Citation: Huimin Li, Shuwen Xiang, Yanlong Yang, Chenwei Liu. Differential evolution particle swarm optimization algorithm based on good point set for computing Nash equilibrium of finite noncooperative game[J]. AIMS Mathematics, 2021, 6(2): 1309-1323. doi: 10.3934/math.2021081

| [1] |
T. Kunieda, K. Nishimura, Finance and Economic Growth in a Dynamic Game, Dyn. Games Appl., 8 (2018), 588-600. doi: 10.1007/s13235-018-0249-7

|
| [2] | G. M. Korres, A. Kokkinou, Political Decision in a Game Theory Approach, European SocioEconomic Integration, 28 (2013), 51-61. |
| [3] |
A. Traulsen, Biological Models in Game Theory, Journal of Statistical Theory and Practice, 10 (2016), 472-474. doi: 10.1080/15598608.2016.1172462
|
| [4] | M. Qingfeng, T. Shaohong, L. Zhen, Ch. Bingyao, Sh. Weixiang, A Review of Game Theory Application Research in Safety Management, IEEE Access, 8 (2020), 107301-107313. |
| [5] | Q. Wang, L. Zhao, L. Guo, J. Ran, Z. Lijun, X. Yujing, et al., A Generalized Nash Equilibrium Game Model for Removing Regional Air Pollutant, J. Clean. Prod., 227 (2019), 522-531. |
| [6] |
J. Sheng, W. Zhou, B. Zhu, The Coordination of Stakeholder Interests in Environmental Regulation: Lessons From China's Environmental Regulation Policies From The Perspective of The Evolutionary Game Theory, J. Clean. Prod., 249 (2020), 119385. doi: 10.1016/j.jclepro.2019.119385
|
| [7] | C. E. Lemke, J. T. Howson, Jr, Equilibrium Points of Bimatrix Games, Journal of the Society for Industrial and Applied Mathematics, 12 (1964), 413-423. |
| [8] |
S. Govindan, R. Wilson, A Global Newton Method to Compute Nash Equilibria, Journal of Economic Theory, 110 (2003), 65-86. doi: 10.1016/S0022-0531(03)00005-X
|
| [9] |
J. Zhang, B. Qu, N. Xiu, Some Projection-like Methods for The Generalized Nash Equilibria, Comput. Optim. Appl., 45 (2010), 89-109. doi: 10.1007/s10589-008-9173-x
|
| [10] | Y. Ya xiang, A Trust Region Algorithm for Nash Equilibrium Problems, Pac. J. Optim., 7 (2011), 125-138. |
| [11] |
N. G. Pavlidis, K. E. Parsopoulos, M. N. Vrahatis, Computing Nash Equilibria Through Computational Intelligence Methods, J. Comput. Appl. Math., 175 (2005), 113-136. doi: 10.1016/j.cam.2004.06.005
|
| [12] |
U. Boryczka, P. Juszczuk, Differential Evolution as a New Method of Computing Nash Equilibria, Transactions on Computational Collective Intelligence IX, 7770 (2013), 192-216. doi: 10.1007/978-3-642-36815-8_9
|
| [13] | C. ShiJun, S. YongGuang, W. ZongXin, A Genetic Algorithm to Acquire the Nash Equilibrium, System Engineering, 19 (2001), 67-70. |
| [14] | Q. ZhongHua, G. Jie, Z. YueXing, Applying Immune Algorithm to Solving Game Problem, Journal of Systems Engineering, 21 (2006), 398-404. |
| [15] |
N. Franken, A. P. Engelbrecht, Particle Swarm Optimization Approaches to Coevolve Strategies for The Iterated Prisoner's Dilemma, IEEE T. Evolut. Comput., 9 (2005), 562-579. doi: 10.1109/TEVC.2005.856202
|
| [16] | J. WenSheng, X. ShuWen, Y. JianFeng, W. S. Hu, Solving Nash Equilibrium for N-persons' Non-cooperative Game Based on Immune Particle Swarm Algorithm, Application Research of Computers, 29 (2012), 28-31. |
| [17] | Y. Yanlong, X. Shuwen, X. Shunyou, J. Wensheng, Solving Nash Equilibrium of Non-Cooperative Game Based on Fireworks Algorithm, Computer Applications and Software, (in Chinese) 35 (2018), 215-218. |
| [18] | Y. Jian, Selection of Game Theory, Chinese: Science Press, 2014. |
| [19] | H. Luogeng, W. Yuan, Application of Number Theory in Modern Analysis, Beijing: Science Press, 1978. |
| [20] | R. Storn, K. Price, Minimizing The Real Functions of The ICEC'96 Contest by Differential Evolution, Proceedings of IEEE International Conference on Evolutionary Computation IEEE, (1996), 824-844. |
| [21] | R. C. Eberhart, J. Kennedy, A New Optimizer Using Particle Swarm Theory. In: 6th Symposium on Micro Machine and Human Science, Nagoya, Japan, (1995), 39-43. |
| [22] |
Y. Wu, Y. Wu, X. Liu, Couple-based Particle Swarm Optimization for Short-term Hydrothermal Scheduling, Appl. Soft Comput., 74 (2019), 440-450. doi: 10.1016/j.asoc.2018.10.041
|
| [23] | J. Shen, F. Liang, M. Zheng, New Hybrid Differential Evolution and Particle Swarm Optimization Algorithm and Its Application, Sichuan Daxue Xuebao (Gongcheng Kexue Ban) Journal of Sichuan University (Engineering Science Edition), 46 (2014), 38-43. |
| [24] |
Y. C. He, X. Z. Wang, K. Q. Liu, Y. Q. Wang, Convergent Analysis and Algorithmic Improvement of Differential Evolution, Journal of Software, 21 (2010), 875-885. doi: 10.3724/SP.J.1001.2010.03486
|
| [25] | M. Q. Li, J. S. Kou, D. Lin, S. Q. Li, Basic Theory and Application of Genetic Algorithm, Beijing: Science Press, (in Chinese) (2002), 115-119. |
| [26] | T. S. Lu, Random Functional Analysis and Its Application, Qingdao: Qingdao Ocean University Press, 1990. |
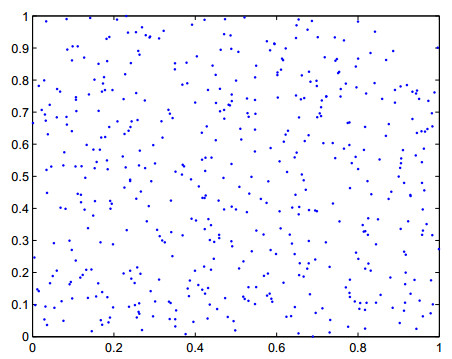
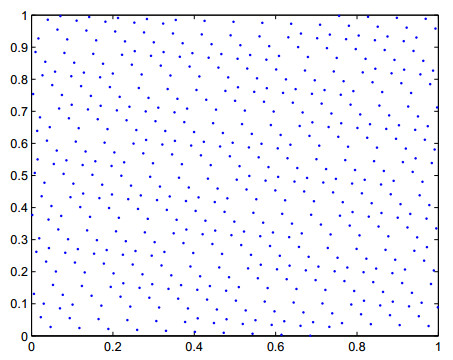
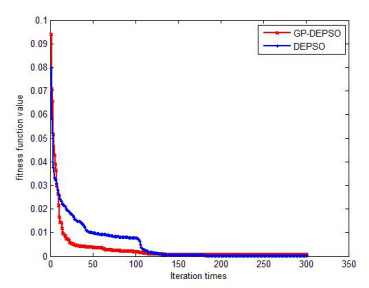
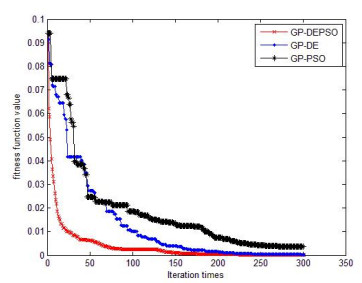
Figures(4) / Tables(4)

Huimin Li, Shuwen Xiang, Yanlong Yang, Chenwei Liu. Differential evolution particle swarm optimization algorithm based on good point set for computing Nash equilibrium of finite noncooperative game[J]. AIMS Mathematics, 2021, 6(2): 1309-1323. doi: 10.3934/math.2021081







 DownLoad:
DownLoad: