Citation: Yan Li, Junwei Wang, Shuangkui Ge, Xiangyang Luo, Bo Wang. A reversible database watermarking method with low distortion[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4053-4068. doi: 10.3934/mbe.2019200

| [1] | N. Gursale and A. Mohanpurkar, A robust, distortion minimization fingerprinting technique for relational database, IJRITCC, 2(2014), 1737–1741. |
| [2] | R. Agrawal and J. Kiernan, Watermarking relational databases, VLDB, Elsevier, Hong Kong, China, 28 (2002), 155–166. |
| [3] | R. Sion, Proving ownership over categorical data, ICDE, Boston, (2004), 584–596. |
| [4] | R. Sion, M. Atallah and S. Prabhakar, Rights protection for categorical data, IEEE Trans. Knowl. Data Eng., 17(2005), 912–926. |
| [5] | S. Liu, S. Wang, R. Deng, et al, A block oriented fingerprinting scheme in relational database, ISCISC, Seoul, Korea, (2004), 145–192. |
| [6] | M. Shehab, E. Bertino and A. Ghafoor, Watermarking relational databases using optimization-based techniques, IEEE Trans. Knowl. Data Eng., 20 (2008), 116–129. |
| [7] | Y. Zhang, B. Yang and X. Niu, Reversible watermarking for relational database authentication, JCP, 17 (2006), 59–65. |
| [8] | J. Chang and H. Wu, Reversible fragile database watermarking technology using difference expansion based on SVR prediction, IS3C, Taiwan, China, (2012), 690–693. |
| [9] | E. Mahmoud, H. Farfoura and X. Wang, A novel blind reversible method for watermarking relational databases, JCIE, 36 (2013), 87–97. |
| [10] | V. Khanduja, S. Chakraverty and O. Verma, Enabling information recovery with ownership using robust multiple watermarks, JISA, 29 (2016), 80–92. |
| [11] | G. Gupta and J. Pieprzyk, Reversible and blind database watermarking using difference expansion, IJDCF, 1 (2008), 42–54. |
| [12] | G. Gupta and J. Pieprzyk, Database relation watermarking resilient against secondary watermarking attacks, Inform. System. Secur., Springer, (2009), 222–236. |
| [13] | S. Bhattacharya and A. Cortesi, A distortion free watermark framework for relational databases, ICSDT, Sofia, Bulgaria, (2013), 229–234. |
| [14] | K. Jawad and A. Khan, Genetic algorithm and difference expansion based reversible watermarking for relational databases, J. System Software, 86 (2013), 2742–2753. |
| [15] | M. Farfoura and A. Horng, A novel blind reversible method for watermarking relational databases, ISPA, (2010), 563–569. |
| [16] | S. Iftikhar, M. Kamran and Z. Anwar, RRW-a robust and reversible watermarking technique for relational data, IEEE Trans. Knowl. Data Eng., 27 (2015), 1132–1145. |
| [17] | D. H. Hu, D. Zhao and S. L. Zheng, A new robust approach for reversible database watermarking with distortion control, IEEE Trans. Knowl. Data Eng., (2018), DOI: 10.1109/TKDE.2018.2851517. |
| [18] | Y. Cao, Z. L. Zhou, X. M. Su, et al., Coverless information hiding based on the molecular structure images of material, CMC, 54 (2018), 197–207. |
| [19] | W.J. Xu, S.J. Xiang and V. Sachnev, A Cryptograph Domain Image Retrieval Method Based on Paillier Homomorphic Block Encryption, CMC, 55 (2018), 285–295. |
| [20] | J. W. Wang, T. Li, X. Y. Luo, et al., Identifying computer generated images based on quaternion central moments in color quaternion wavelet domain, TCSVT, (2018), DOI: 10.1109/TCSVT.2018.2867786. |
| [21] | Y. Du, Z. X. Yin and X. P. Zhang, Improved lossless data hiding for jpeg images based on histogram modification, CMC, 55 (2018), 495–507. |
| [22] | Y. Zhang, C. Qin, W. M. Zhang, et al., On the fault-tolerant performance for a class of robust image steganography, Signal Process.g, 146 (2018), 99–111. |
| [23] | X. Y. Luo, X. F. Song, X. L. Li, et al., Steganalysis of HUGO steganography based on parameter recognition of syndrome-trellis-codes, Mult Tool Appl., 75 (2016), 13557–13583. |
| [24] | T. Qiao, R. Shi, X. Y. Luo, et al., Statistical model-based detector via texture weight map: Application in re-sampling authentication, TMM, (2018), DOI: 10.1109/TMM.2018.2872863. |
| [25] | Y. Y. Ma, X. Y. Luo, X. L. Li, et al., Selection of rich model steganalysis features based on decision rough set α-positive region reduction, TCSVT, 29 (2019), 336–350. |
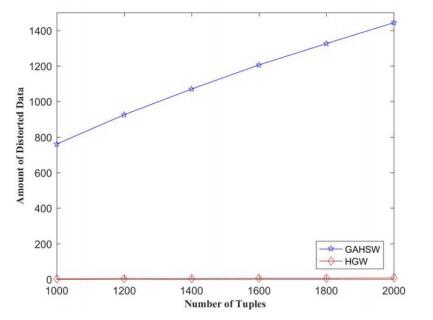
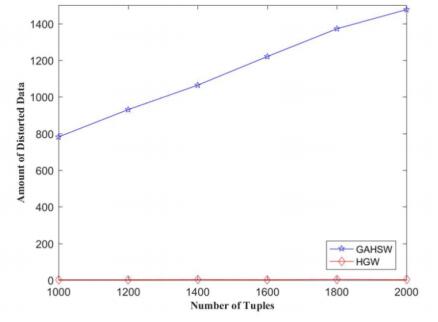
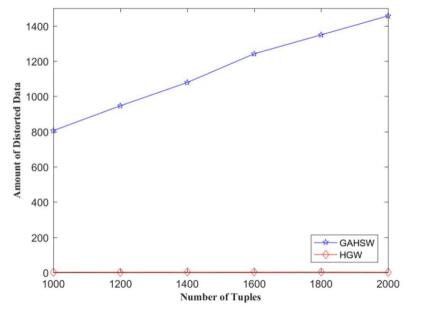
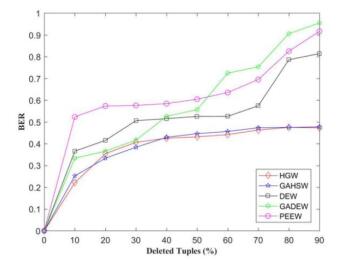
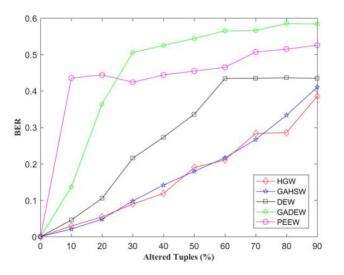
Figures(9)

Yan Li, Junwei Wang, Shuangkui Ge, Xiangyang Luo, Bo Wang. A reversible database watermarking method with low distortion[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 4053-4068. doi: 10.3934/mbe.2019200







 DownLoad:
DownLoad: