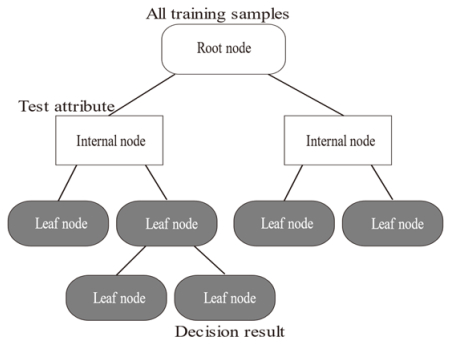
Accurate and effective landslide prediction and early detection of potential geological hazards are of great importance for landslide hazard prevention and control. However, due to the hidden, sudden, and uncertain nature of landslide disasters, traditional geological survey and investigation methods are time-consuming and laborious, and it is difficult to timely and accurately investigate and predict slope stability over a large area. Machine learning approaches provide an opportunity to address this limitation. Here, we present an intelligent slope stability assessment method based on a genetic algorithm optimization of random forest algorithm (GA-RF algorithm). Based on 80 sets of typical slope samples, weight (γ), slope height (H), pore pressure value (P), cohesion force (C), internal friction angle (φ) and slope inclination angle (°) were selected as characteristic variables for slope stability evaluation. Based on the GA-RF algorithm and incorporating 10-fold cross validation, a regression prediction model is trained on the training dataset, and then regression prediction is performed on the test dataset to verify the predictive performance of the model. The results indicate that the GA-RF prediction model has decent regression performance and has certain potential for slope stability analysis.
Citation: Shengming Hu, Yongfei Lu, Xuanchi Liu, Cheng Huang, Zhou Wang, Lei Huang, Weihang Zhang, Xiaoyang Li. Stability prediction of circular sliding failure soil slopes based on a genetic algorithm optimization of random forest algorithm[J]. Electronic Research Archive, 2024, 32(11): 6120-6139. doi: 10.3934/era.2024284
Accurate and effective landslide prediction and early detection of potential geological hazards are of great importance for landslide hazard prevention and control. However, due to the hidden, sudden, and uncertain nature of landslide disasters, traditional geological survey and investigation methods are time-consuming and laborious, and it is difficult to timely and accurately investigate and predict slope stability over a large area. Machine learning approaches provide an opportunity to address this limitation. Here, we present an intelligent slope stability assessment method based on a genetic algorithm optimization of random forest algorithm (GA-RF algorithm). Based on 80 sets of typical slope samples, weight (γ), slope height (H), pore pressure value (P), cohesion force (C), internal friction angle (φ) and slope inclination angle (°) were selected as characteristic variables for slope stability evaluation. Based on the GA-RF algorithm and incorporating 10-fold cross validation, a regression prediction model is trained on the training dataset, and then regression prediction is performed on the test dataset to verify the predictive performance of the model. The results indicate that the GA-RF prediction model has decent regression performance and has certain potential for slope stability analysis.

| [1] |
Y. Yang, W. Zhou, I. M. Jiskani, X. Lu, Z. Wang, B. Luan, Slope stability prediction method based on intelligent optimization and machine learning algorithms, Sustainability, 15 (2023), 1169. https://doi.org/10.3390/SU15021169 doi: 10.3390/SU15021169

|
| [2] |
W. Zhang, H. Li, L. Han, L. Chen, L. Wang, Slope stability prediction using ensemble learning techniques: A case study in Yunyang County, Chongqing, China, J. Rock Mech. Geotech. Eng., 14 (2022), 1089–1099. https://doi.org/10.1016/J.JRMGE.2021.12.011 doi: 10.1016/J.JRMGE.2021.12.011
|
| [3] |
F. S. Tehrani, M. Calvello, Z. Liu, L. Zhang, S. Lacasse, Machine learning and landslide studies: recent advances and applications, Nat. Hazards, 114 (2022), 1197–1245. https://doi.org/10.1007/s11069-022-05423-7 doi: 10.1007/s11069-022-05423-7
|
| [4] |
W. Zhang, X. Gu, L. Hong, L. Han, L. Wang, Comprehensive review of machine learning in geotechnical reliability analysis: Algorithms, applications and further challenges, Appl. Soft Comput., 136 (2023), 110066. https://doi.org/10.1016/j.asoc.2023.110066 doi: 10.1016/j.asoc.2023.110066
|
| [5] |
H. Moayedi, D. Tien Bui, M. Gör, B. Pradhan, A. Jaafari, The feasibility of three prediction techniques of the artificial neural network, adaptive neuro-fuzzy inference system, and hybrid particle swarm optimization for assessing the safety factor of cohesive slopes, ISPRS Int. J. Geo-Inf., 8 (2019), 391. https://doi.org/10.3390/ijgi8090391 doi: 10.3390/ijgi8090391
|
| [6] |
H. Moayedi, D. Tien Bui, B. Kalantar, L. Kok Foong, Machine-learning-based classification approaches toward recognizing slope stability failure, Appl. Sci., 9 (2019), 4638. https://doi.org/10.3390/app9214638 doi: 10.3390/app9214638
|
| [7] |
N. Kardani, A. Zhou, M. Nazem, S. L. Shen, Improved prediction of slope stability using a hybrid stacking ensemble method based on finite element analysis and field data, J. Rock Mech. Geotech. Eng., 13 (2021), 188–201. https://doi.org/10.1016/J.JRMGE.2020.05.011 doi: 10.1016/J.JRMGE.2020.05.011
|
| [8] |
A. Mahmoodzadeh, M. Mohammadi, H. Farid Hama Ali, H. Hashim Ibrahim, S. Nariman Abdulhamid, H. R. Nejati, Prediction of safety factors for slope stability: comparison of machine learning techniques, Nat. Hazards, 111 (2022), 1771–1799. https://doi.org/10.1007/S11069-021-05115-8 doi: 10.1007/S11069-021-05115-8
|
| [9] |
Z. Ma, G. Mei, Deep learning for geological hazards analysis: Data, models, applications, and opportunities, Earth Sci. Rev., 223 (2021), 103858. https://doi.org/10.1016/j.earscirev.2021.103858 doi: 10.1016/j.earscirev.2021.103858
|
| [10] |
Y. Ahangari Nanehkaran, T. Pusatli, C. Jin, J. Chen, A. Cemiloglu, M. Azarafza, et al., Application of machine learning techniques for the estimation of the safety factor in slope stability analysis, Water, 14 (2022), 3743. https://doi.org/10.3390/W14223743 doi: 10.3390/W14223743
|
| [11] |
M. Habib, B. Bashir, A. Alsalman, H. Bachir, Evaluating the accuracy and effectiveness of machine learning methods for rapidly determining the safety factor of road embankments, Multidiscip. Model. Mater. Struct., 19 (2023), 966–983. https://doi.org/10.1108/MMMS-12-2022-0290 doi: 10.1108/MMMS-12-2022-0290
|
| [12] |
V. Bansal, R. Sarkar, Prophetical modeling using limit equilibrium method and novel machine learning ensemble for slope stability gauging in Kalimpong, Iran. J. Sci. Technol. Trans. Civ. Eng., 48 (2024), 411–430. https://doi.org/10.1007/S40996-023-01156-0 doi: 10.1007/S40996-023-01156-0
|
| [13] |
W. Lin, D. Zhong, W. Hu, P. Lv, B. Ren, Study on dynamic evaluation of compaction quality of earth rock dam based on random forest, J. Hydraul. Eng., 49 (2018), 945–955. https://doi.org/10.13243/j.cnki.slxb.20171193 doi: 10.13243/j.cnki.slxb.20171193
|
| [14] |
H. Xie, J. Dong, Y. Deng, Y. Dai, Prediction model of the slope angle of rocky slope stability based on random forest algorithm, Math. Probl. Eng., 2022 (2022), 1–10. https://doi.org/10.1155/2022/9441411 doi: 10.1155/2022/9441411
|
| [15] | X. T. Feng, Introduction of Intelligent Rock Mechanics, Science Press, Beijing, (2000), 104–108. |
| [16] |
R. K. Fang, Y. H. Liu, Z. Huang, Review of regional landslide risk assessment methods based on machine learning, Chin. J. Geol. Hazard Control, 32 (2021), 1–5. https://doi.org/10.16031/j.cnki.issn.1003-8035.2021.04-01 doi: 10.16031/j.cnki.issn.1003-8035.2021.04-01
|
| [17] |
J. Dou, Z. Xiang, Q. Xu, P. Zheng, X. Wang, A. Su, et al., Application and development trend of machine learning in landslide intelligent disaster prevention and mitigation, Earth Sci., 48 (2023), 1657–1674. https://doi.org/10.3799/dqkx.2022.419 doi: 10.3799/dqkx.2022.419
|
| [18] |
J. Gong, Y. Li, Can quantitative remote sensing and machine learning be integrated, Earth Sci., 47 (2022), 3911–3912. https://doi.org/10.3799/dqkx.2022.861 doi: 10.3799/dqkx.2022.861
|






Figures(7) / Tables(4)
Shengming Hu, Yongfei Lu, Xuanchi Liu, Cheng Huang, Zhou Wang, Lei Huang, Weihang Zhang, Xiaoyang Li. Stability prediction of circular sliding failure soil slopes based on a genetic algorithm optimization of random forest algorithm[J]. Electronic Research Archive, 2024, 32(11): 6120-6139. doi: 10.3934/era.2024284







 DownLoad:
DownLoad: