou, L. Xiang, Y. Cao, L. Guo, Minimizing the negative influence by blocking links in social networks, in International conference on trustworthy computing and services, Springer, Berlin, Heidelberg, (2014), 65–73. |
| [9] | M. E. J. Newman, S. Forrest, J. Balthrop, Email networks and the spread of computer viruses, Phys. Rev. E, 66 (2002), 035101. |
| [10] |
A. Abdoli, Gossip, Rumors, and the COVID-19 Crisis, Disaster Med. Public Health Preparedness, 14 (2020), E29–30. doi: 10.1017/dmp.2020.272
|
| [11] | D. Kempe, J. Kleinberg, É. Tardos, Maximizing the spread of influence through a social network, in Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, (2003), 137–146. |
| [12] | F. Bonchi, F. Gullo, A. Kaltenbrunner, Y. Volkovich, Core decomposition of uncertain graphs, in Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, (2014), 1316–1325. |
| [13] | W. Chen, Y. Wang, S. Yang, Efficient influence maximization in social networks, in Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, (2009), 199–208. |
| [14] |
L. Yang, Z. W. Li, A. Giua, Containment of rumor spread in complex social networks, Inf. Sci., 506 (2020), 113–130. doi: 10.1016/j.ins.2019.07.055
|
| [15] |
W. Liu, X. Chen, B. Jeon, L. Chen, B. Chen, Influence maximization on signed networks under independent cascade model, Appl. Intell., 49 (2019), 912–928. doi: 10.1007/s10489-018-1303-2
|
| [16] | J. X. Guo, T. T. Chen, W. L.Wu, A multi-feature diffusion model: Rumor blocking in social networks, IEEE/ACM Trans. Networking, 2020. |
| [17] |
J. M. Zhu, S. Ghosh, W. L. Wu, Robust rumor blocking problem with uncertain rumor sources in social networks, World Wide Web, 24 (2021), 229–247. doi: 10.1007/s11280-020-00841-8
|
| [18] | M. Kimura, K. Saito, H. Motoda, Minimizing the spread of contamination by blocking links in a network, in Aaai, 8 (2008), 1175–1180. |
| [19] |
J. X. Guo, Y. Li, W. L. Wu, Targeted protection maximization in social networks, IEEE Trans. Network Sci. Eng., 7 (2020), 1645–1655. doi: 10.1109/TNSE.2019.2944108
|
| [20] | S. Wang, X. Zhao, Y. Chen, Z. Li, K. Zhang, J. Xia, Negative influence minimizing by blocking nodes in social networks, in Proceedings of the 17th AAAI Conference on Late-Breaking Developments in the Field of Artificial Intelligence, (2013), 134–136. |
| [21] | W. Chen, L.V. Lakshmanan, C. Castillo, Information and influence propagation in social networks, Synth. Lect. Data Manage., 5 (2013), 1–177. |
| [22] |
M. Kitsak, L. K.Gallos, S. Havlin, F. Liljeros, L. Muchnik, H. E. Stanley, et al., Identification of influential spreaders in complex networks, Nat. Phys., 6 (2010), 888–893. doi: 10.1038/nphys1746
|
| [23] | E. W. Weisstein, Binomial Distribution-from Wolfram Mathworld, 2013. Available from: http://mathworld.wolfram.com/BinomialDistribution.html. |
| [24] | J. Cao, D. Dong, S. Xu, X. Zheng, B. Liu, J. Luo, A k-core based algorithm for influence maximization in social networks, Chin. J. Comput., 38 (2015), 238–248. |
| [25] | S. Fujishige, Submodular Functions And Optimization, Elsevier, 2005. |
| [26] | SNAP Datasets: Stanford large network dataset collection, Available from: http://snap.stanford.edu/data/p2p-Gnutella04.html. |
| [27] | SNAP Datasets: Stanford large network dataset collection, Available from: http://snap.stanford.edu/data/ca-HepTh.html. |
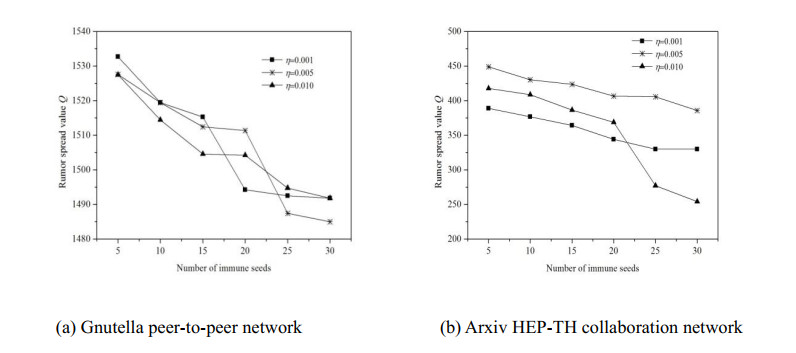
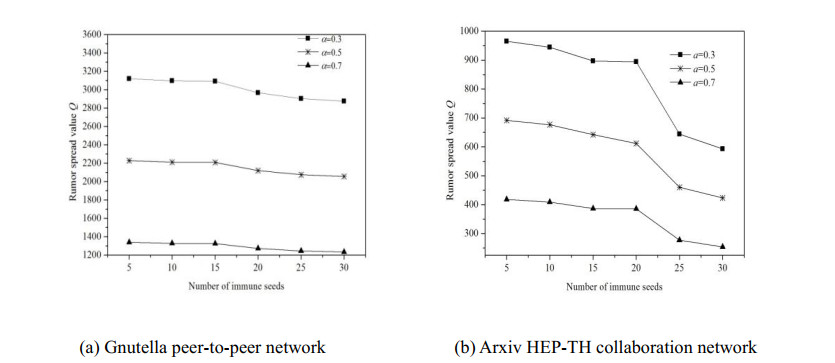
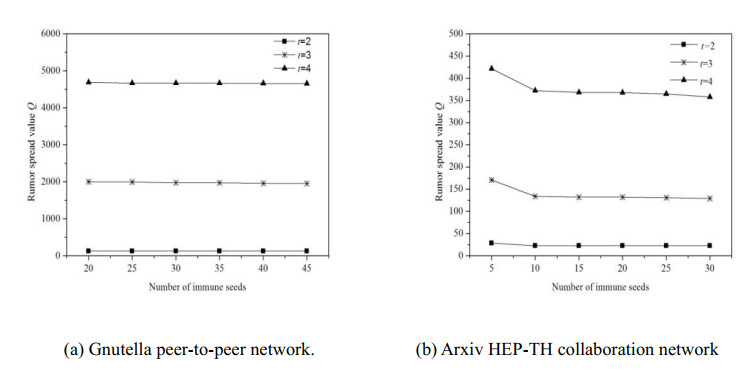
Figures(7) / Tables(4)

Hong Wu, Zhijian Zhang, Yabo Fang, Shaotang Zhang, Zuo Jiang, Jian Huang, Ping Li. Containment of rumor spread by selecting immune nodes in social networks[J]. Mathematical Biosciences and Engineering, 2021, 18(3): 2614-2631. doi: 10.3934/mbe.2021133







 DownLoad:
DownLoad: