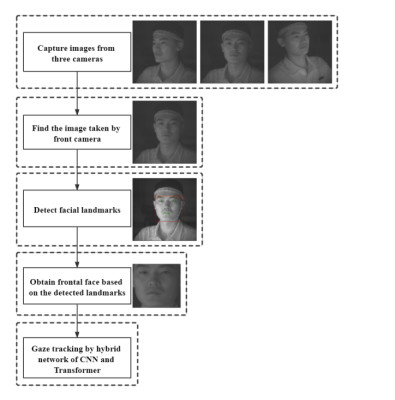
Improving the efficiency of human-computer interaction is one of the critical goals of intelligent aircraft cockpit research. The gaze interaction control method can vastly reduce the manual operation of operators and improve the intellectual level of human-computer interaction. Eye-tracking is the basis of sight interaction, so the performance of eye-tracking will directly affect the outcome of gaze interaction. This paper presents an eye-tracking method suitable for human-computer interaction in an aircraft cockpit, which can now estimate the gaze position of operators on multiple screens based on face images. We use a multi-camera system to capture facial images, so that operators are not limited by the angle of head rotation. To improve the accuracy of gaze estimation, we have constructed a hybrid network. One branch uses the transformer framework to extract the global features of the face images; the other branch uses a convolutional neural network structure to extract the local features of the face images. Finally, the extracted features of the two branches are fused for eye-tracking. The experimental results show that the proposed method not only solves the problem of limited head movement for operators but also improves the accuracy of gaze estimation. In addition, our method has a capture rate of more than 80% for targets of different sizes, which is better than the other compared models.
Citation: Li Wang, Changyuan Wang, Yu Zhang, Lina Gao. An integrated neural network model for eye-tracking during human-computer interaction[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 13974-13988. doi: 10.3934/mbe.2023622
Improving the efficiency of human-computer interaction is one of the critical goals of intelligent aircraft cockpit research. The gaze interaction control method can vastly reduce the manual operation of operators and improve the intellectual level of human-computer interaction. Eye-tracking is the basis of sight interaction, so the performance of eye-tracking will directly affect the outcome of gaze interaction. This paper presents an eye-tracking method suitable for human-computer interaction in an aircraft cockpit, which can now estimate the gaze position of operators on multiple screens based on face images. We use a multi-camera system to capture facial images, so that operators are not limited by the angle of head rotation. To improve the accuracy of gaze estimation, we have constructed a hybrid network. One branch uses the transformer framework to extract the global features of the face images; the other branch uses a convolutional neural network structure to extract the local features of the face images. Finally, the extracted features of the two branches are fused for eye-tracking. The experimental results show that the proposed method not only solves the problem of limited head movement for operators but also improves the accuracy of gaze estimation. In addition, our method has a capture rate of more than 80% for targets of different sizes, which is better than the other compared models.

| [1] |
Y. Shi, Z. Zhang, K. Huang, W. Ma, S. Tu, Human-computer interaction based on face feature localization, J. Visual Commun. Image Represent., 70 (2020), 102740. https://doi.org/10.1016/j.jvcir.2019.102740 doi: 10.1016/j.jvcir.2019.102740

|
| [2] |
Q. Wang, P. Lu, Research on application of artificial intelligence in computer network technology, Int. J. Pattern Recogn. Artif. Intell., 33 (2019), 1–12. https://doi.org/10.1142/S0218001419590158 doi: 10.1142/S0218001419590158
|
| [3] |
B. Han, X. Yang, Z. Sun, J. Huang, J. Su, OverWatch: A cross-plane DDoS attack defense framework with collaborative intelligence in SDN, Secur. Commun. Networks, 2018 (2018), 1–15. https://doi.org/10.1155/2018/9649643 doi: 10.1155/2018/9649643
|
| [4] | S. Andrist, X. Z. Tan, M. Gleicher, B. Mutlu, Conversational Gaze Aversion for Humanlike Robots, in: 2014 9th ACM/IEEE International Conference on Human-Robot Interaction (HRI), (2014), 25–32. https://doi.org/10.1145/2559636.2559666 |
| [5] |
H. Zhu, S. E. Salcudean, R. N. Rohling, A novel gaze-supported multimodal human-computer interaction for ultrasound machines, Int. J. Computer Assisted Radiol. Surgery, 12 (2019), 1–9. https://doi.org/10.1007/s11548-019-01964-8 doi: 10.1007/s11548-019-01964-8
|
| [6] | R. Wang, Y. Xu, L. Chen, GazeMotive: A Gaze-Based Motivation-Aware E-Learning Tool for Students with Learning Difficulties, in: Human-computer Interaction-INTERACT 2019, (2019), 544–548. https://doi.org/10.1007/978-3-030-29390-1_34 |
| [7] |
K. B. N. Pavan, A. Balasubramanyam, A. K. Patil, B. Chethana, Y. H. Chai, GazeGuide: An eye-gaze-guided active immersive UAV camera, Appl. Sci., 10 (2020), 1668. https://doi.org/10.3390/app10051668 doi: 10.3390/app10051668
|
| [8] | C. Creed, M. Frutos-Pascual, I. Williams, Multimodal gaze interaction for creative design, in: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, 8 (2020), 1–13. https://doi.org/10.1145/3313831.3376196 |
| [9] | X. Yan, W. Hou, X. Xu, obstacle judgment model of in-vehicle voice interaction system based on eye-tracking, in: 2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD), 7 (2021), 569–574. https://doi.org/10.1109/CSCWD49262.2021.9437635 |
| [10] |
W. Pichitwong, K. Chamnongthai, An eye-tracker-based 3D point-of-gaze estimation method using head movement, IEEE Access, 7 (2019), 99086–99098. https://doi.org/10.1109/ACCESS.2019.2929195 doi: 10.1109/ACCESS.2019.2929195
|
| [11] |
P. Li, X. Hou, X. Duan, H. Yip, G. Song, Y. Liu, Appearance-based gaze estimator for natural interaction control of surgical robots, IEEE Access, 7 (2019), 25095–25110. https://doi.org/10.1109/ACCESS.2019.2900424 doi: 10.1109/ACCESS.2019.2900424
|
| [12] | E. Lindén, J. Sjstrand, A. Proutiere, Learning to personalize in appearance-based gaze tracking, in: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), (2019), 1140–1148. https://doi.org/10.1109/ICCVW.2019.00145 |
| [13] | S. Gu, L. Wang, L. He, X. He, J. Wang, Gaze estimation via a differential eyes, in: Appearances Network with a Reference Grid, Engineering, 7 (2021), 777–786. https://doi.org/10.1016/j.eng.2020.08.027 |
| [14] | X. B, J. A, Z. Zhuo, Z. A, S. C, H. D, Improved it racker combined with bidirectional long short-term memory for 3D gaze estimation using appearance cues, Neurocomputing, 390 (2020), 217–225. https://doi.org/10.1016/j.neucom.2019.04.099 |
| [15] | K. Mora, J. M. Odobez, Geometric generative gaze estimation (G3E) for remote RGB-D cameras, in: IEEE Conference on Computer Vision & Pattern Recognition, (2014), 1773–1780. https://doi.org/10.1109/CVPR.2014.229 |
| [16] | C. Jen, Y. Chen, Y. Lin, C. Lee, M. T. Li, Vi-sion based wearable eye-gaze tracking system, in: 2016 IEEE International Conference on Consumer Electronics (ICCE), (2016), 202–203. https://doi.org/10.1109/ICCE.2016.7430580 |
| [17] |
J. Sigut, S. A. Sidha, Iris center corneal reflection method for gaze tracking using visible light, IEEE Trans. Biomed. Eng., 58 (2011), 411–419. https://doi.org/10.1109/TBME.2010.2087330 doi: 10.1109/TBME.2010.2087330
|
| [18] |
Y. Ebisawa, K. Fukumoto, Head-free, remote eye-gaze detection system based on pupil-corneal reflection method with easy calibration using two stereo-calibrated video cameras, IEEE Trans. Biomed. Eng., 60 (2013), 2952–2960. https://doi.org/10.1109/TBME.2013.2266478 doi: 10.1109/TBME.2013.2266478
|
| [19] |
M. Yu, Y. Lin, X. Tang, D. Schmidt, Y. Guo, An easy iris center detection method for eye gaze tracking system, J. Eye Movement Res., 8 (2015), 1–20. https://doi.org/10.16910/jemr.8.3.5 doi: 10.16910/jemr.8.3.5
|
| [20] | L. Sesma, A. Villanueva, R. Cabeza, Evaluation of pupil center-eye corner vector for gaze estimation using a web cam, in: Eye Tracking Research & Application (ACM), (2012), 217–220. https://doi.org/10.1145/2168556.2168598 |
| [21] | Y. Cheng, S. Huang, F. Wang, C. Qian, F Lu, A coarse-to-fine adaptive network for appearance-based gaze estimation, in: Proceedings of the AAAI Conference on Artificial Intelligence, (2020), 10–15. https://doi.org/10.1609/aaai.v34i07.6636 |
| [22] |
W. Lu, Y. Li, Y. Cheng, D. Meng, B. Liang, P. Zhou, Early fault detection approach with deep architectures, IEEE Trans. Instrum. Meas., 67 (2018), 1–11. https://doi.org/10.1109/TIM.2018.2800978 doi: 10.1109/TIM.2018.2800978
|
| [23] | E. Lindén, J. Sjöstrand, A. Proutiere, Learning to personalize in appearance-based gaze tracking, in: Proceedings of the IEEE/CVF international conference on computer vision workshops, (2019), 1140–1148. https://doi.org/10.1109/ICCVW.2019.00145 |
| [24] |
S. Cheng, J. Chen, C. Anastasiou, P. Angeli, O. Matar, Y. Guo, Generalised latent assimilation in heterogeneous reduced spaces with machine learning surrogate models, J. Sci.comput., 94 (2023), 11. https://doi.org/10.1007/s10915-022-02059-4 doi: 10.1007/s10915-022-02059-4
|
| [25] |
S. Cheng, I. C. Prentice, Y. Huang, Y. Jin, Y. Guo, R. Arcucci, Data-driven surrogate model with latent data assimilation: Application to wildfire forecasting, J. Comput. Phys., 464 (2022), 111302. https://doi.org/10.1016/j.jcp.2022.111302 doi: 10.1016/j.jcp.2022.111302
|
| [26] | J. Jiang, X. Zhou, S. Chan, S. Chen, Appearance-based gaze tracking: A brief review, in: International Conference on Intelligent Robotics and Applications, (2019), 629–640. https://doi.org/10.1007/978-3-030-27529-7_53 |
| [27] |
X. Zhang, Y. Sugano, M. Fritz, A. Bulling, MPIIGaze: real-world dataset and deep appearance-based gaze estimation, IEEE Trans. Pattern. Anal. Mach. Intell., 1 (2019), 162–175. https://doi.org/10.1109/TPAMI.2017.2778103 doi: 10.1109/TPAMI.2017.2778103
|
| [28] | B. Mahanama, Y. Jayawardana, S. Jayarathna, Gaze-net: appearance-based gaze estimation using capsule networks, in: The Augmented Human International Conference, (2020), 1–4. https://doi.org/10.1145/3396339.3396393 |
| [29] | Y. Zhuang, Y. Zhang, H. Zhao, Appearance-based gaze estimation using separable convolution neural networks, in: Electronic and Automation Control Conference (IAEAC), (2021), 609–612. https://doi.org/10.1109/IAEAC50856.2021.9390807 |
| [30] | X. Zhang, M. Huang, Y. Sugano, A. Bulling, Training person-specific gaze estimators from user interactions with multiple devices, in: Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, (2018), 1–12. https://doi.org/10.1145/3173574.3174198 |
| [31] | P. Li, X. Hou, L. Wei, G. Song, X. Duan, Efficient and low-cost deep-learning based gaze estimator for surgical robot control, in: 2018 IEEE International Conference on Real-time Computing and Robotics (RCAR) IEEE, (2019), 58–63. https://doi.org/10.1109/RCAR.2018.8621810 |
| [32] | O. Lorenz, U. Thomas, Real time eye gaze tracking system using cnn-based facial features for human attention measurement, in: Proceedings of the 14th International Joint Conference on Computer Vision, (2019), 598–606. https://doi.org/10.5220/0007565305980606 |
| [33] |
J. H. Kim, S. J. Choi, J. W. Jeong, Watch & do: a smart iot interaction system with object detection and gaze estimation, IEEE Trans. Broadcast Telev. Receivers, 65 (2019), 195–204. https://doi.org/10.1109/TCE.2019.2897758 doi: 10.1109/TCE.2019.2897758
|
| [34] |
W. Luo, J. Cao, K. Ishikawa, D. Ju, A Human-Computer Control System Based on Intelligent Recognition of Eye Movements and Its Application in Wheelchair Driving, Multi. Technol. Inter., 5 (2021), 50. https://doi.org/10.3390/mti5090050 doi: 10.3390/mti5090050
|
| [35] | A. Bulat, G. Tzimiropoulos, How far are we from solving the 2D & 3D face alignment problem? (and a dataset of 230 000 3D facial landmarks), in: IEEE Computer Society, (2017), 1021–1030. https://doi.org/10.1109/ICCV.2017.116 |
| [36] | A. Newell, K. Yang, J. Deng, Stacked hourglass net-works for human pose estimation, in: Computer Vision–ECCV 2016: 14th European Conference, (2016), 11–14. https://doi.org/10.1007/978-3-319-46484-8_29 |
| [37] | A. Bulat, G. Tzimiropoulos, Binarized convolutional landmark localizers for human pose estimation and face alignment with limited resources, in: 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 3726–3734. https://doi.org/10.1109/ICCV.2017.400 |
| [38] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Attention is all you need, in: Advances in neural information processing systems, 30 (2017), 5998–6008. https://doi.org/10.48550/arXiv.1706.03762 |
| [39] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al, An image is worth 16x16 words: Transformers for image recognition at scale, in: International Conference on Learning Representations, (2021). https://doi.org/10.48550/arXiv.2010.11929 |
| [40] | TY. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, S. Belongie, Feature pyramid networks for object detection, in: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 936–944. https://doi.org/10.1109/CVPR.2017.106 |
| [41] | Y. Cheng, S. Huang, F. Wang, C. Qian, F. Lu, A coarse-to-fine adaptive network for appearance-based gaze estimation, in: Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 10623–10630. https://doi.org/10.1609/aaai.v34i07.6636 |
| [42] | S. Liu, D. Liu, H. Wu, Gaze estimation with multi-scale channel and spatial attention, in: The International Conference on Computing and Pattern Recognition, (2023), 303–309. https://doi.org/10.1145/3436369.3437438 |









Figures(10) / Tables(1)

Li Wang, Changyuan Wang, Yu Zhang, Lina Gao. An integrated neural network model for eye-tracking during human-computer interaction[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 13974-13988. doi: 10.3934/mbe.2023622







 DownLoad:
DownLoad: