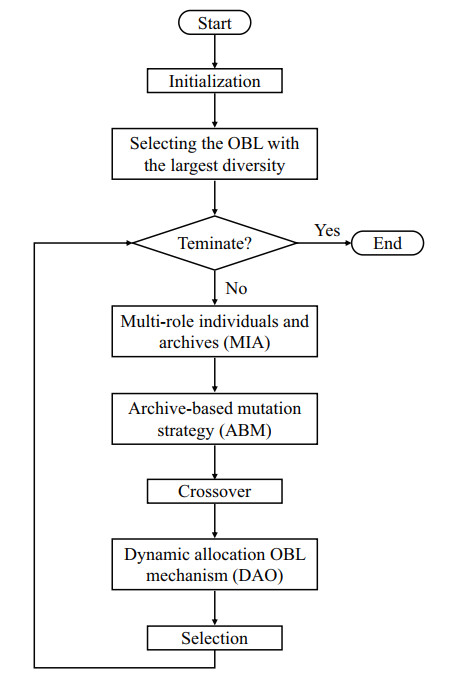
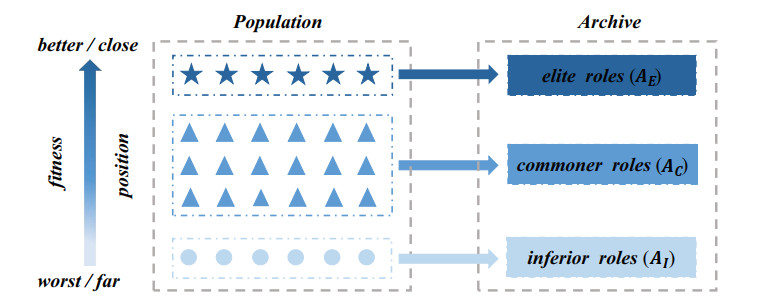
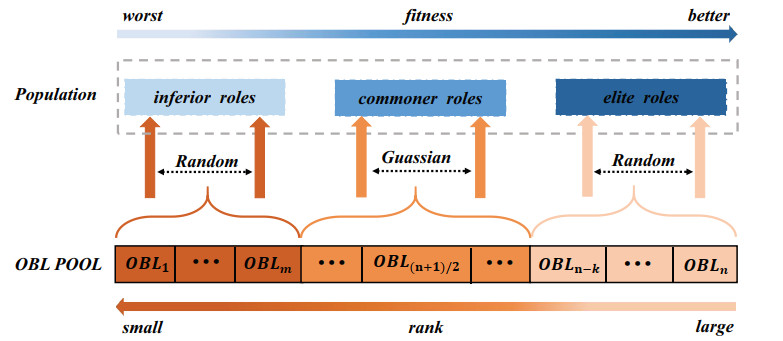
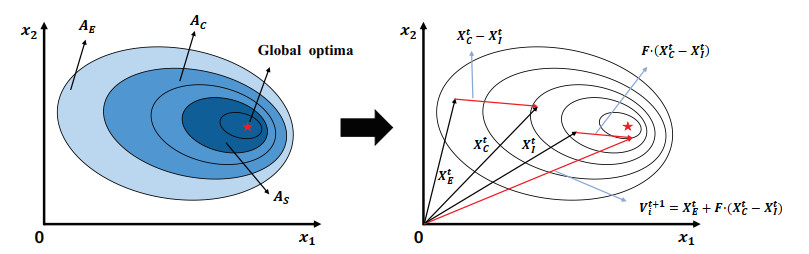
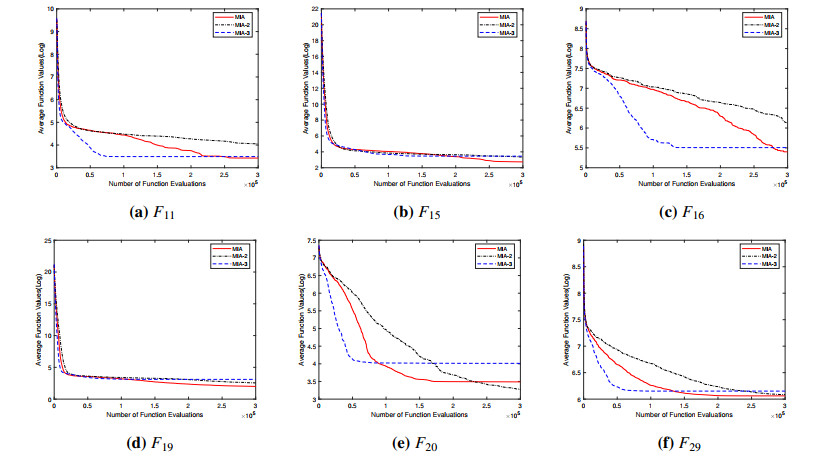
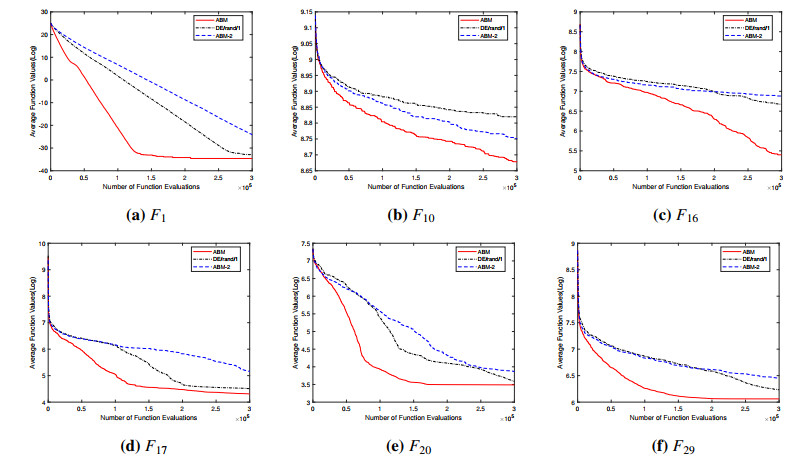
Opposition-based learning (OBL) is an optimization method widely applied to algorithms. Through analysis, it has been found that different variants of OBL demonstrate varying performance in solving different problems, which makes it crucial for multiple OBL strategies to co-optimize. Therefore, this study proposed a dynamic allocation of OBL in differential evolution for multi-role individuals. Before the population update in DAODE, individuals in the population played multiple roles and were stored in corresponding archives. Subsequently, different roles received respective rewards through a comprehensive ranking mechanism based on OBL, which assigned an OBL strategy to maintain a balance between exploration and exploitation within the population. In addition, a mutation strategy based on multi-role archives was proposed. Individuals for mutation operations were selected from the archives, thereby influencing the population to evolve toward more promising regions. Experimental results were compared between DAODE and state of the art algorithms on the benchmark suite presented at the 2017 IEEE conference on evolutionary computation (CEC2017). Furthermore, statistical tests were conducted to examine the significance differences between DAODE and the state of the art algorithms. The experimental results indicated that the overall performance of DAODE surpasses all state of the art algorithms on more than half of the test functions. Additionally, the results of statistical tests also demonstrated that DAODE consistently ranked first in comprehensive ranking.
Citation: Jian Guan, Fei Yu, Hongrun Wu, Yingpin Chen, Zhenglong Xiang, Xuewen Xia, Yuanxiang Li. Dynamic allocation of opposition-based learning in differential evolution for multi-role individuals[J]. Electronic Research Archive, 2024, 32(5): 3241-3274. doi: 10.3934/era.2024149
Opposition-based learning (OBL) is an optimization method widely applied to algorithms. Through analysis, it has been found that different variants of OBL demonstrate varying performance in solving different problems, which makes it crucial for multiple OBL strategies to co-optimize. Therefore, this study proposed a dynamic allocation of OBL in differential evolution for multi-role individuals. Before the population update in DAODE, individuals in the population played multiple roles and were stored in corresponding archives. Subsequently, different roles received respective rewards through a comprehensive ranking mechanism based on OBL, which assigned an OBL strategy to maintain a balance between exploration and exploitation within the population. In addition, a mutation strategy based on multi-role archives was proposed. Individuals for mutation operations were selected from the archives, thereby influencing the population to evolve toward more promising regions. Experimental results were compared between DAODE and state of the art algorithms on the benchmark suite presented at the 2017 IEEE conference on evolutionary computation (CEC2017). Furthermore, statistical tests were conducted to examine the significance differences between DAODE and the state of the art algorithms. The experimental results indicated that the overall performance of DAODE surpasses all state of the art algorithms on more than half of the test functions. Additionally, the results of statistical tests also demonstrated that DAODE consistently ranked first in comprehensive ranking.

| [1] |
L. Migliorelli, D. Berardini, K. Cela, M. Coccia, L. Villani, E. Frontoni, et al., A store-and-forward cloud-based telemonitoring system for automatic assessing dysarthria evolution in neurological diseases from video-recording analysis, Comput. Biol. Med., 163 (2023), 107194. https://doi.org/10.1016/j.compbiomed.2023.107194 doi: 10.1016/j.compbiomed.2023.107194

|
| [2] |
W. Zhu, L. Fang, X. Ye, M. Medani, J. Escorcia-Gutierrez, IDRM: Brain tumor image segmentation with boosted rime optimization, Comput. Biol. Med., 166 (2023), 107551. https://doi.org/10.1016/j.compbiomed.2023.107551 doi: 10.1016/j.compbiomed.2023.107551
|
| [3] |
X. Zhang, Z. Wang, Z. Lu, Multi-objective load dispatch for microgrid with electric vehicles using modified gravitational search and particle swarm optimization algorithm, Appl. Energy, 306 (2022), 118018. http://dx.doi.org/10.1016/j.apenergy.2021.118018 doi: 10.1016/j.apenergy.2021.118018
|
| [4] |
S. Yin, Q. Luo, Y. Zhou, IBMSMA: An indicator-based multi-swarm slime mould algorithm for multi-objective truss optimization problems, J. Bionic Eng., 20 (2023), 1333–1360. http://dx.doi.org/10.1007/s42235-022-00307-9 doi: 10.1007/s42235-022-00307-9
|
| [5] |
X. Ju, F. Liu, L. Wang, W. J. Lee, Wind farm layout optimization based on support vector regression guided genetic algorithm with consideration of participation among landowners, Energy Convers. Manage., 196 (2019), 1267–1281. http://dx.doi.org/10.1016/j.enconman.2019.06.082 doi: 10.1016/j.enconman.2019.06.082
|
| [6] | J. H. Holland, Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence, MIT press, 1992. |
| [7] | J. Kennedy, R. Eberhart, Particle swarm optimization, in Proceedings of ICNN'95-International Conference on Neural Networks, 4 (1995), 1942–1948. http://dx.doi.org/10.1109/ICNN.1995.488968 |
| [8] |
M. Dorigo, V. Maniezzo, A. Colorni, Ant system: Optimization by a colony of cooperating agents, IEEE Trans. Syst. Man Cybern. Part B, 26 (1996), 29–41. http://dx.doi.org/10.1109/3477.484436 doi: 10.1109/3477.484436
|
| [9] | D. Karaboga, An Idea Based on Honey Bee Swarm for Numerical Optimization, Report, Technical report-tr06, Erciyes university, engineering faculty, computer, 2005. |
| [10] |
S. Mirjalili, S. M. Mirjalili, A. Lewis, Grey wolf optimizer, Adv. Eng. Software, 69 (2014), 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 doi: 10.1016/j.advengsoft.2013.12.007
|
| [11] |
J. Lian, G. Hui, L. Ma, T. Zhu, X. Wu, A. A. Heidari, et al., Parrot optimizer: Algorithm and applications to medical problems, Comput. Biol. Med., 172 (2024), 108064. https://doi.org/10.1016/j.compbiomed.2024.108064 doi: 10.1016/j.compbiomed.2024.108064
|
| [12] |
H. Su, D. Zhao, A. A. Heidari, L. Liu, X. Zhang, M. Mafarja, et al., Rime: A physics-based optimization, Neurocomputing, 532 (2023), 183–214. https://doi.org/10.1016/j.neucom.2023.02.010 doi: 10.1016/j.neucom.2023.02.010
|
| [13] |
I. Ahmadianfar, A. A. Heidari, S. Noshadian, H. Chen, A. H. Gandomi, INFO: An efficient optimization algorithm based on weighted mean of vectors, Expert Syst. Appl., 195 (2022), 116516. https://doi.org/10.1016/j.eswa.2022.116516 doi: 10.1016/j.eswa.2022.116516
|
| [14] |
Y. Yang, H. Chen, A. A. Heidari, A. H. Gandomi, Hunger games search: Visions, conception, implementation, deep analysis, perspectives, and towards performance shifts, Expert Syst. Appl., 177 (2021), 114864. https://doi.org/10.1016/j.eswa.2021.114864 doi: 10.1016/j.eswa.2021.114864
|
| [15] |
R. Storn, K. Price, Differential evolution–-a simple and efficient heuristic for global optimization over continuous spaces, J. Global Optim., 11 (1997), 341–359. http://dx.doi.org/10.1023/A:1008202821328 doi: 10.1023/A:1008202821328
|
| [16] |
D. Liu, Z. Hu, Q. Su, Neighborhood-based differential evolution algorithm with direction induced strategy for the large-scale combined heat and power economic dispatch problem, Inf. Sci., 613 (2022), 469–493. https://doi.org/10.1016/j.ins.2022.09.025 doi: 10.1016/j.ins.2022.09.025
|
| [17] |
C. Zhang, W. Zhou, W. Qin, W. Tang, A novel UAV path planning approach: Heuristic crossing search and rescue optimization algorithm, Expert Syst. Appl., 215 (2023), 119243. https://doi.org/10.1016/j.eswa.2022.119243 doi: 10.1016/j.eswa.2022.119243
|
| [18] |
M. Sajid, H. Mittal, S. Pare, M. Prasad, Routing and scheduling optimization for UAV assisted delivery system: A hybrid approach, Appl. Soft Comput., 126 (2022), 109225. https://doi.org/10.1016/j.asoc.2022.109225 doi: 10.1016/j.asoc.2022.109225
|
| [19] |
L. Abualigah, M. A. Elaziz, D. Yousri, M. A. A. Al-qaness, A. A. Ewees, R. A. Zitar, Augmented arithmetic optimization algorithm using opposite-based learning and lévy flight distribution for global optimization and data clustering, J. Intell. Manuf., 34 (2023), 3523–3561. http://dx.doi.org/10.1007/s10845-022-02016-w doi: 10.1007/s10845-022-02016-w
|
| [20] | H. R. Tizhoosh, Opposition-based learning: A new scheme for machine intelligence, in International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC'06), 1 (2005), 695–701. http://dx.doi.org/10.1109/CIMCA.2005.1631345 |
| [21] |
S. Rahnamayan, H. R. Tizhoosh, M. M. A. Salama, Opposition-based differential evolution, IEEE Trans. Evol. Comput., 12 (2008), 64–79. http://dx.doi.org/10.1109/TEVC.2007.894200 doi: 10.1109/TEVC.2007.894200
|
| [22] |
M. Črepinšek, S. H. Liu, M. Mernik, Exploration and exploitation in evolutionary algorithms, ACM Comput. Surv., 45 (2013), 1–33. http://dx.doi.org/10.1145/2480741.2480752 doi: 10.1145/2480741.2480752
|
| [23] |
H. L. Kwa, J. Philippot, R. Bouffanais, Effect of swarm density on collective tracking performance, Swarm Intell., 17 (2023), 253–281. http://dx.doi.org/10.1007/s11721-023-00225-4 doi: 10.1007/s11721-023-00225-4
|
| [24] |
P. Joćko, B. M. Ombuki-Berman, A. P. Engelbrecht, Multi-guide particle swarm optimisation archive management strategies for dynamic optimisation problems, Swarm Intell., 16 (2022), 143–168. http://dx.doi.org/10.1007/s11721-022-00210-3 doi: 10.1007/s11721-022-00210-3
|
| [25] |
F. Yu, J. Guan, H. R. Wu, C. Y. Chen, X. W. Xia, Lens imaging opposition-based learning for differential evolution with cauchy perturbation, Appl. Soft Comput., 152 (2023), 111211. https://doi.org/10.1016/j.asoc.2023.111211 doi: 10.1016/j.asoc.2023.111211
|
| [26] |
S. Mahdavi, S. Rahnamayan, K. Deb, Opposition based learning: A literature review, Swarm Evol. Comput., 39 (2018), 1–23. http://dx.doi.org/10.1016/j.swevo.2017.09.010 doi: 10.1016/j.swevo.2017.09.010
|
| [27] |
W. Deng, S. F. Shang, X. Cai, H. M. Zhao, Y. J. Song, J. J. Xu, An improved differential evolution algorithm and its application in optimization problem, Soft Comput., 25 (2021), 5277–5298. http://dx.doi.org/10.1007/s00500-020-05527-x doi: 10.1007/s00500-020-05527-x
|
| [28] |
L. L. Kang, R. S. Chen, W. L. Cao, Y. C. Chen, Non-inertial opposition-based particle swarm optimization and its theoretical analysis for deep learning applications, Appl. Soft Comput., 88 (2020), 10. http://dx.doi.org/10.1016/j.asoc.2019.106038 doi: 10.1016/j.asoc.2019.106038
|
| [29] |
S. Dhargupta, M. Ghosh, S. Mirjalili, R. Sarkar, Selective opposition based grey wolf optimization, Expert Syst. Appl., 151 (2020), 13. http://dx.doi.org/10.1016/j.eswa.2020.113389 doi: 10.1016/j.eswa.2020.113389
|
| [30] |
A. Chatterjee, S. Ghoshal, V. Mukherjee, Solution of combined economic and emission dispatch problems of power systems by an opposition-based harmony search algorithm, Int. J. Electr. Power Energy Syst., 39 (2012), 9–20. https://doi.org/10.1016/j.ijepes.2011.12.004 doi: 10.1016/j.ijepes.2011.12.004
|
| [31] | B. Kazemi, M. Ahmadi, S. Talebi, Optimum and reliable routing in VANETs: An opposition based ant colony algorithm scheme, in 2013 International Conference on Connected Vehicles and Expo (ICCVE), (2013), 926–930. |
| [32] |
Y. Y. Zhang, Backtracking search algorithm with specular reflection learning for global optimization, Knowl.-Based Syst., 212 (2021), 17. https://doi.org/10.1016/j.knosys.2020.106546 doi: 10.1016/j.knosys.2020.106546
|
| [33] | R. Patel, M. M. Raghuwanshi, L. G. Malik, Decomposition based multi-objective genetic algorithm (DMOGA) with opposition based learning, in 2012 Fourth International Conference on Computational Intelligence and Communication Networks, (2012), 605–610. https://doi.org/10.1109/cicn.2012.79 |
| [34] |
M. Tair, N. Bacanin, M. Zivkovic, K. Venkatachalam, A chaotic oppositional whale optimisation algorithm with firefly search for medical diagnostics, Comput. Mater. Continua, 72 (2022). https://doi.org/10.32604/cmc.2022.024989 doi: 10.32604/cmc.2022.024989
|
| [35] |
L. Abualigah, A. Diabat, M. A. Elaziz, Improved slime mould algorithm by opposition-based learning and Levy flight distribution for global optimization and advances in real-world engineering problems, J. Ambient Intell. Humanized Comput., 14 (2023), 1163–1202. https://doi.org/10.1007/s12652-021-03372-w doi: 10.1007/s12652-021-03372-w
|
| [36] |
S. K. Joshi, Chaos embedded opposition based learning for gravitational search algorithm, Appl. Intell., 53 (2023), 5567–5586. https://doi.org/10.1007/s10489-022-03786-9 doi: 10.1007/s10489-022-03786-9
|
| [37] |
V. H. S. Pham, N. T. N. Dang, V. N. Nguyen, Hybrid sine cosine algorithm with integrated roulette wheel selection and opposition-based learning for engineering optimization problems, Int. J. Comput. Intell. Syst., 16 (2023), 171. https://doi.org/10.1007/s44196-023-00350-2 doi: 10.1007/s44196-023-00350-2
|
| [38] | N. Bacanin, U. Arnaut, M. Zivkovic, T. Bezdan, T. A. Rashid, Energy efficient clustering in wireless sensor networks by opposition-based initialization bat algorithm, in Computer Networks and Inventive Communication Technologies. Lecture Notes on Data Engineering and Communications Technologies (eds. S. Smys, R. Bestak, R. Palanisamy and I. Kotuliak), (2022), 1–16. https://doi.org/10.1007/978-981-16-3728-5_1 |
| [39] | T. Bezdan, A. Petrovic, M. Zivkovic, I. Strumberger, V. K. Devi, N. Bacanin, Current best opposition-based learning salp swarm algorithm for global numerical optimization, in 2021 Zooming Innovation in Consumer Technologies Conference (ZINC), (2021), 5–10. https://doi.org/10.1109/ZINC52049.2021.9499275 |
| [40] | S. J. Mousavirad, D. Oliva, S. Hinojosa, G. Schaefer, Differential evolution-based neural network training incorporating a centroid-based strategy and dynamic opposition-based learning, in 2021 IEEE Congress on Evolutionary Computation (CEC), (2021), 1233–1240. https://doi.org/10.1109/CEC45853.2021.9504801 |
| [41] | S. Rahnamayan, H. R. Tizhoosh, M. M.A. Salama, Quasi-oppositional differential evolution, in 2007 IEEE Congress on Evolutionary Computation, (2007), 2229–2236. https://doi.org/10.1109/CEC.2007.4424748 |
| [42] | M. Ergezer, D. Simon, D. Du Oppositional biogeography-based optimization, in 2009 IEEE International Conference on Systems, Man and Cybernetics, (2009), 1009–1014. https://doi.org/10.1109/ICSMC.2009.5346043 |
| [43] | H. R. Tizhoosh, M. Ventresca, S. Rahnamayan, Opposition-based computing, in Oppositional Concepts in Computational Intelligence (eds. H. R. Tizhoosh and M. Ventresca), Springer, (2008), 11–28. https://doi.org/10.1007/978-3-540-70829-2_2 |
| [44] |
H. Wang, Z. Wu, S. Rahnamayan, Enhanced opposition-based differential evolution for solving high-dimensional continuous optimization problems, Soft Comput., 15 (2010), 2127–2140. http://dx.doi.org/10.1007/s00500-010-0642-7 doi: 10.1007/s00500-010-0642-7
|
| [45] |
M. Ergezer, D. Simon, Probabilistic properties of fitness-based quasi-reflection in evolutionary algorithms, Comput. Oper. Res., 63 (2015), 114–124. http://https://doi.org/10.1016/j.cor.2015.03.013 doi: 10.1016/j.cor.2015.03.013
|
| [46] | Z. Hu, Y. Bao, T. Xiong, Partial opposition-based adaptive differential evolution algorithms: Evaluation on the CEC 2014 benchmark set for real-parameter optimization, in 2014 IEEE congress on evolutionary computation (CEC), (2014), 2259–2265. http://dx.doi.org/10.1109/CEC.2014.6900489 |
| [47] |
S. Rahnamayan, J. Jesuthasan, F. Bourennani, G. F. Naterer, H. Salehinejad, Centroid opposition-based differential evolution, Int. J. Appl. Metaheuristic Comput., 5 (2014), 1–25. http://dx.doi.org/10.4018/ijamc.2014100101 doi: 10.4018/ijamc.2014100101
|
| [48] | H. Liu, Z. Wu, H. Li, H. Wang, S. Rahnamayan, C. Deng, Rotation-based learning: A novel extension of opposition-based learning, in PRICAI 2014: Trends in Artificial Intelligence. PRICAI 2014. Lecture Notes in Computer Science (eds. D. N. Pham and S. B. Park), Springer International Publishing, (2014), 511–522. https://doi.org/10.1007/978-3-319-13560-1_41 |
| [49] |
H. Xu, C. D. Erdbrink, V. V. Krzhizhanovskaya, How to speed up optimization? Opposite-center learning and its application to differential evolution, Proc. Comput. Sci., 51 (2015), 805–814. http://doi.org/10.1016/j.procs.2015.05.203 doi: 10.1016/j.procs.2015.05.203
|
| [50] |
Z. Seif, M. B. Ahmadi, An opposition-based algorithm for function optimization, Eng. Appl. Artifi. Intell., 37 (2015), 293–306. http://dx.doi.org/10.1016/j.engappai.2014.09.009 doi: 10.1016/j.engappai.2014.09.009
|
| [51] | Q. Xu, L. Wang, B. He, N. Wang, Modified opposition-based differential evolution for function optimization, J. Comput. Inf. Syst., 7 (2011), 1582–1591. |
| [52] |
S. Y. Park, J. J. Lee, Stochastic opposition-based learning using a beta distribution in differential evolution, IEEE Trans. Cybern., 46 (2016), 2184–2194. http://dx.doi.org/10.1109/TCYB.2015.2469722 doi: 10.1109/TCYB.2015.2469722
|
| [53] |
X. Xia, L. Gui, Y. Zhang, X. Xu, F. Yu, H. Wu, et al., A fitness-based adaptive differential evolution algorithm, Inf. Sci., 549 (2021), 116–141. http://dx.doi.org/10.1016/j.ins.2020.11.015 doi: 10.1016/j.ins.2020.11.015
|
| [54] |
H. Deng, L. Peng, H. Zhang, B. Yang, Z. Chen, Ranking-based biased learning swarm optimizer for large-scale optimization, Inf. Sci., 493 (2019), 120–137. http://dx.doi.org/10.1016/j.ins.2019.04.037 doi: 10.1016/j.ins.2019.04.037
|
| [55] |
L. Gui, X. Xia, F. Yu, H. Wu, R. Wu, B. Wei, et al., A multi-role based differential evolution, Swarm Evol. Comput., 50 (2019), 100508. https://doi.org/10.1016/j.swevo.2019.03.003 doi: 10.1016/j.swevo.2019.03.003
|
| [56] |
B. Morales-Castañeda, D. Zaldívar, E. Cuevas, F. Fausto, A. Rodríguez, A better balance in metaheuristic algorithms: Does it exist?, Swarm Evol. Comput., 54 (2020), 100671. http://dx.doi.org/10.1016/j.swevo.2020.100671 doi: 10.1016/j.swevo.2020.100671
|
| [57] | G. Wu, R. Mallipeddi, P. Suganthan, Problem definitions and evaluation criteria for the CEC 2017 competition and special session on constrained single objective real-parameter optimization, Nanyang Technol. Univ. Singapore Tech. Rep., (2016), 1–18. |
| [58] |
J. Zhang, A. C. Sanderson, JADE: Adaptive differential evolution with optional external archive, IEEE Trans. Evol. Comput., 13 (2009), 945–958. http://dx.doi.org/10.1109/tevc.2009.2014613 doi: 10.1109/tevc.2009.2014613
|
| [59] |
W. Deng, H. C. Ni, Y. Liu, H. L. Chen, H. M. Zhao, An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation, Appl. Soft Comput., 127 (2022), 20. http://dx.doi.org/10.1016/j.asoc.2022.109419 doi: 10.1016/j.asoc.2022.109419
|
| [60] |
Y. L. Xu, X. F. Yang, Z. L. Yang, X. P. Li, P. Wang, R. Z. Ding, et al., An enhanced differential evolution algorithm with a new oppositional-mutual learning strategy, Neurocomputing, 435 (2021), 162–175. http://dx.doi.org/10.1016/j.neucom.2021.01.003 doi: 10.1016/j.neucom.2021.01.003
|
| [61] |
J. Li, Y. Gao, K. Wang, Y. Sun, A dual opposition-based learning for differential evolution with protective mechanism for engineering optimization problems, Appl. Soft Comput., 113 (2021), 107942. http://dx.doi.org/10.1016/j.asoc.2021.107942 doi: 10.1016/j.asoc.2021.107942
|
| [62] |
X. C. Zhao, S. Feng, J. L. Hao, X. Q. Zuo, Y. Zhang, Neighborhood opposition-based differential evolution with gaussian perturbation, Soft Comput., 25 (2021), 27–46. http://dx.doi.org/10.1007/s00500-020-05425-2 doi: 10.1007/s00500-020-05425-2
|
| [63] |
J. Derrac, S. García, D. Molina, F. Herrera, A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms, Swarm Evol. Comput., 1 (2011), 3–18. http://dx.doi.org/10.1016/j.swevo.2011.02.002 doi: 10.1016/j.swevo.2011.02.002
|
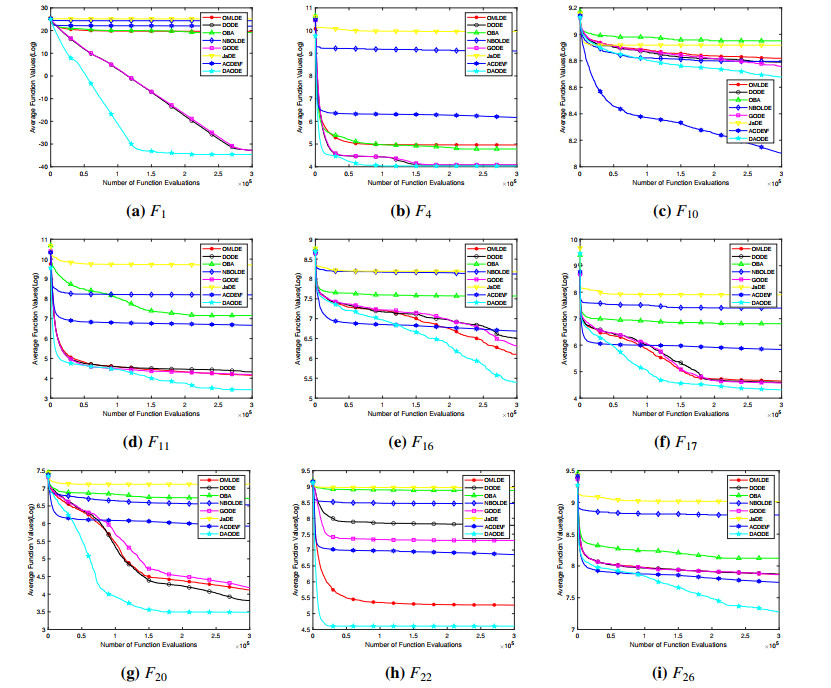
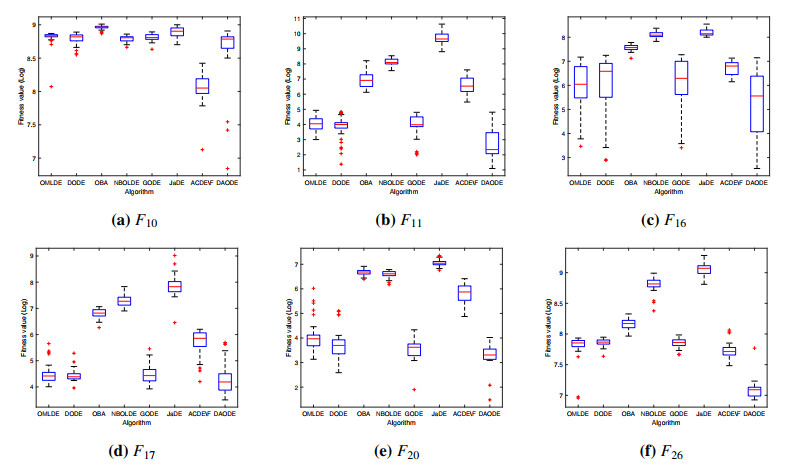
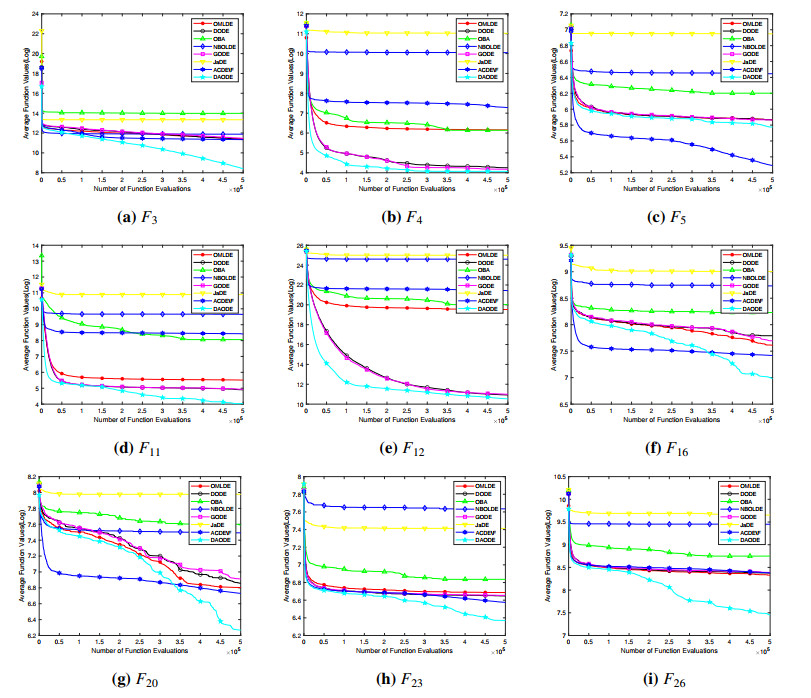
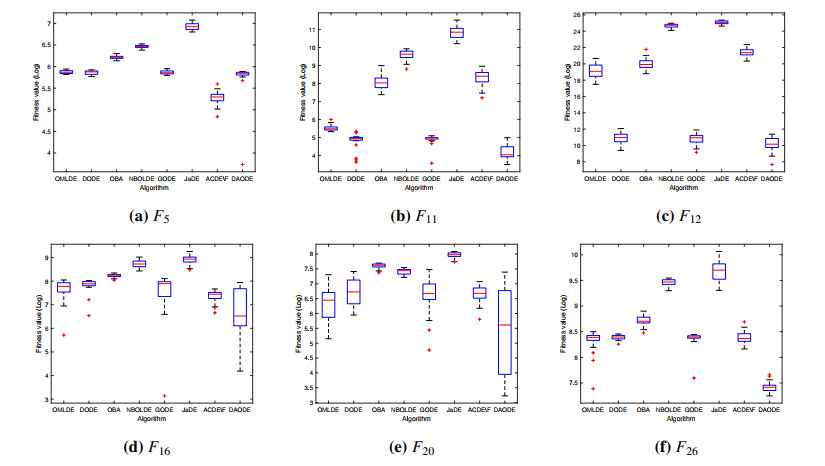
Figures(10) / Tables(14)
Jian Guan, Fei Yu, Hongrun Wu, Yingpin Chen, Zhenglong Xiang, Xuewen Xia, Yuanxiang Li. Dynamic allocation of opposition-based learning in differential evolution for multi-role individuals[J]. Electronic Research Archive, 2024, 32(5): 3241-3274. doi: 10.3934/era.2024149







 DownLoad:
DownLoad: