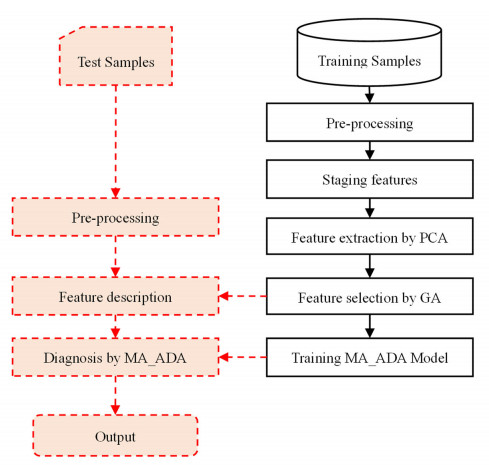
Cardiovascular disease (CVD) has now become the disease with the highest mortality worldwide and coronary artery disease (CAD) is the most common form of CVD. This paper makes effective use of patients' condition information to identify the risk factors of CVD and predict the disease according to these risk factors in order to guide the treatment and life of patients according to these factors, effectively reduce the probability of disease and ensure that patients can carry out timely treatment. In this paper, a novel method based on a new classifier, named multi-agent Adaboost (MA_ADA), has been proposed to diagnose CVD. The proposed method consists of four steps: pre-processing, feature extraction, feature selection and classification. In this method, feature extraction is performed by principal component analysis (PCA). Then a subset of extracted features is selected by the genetics algorithm (GA). This method also uses the novel MA_ADA classifier to diagnose CVD in patients. This method uses a dataset containing information on 303 cardiovascular surgical patients. During the experiments, a four-stage multi-classification study on the prediction of coronary heart disease was conducted. The results show that the prediction model proposed in this paper can effectively identify CVDs using different groups of risk factors, and the highest diagnosis accuracy is obtained when 45 features are used for diagnosis. The results also show that the MA_ADA algorithm could achieve an accuracy of 98.67% in diagnosis, which is at least 1% higher than the compared methods.
Citation: Ai-Ping Zhang, Guang-xin Wang, Wei Zhang, Jing-Yu Zhang. Cardiovascular disease classification based on a multi-classification integrated model[J]. Networks and Heterogeneous Media, 2023, 18(4): 1630-1656. doi: 10.3934/nhm.2023071
Cardiovascular disease (CVD) has now become the disease with the highest mortality worldwide and coronary artery disease (CAD) is the most common form of CVD. This paper makes effective use of patients' condition information to identify the risk factors of CVD and predict the disease according to these risk factors in order to guide the treatment and life of patients according to these factors, effectively reduce the probability of disease and ensure that patients can carry out timely treatment. In this paper, a novel method based on a new classifier, named multi-agent Adaboost (MA_ADA), has been proposed to diagnose CVD. The proposed method consists of four steps: pre-processing, feature extraction, feature selection and classification. In this method, feature extraction is performed by principal component analysis (PCA). Then a subset of extracted features is selected by the genetics algorithm (GA). This method also uses the novel MA_ADA classifier to diagnose CVD in patients. This method uses a dataset containing information on 303 cardiovascular surgical patients. During the experiments, a four-stage multi-classification study on the prediction of coronary heart disease was conducted. The results show that the prediction model proposed in this paper can effectively identify CVDs using different groups of risk factors, and the highest diagnosis accuracy is obtained when 45 features are used for diagnosis. The results also show that the MA_ADA algorithm could achieve an accuracy of 98.67% in diagnosis, which is at least 1% higher than the compared methods.

| [1] |
O. Gaidai, Y. Cao, S. Loginov, Global cardiovascular diseases death rate prediction, Curr Probl Cardiol, 48 (2023), 101622. https://doi.org/10.1016/j.cpcardiol.2023.101622 doi: 10.1016/j.cpcardiol.2023.101622

|
| [2] | Q. Liu, H. Peng, Z. Wang, Convergence to nonlinear diffusion waves for a hyperbolic-parabolic chemotaxis system modelling vasculogenesis, J. Differ. Equ., 314 (2022), 251–286. |
| [3] |
E. J, Benjamin, M. J Blaha, S. E. Chiuve, M. Cushman, S. R. Das, R. Deo, et al., Heart disease and stroke statistics—2017 update: a report from the American Heart Association, circulation, 135 (2017): e146–e603. https://doi/full/10.1161/CIR.0000000000000485 doi: 10.1161/CIR.0000000000000485
|
| [4] |
L. Wang, Y. Yu, S. Ni, D. Li, J. Liu, D. Xie, et al., Therapeutic aptamer targeting sclerostin loop3 for promoting bone formation without increasing cardiovascular risk in osteogenesis imperfecta mice, Theranostics, 12 (2022), 5645. https://doi.org/10.7150/thno.63177 doi: 10.7150/thno.63177
|
| [5] |
C. M. Bhatt, P. Patel, T. Ghetia, P. L. Mazzeo, Effective heart disease prediction using machine learning techniques, Algorithms, 16 (2023), 88. https://doi.org/10.3390/a16020088 doi: 10.3390/a16020088
|
| [6] |
Y. Yu, L. Wang, S. Ni, D. Li, J. Liu, H. Y. Chu, et al., Targeting loop3 of sclerostin preserves its cardiovascular protective action and promotes bone formation, Nat. Commun., 13 (2022), 4241. https://doi.org/10.1038/s41467-022-31997-8 doi: 10.1038/s41467-022-31997-8
|
| [7] |
G. Gunčar, M. Kukar, M. Notar, M. Brvar, P. Černelč, M. Notar, et al., An application of machine learning to haematological diagnosis, Sci. Rep., 8 (2018), 1–12. https://doi.org/10.1038/s41598-017-18564-8 doi: 10.1038/s41598-017-18564-8
|
| [8] |
S. Uguroglu, J Carbonell, M. Doyle, R. Biederman, Cost-sensitive risk stratification in the diagnosis of heart disease, Twenty-Fourth IAAI Conference, 26 (2012), 2335–2340. https://doi.org/10.1609/aaai.v26i2.18980 doi: 10.1609/aaai.v26i2.18980
|
| [9] |
M. Kukar, I. Kononenko, C. Grošelj, K. Kralj, J. Fettich, Analysing and improving the diagnosis of ischaemic heart disease with machine learning, Artif Intell Med, 16 (1999), 25–50. https://doi.org/10.1016/S0933-3657(98)00063-3 doi: 10.1016/S0933-3657(98)00063-3
|
| [10] |
J. Truett, J. Cornfield, W. Kannel, A multivariate analysis of the risk of coronary heart disease in Framingham, Journal of chronic diseases, 20 (1967): 511–524. https://doi.org/10.1016/S0933-3657(98)00063-3 doi: 10.1016/S0933-3657(98)00063-3
|
| [11] |
K. K. L. Ho, J. L. Pinsky, W. B. Kannel, D. Levy, The epidemiology of heart failure: the Framingham Study, J. Am. Coll. Cardiol., 22 (1993), A6–A13. https://doi.org/10.1016/0735-1097(93)90455-A doi: 10.1016/0735-1097(93)90455-A
|
| [12] |
R. B. D'AgostinoSr, R. S. Vasan, M. J. Pencina, P. A. Wolf, M. Cobain, J. M. Massaro, et al., General cardiovascular risk profile for use in primary care: the Framingham Heart Study, Circulation, 117 (2008), 743–753. https://doi.org/10.1161/CIRCULATIONAHA.107.699579 doi: 10.1161/CIRCULATIONAHA.107.699579
|
| [13] |
S. S. Mahmood, D. Levy, R. S. Vasan, T. J Wang, The Framingham Heart study and the epidemiology of CVD: a historical perspective, The lancet, 383 (2004), 999–1008. https://doi.org/10.1016/S0140-6736(13)61752-3 doi: 10.1016/S0140-6736(13)61752-3
|
| [14] |
J. Liu, Y. Hong, Sr. R. B. D'Agostino, Z. S. Wu, W. Wang, J. Y. Sun, et al., Predictive value for the Chinese population of the Framingham CHD risk assessment tool compared with the Chinese Multi-Provincial Cohort Study, Jama, 291 (2004), 2591–2599. https://doi.org/10.1001/jama.291.21.2591 doi: 10.1001/jama.291.21.2591
|
| [15] |
H. W. Hense, H. Schulte, H. Löwel, G Assmann, U Keil, Framingham risk function overestimates risk of coronary heart disease in men and women from Germany—results from the MONICA Augsburg and the PROCAM cohorts, Eur Heart J, 24 (2003), 937–945. https://doi.org/10.1016/S0195-668X(03)00081-2 doi: 10.1016/S0195-668X(03)00081-2
|
| [16] |
J. P. Empana, P. Ducimetière, D. Arveiler, J Ferrières, A Evans, J. B Ruidavets, et al., Are the Framingham and PROCAM coronary heart disease risk functions applicable to different European populations? The PRIME Study, Eur Heart J, 24 (2003), 1903–1911. https://doi.org/10.1016/j.ehj.2003.09.002 doi: 10.1016/j.ehj.2003.09.002
|
| [17] | World Health Organization, Prevention of CVD. Pocket Guidelines for Assessment and Management of Cardiovascular Risk. Africa: Who/Ish Cardiovascular Risk Prediction Charts for the African Region. World Health Organization, 2007. |
| [18] |
S F Weng, J Reps, J Kai, J M Garibaldi, N Qureshi, Can machine-learning improve cardiovascular risk prediction using routine clinical data, PloS one, 12 (2017), e0174944. https://doi.org/10.1371/journal.pone.0174944 doi: 10.1371/journal.pone.0174944
|
| [19] |
M. Gilani, J. M. Eklund, M. Makrehchi. Automated detection of atrial fibrillation episode using novel heart rate variability features, 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), (2016), 3461–3464. https://doi.org/10.1109/EMBC.2016.7591473 doi: 10.1109/EMBC.2016.7591473
|
| [20] |
A Porta, P Castiglioni, V Bari, T Bassani, A Marchi, A Cividjian, et al., K-nearest-neighbor conditional entropy approach for the assessment of the short-term complexity of cardiovascular control, Physiol Meas, 34 (2012), 17. https://doi.org/10.1088/0967-3334/34/1/17 doi: 10.1088/0967-3334/34/1/17
|
| [21] |
K. Polat, S. Şahan, S. Güneş, Automatic detection of heart disease using an artificial immune recognition system (AIRS) with fuzzy resource allocation mechanism and k-nn (nearest neighbour) based weighting preprocessing, Expert Syst. Appl., 32 (2007), 625–631. https://doi.org/10.1016/j.eswa.2006.01.027 doi: 10.1016/j.eswa.2006.01.027
|
| [22] |
S. Patidar, R. B. Pachori, U. R. Acharya, Automated diagnosis of coronary artery disease using tunable-Q wavelet transform applied on heart rate signals, Knowl Based Syst, 82 (2015), 1–10. https://doi.org/10.1016/j.knosys.2015.02.011 doi: 10.1016/j.knosys.2015.02.011
|
| [23] |
S. U. Amin, K. Agarwal, R. Beg, Genetic neural network based data mining in prediction of heart disease using risk factors, IEEE Conference on Information & Communication Technologies, (2013), 1227–1231. https://doi.org/10.1109/CICT.2013.6558288 doi: 10.1109/CICT.2013.6558288
|
| [24] |
R. Alizadehsani, J. Habibi, M. J. Hosseini, H. Mashayekhi, R. Boghrati, A. Ghandeharioun, et al., A data mining approach for diagnosis of coronary artery disease, Comput Methods Programs Biomed, 111 (2013), 52–61. https://doi.org/10.1016/j.cmpb.2013.03.004 doi: 10.1016/j.cmpb.2013.03.004
|
| [25] |
S Hijazi, A Page, B Kantarci, T Soyata, Machine learning in cardiac health monitoring and decision support, Computer, 49 (2016), 38–48. https://doi.org/10.1109/MC.2016.339 doi: 10.1109/MC.2016.339
|
| [26] |
U. R. Acharya, H. Fujita, S. L. Oh, Y Hagiwara, J. H. Tan, M. Adam, Application of deep convolutional neural network for automated detection of myocardial infarction using ECG signals, Inf. Sci., 415 (2017), 190–198. https://doi.org/10.1016/j.ins.2017.06.027 doi: 10.1016/j.ins.2017.06.027
|
| [27] |
P. Fuster-Parra, P. Tauler, M. Bennasar-Veny, A. Ligęza, A. A. López-González, A. Aguiló, Bayesian network modeling: A case study of an epidemiologic system analysis of cardiovascular risk, Comput Methods Programs Biomed, 126 (2016), 128–142. https://doi.org/10.1016/j.cmpb.2015.12.010 doi: 10.1016/j.cmpb.2015.12.010
|
| [28] |
D. Giri, U. R. Acharya, R. J. Martis, S. V. Sree, T. C. Lim, T. Ahamed VI, et al., Automated diagnosis of coronary artery disease affected patients using LDA, PCA, ICA and discrete wavelet transform, Knowl Based Syst, 37 (2013), 274–282. https://doi.org/10.1016/j.knosys.2012.08.011 doi: 10.1016/j.knosys.2012.08.011
|
| [29] |
A. D. Dolatabadi, S. E. Z. Khadem, B. M. Asl, Automated diagnosis of coronary artery disease (CAD) patients using optimized SVM, Comput Methods Programs Biomed, 138 (2017), 117–126. https://doi.org/10.1016/j.cmpb.2016.10.011 doi: 10.1016/j.cmpb.2016.10.011
|
| [30] | V. Dominic, D. Gupta, S. Khare, An effective performance analysis of machine learning techniques for cardiovascular disease, Appl. Med. Inf., 36 (2015), 23–32. Available from: https://ami.info.umfcluj.ro/index.php/AMI/article/view/521 |
| [31] |
L. Verma, S. Srivastava, P. C. Negi, A hybrid data mining model to predict coronary artery disease cases using non-invasive clinical data, J Med Syst, 40 (2016), 178. https://doi.org/10.1007/s10916-016-0536-z doi: 10.1007/s10916-016-0536-z
|
| [32] |
S. Shilaskar, A. Ghatol, Feature selection for medical diagnosis: Evaluation for CVDs, Expert Syst. Appl., 40 (2013), 4146–4153. https://doi.org/10.1016/j.eswa.2013.01.032 doi: 10.1016/j.eswa.2013.01.032
|
| [33] |
T. Pereira, J. S. Paiva, C. Correia, J. Cardoso, An automatic method for arterial pulse waveform recognition using KNN and SVM classifiers, Med Biol Eng Comput, 54 (2016), 104–1059. https://doi.org/10.1007/s11517-015-1393-5 doi: 10.1007/s11517-015-1393-5
|
| [34] |
A. Ozcift, Enhanced cancer recognition system based on random forests feature elimination algorithm, J Med Syst, 36 (2012), 2577–2585. https://doi.org/10.1007/s10916-011-9730-1 doi: 10.1007/s10916-011-9730-1
|
| [35] |
X. Hu, M. Cui, B. Chen, Feature selection based on random forest and application in correlation analysis of symptom and disease, IEEE International Symposium on IT in Medicine & Education, 1 (2009), 120–124. https://doi.org/10.1109/ITIME.2009.5236450 doi: 10.1109/ITIME.2009.5236450
|
| [36] |
S. M. S. Shah, F. A. Shah, S. A. Hussain, S. Batool, Support vector machines-based heart disease diagnosis using feature subset, wrapping selection and extraction methods, J. Electr. Comput. Eng., 84 (2020), 106628. https://doi.org/10.1016/j.compeleceng.2020.106628 doi: 10.1016/j.compeleceng.2020.106628
|
| [37] | K. Burse, V. P. S. Kirar, A. Burse, R. Burse, Various preprocessing methods for neural network based heart disease prediction, Smart innovations in communication and computational sciences, Singapore: Springer, 2019, 55–65. |
| [38] | A. N. Repaka, S. D. Ravikanti, R. G. Franklin, Design and implementing heart disease prediction using naives Bayesian, 3rd International conference on trends in electronics and informatics (ICOEI), (2019), 292–297 |
| [39] | K. Raza, Improving the prediction accuracy of heart disease with ensemble learning and majority voting rule, U-Healthcare Monitoring Systems, Cambridge: Academic Press, 2019,179–196. |
| [40] | D. Velusamy, & K. Ramasamy, Ensemble of heterogeneous classifiers for diagnosis and prediction of coronary artery disease with reduced feature subset. Computer Methods and Programs in Biomedicine, 198 (2021), 105770. |
| [41] |
P. Li, Y. Hu, Z. P. Liu, Prediction of cardiovascular diseases by integrating multi-modal features with machine learning methods, Biomed Signal Process Control, 66 (2021), 102474. https://doi.org/10.1016/j.bspc.2021.102474 doi: 10.1016/j.bspc.2021.102474
|
| [42] |
R. Alizadehsani, M. H. Zangooei, M. J. Hosseini, J. Habibi, A. Khosravi, M. Roshanzamir, et al., Coronary artery disease detection using computational intelligence methods, Knowl Based Syst, 109 (2016), 187–197. https://doi.org/10.1016/j.knosys.2016.07.004 doi: 10.1016/j.knosys.2016.07.004
|
| [43] |
Z. Arabasadi, R. Alizadehsani, M. Roshanzamir, H. Moosaei, A. A. Yarifard, Computer aided decision making for heart disease detection using hybrid neural network-Genetic algorithm, Comput Methods Programs Biomed, 141 (2017), 19–26. https://doi.org/10.1016/j.cmpb.2017.01.004 doi: 10.1016/j.cmpb.2017.01.004
|
Figures(7) / Tables(4)
Ai-Ping Zhang, Guang-xin Wang, Wei Zhang, Jing-Yu Zhang. Cardiovascular disease classification based on a multi-classification integrated model[J]. Networks and Heterogeneous Media, 2023, 18(4): 1630-1656. doi: 10.3934/nhm.2023071







 DownLoad:
DownLoad: