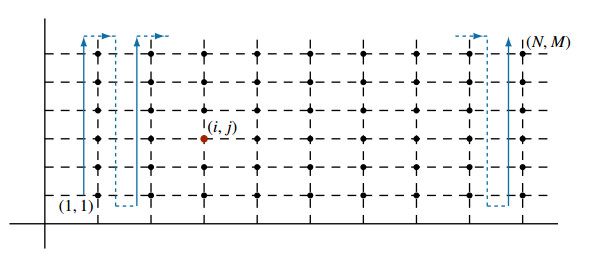
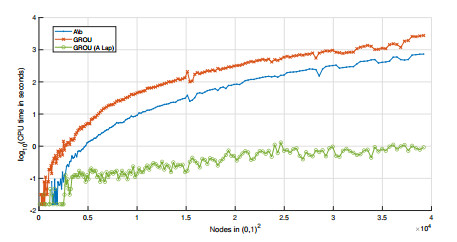
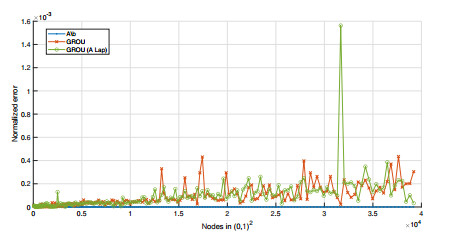
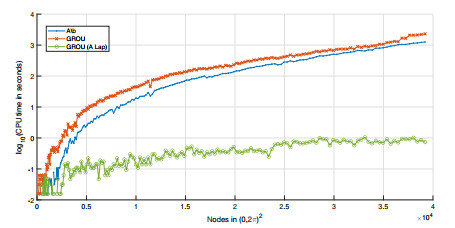
Algorithms that use tensor decompositions are widely used due to how well they perfor with large amounts of data. Among them, we find the algorithms that search for the solution of a linear system in separated form, where the greedy rank-one update method stands out, to be the starting point of the famous proper generalized decomposition family. When the matrices of these systems have a particular structure, called a Laplacian-like matrix which is related to the aspect of the Laplacian operator, the convergence of the previous method is faster and more accurate. The main goal of this paper is to provide a procedure that explicitly gives, for a given square matrix, its best approximation to the set of Laplacian-like matrices. Clearly, if the residue of this approximation is zero, we will be able to solve, by using the greedy rank-one update algorithm, the associated linear system at a lower computational cost. As a particular example, we prove that the discretization of a general partial differential equation of the second order without mixed derivatives can be written as a linear system with a Laplacian-type matrix. Finally, some numerical examples based on partial differential equations are given.
Citation: J. Alberto Conejero, Antonio Falcó, María Mora–Jiménez. A pre-processing procedure for the implementation of the greedy rank-one algorithm to solve high-dimensional linear systems[J]. AIMS Mathematics, 2023, 8(11): 25633-25653. doi: 10.3934/math.20231308
Algorithms that use tensor decompositions are widely used due to how well they perfor with large amounts of data. Among them, we find the algorithms that search for the solution of a linear system in separated form, where the greedy rank-one update method stands out, to be the starting point of the famous proper generalized decomposition family. When the matrices of these systems have a particular structure, called a Laplacian-like matrix which is related to the aspect of the Laplacian operator, the convergence of the previous method is faster and more accurate. The main goal of this paper is to provide a procedure that explicitly gives, for a given square matrix, its best approximation to the set of Laplacian-like matrices. Clearly, if the residue of this approximation is zero, we will be able to solve, by using the greedy rank-one update algorithm, the associated linear system at a lower computational cost. As a particular example, we prove that the discretization of a general partial differential equation of the second order without mixed derivatives can be written as a linear system with a Laplacian-type matrix. Finally, some numerical examples based on partial differential equations are given.

| [1] |
A. Fawzi, M. Balog, A. Huang, T. Hubert, B. Romera-Paredes, M. Barekatain, et al., Discovering faster matrix multiplication algorithms with reinforcement learning, Nature, 610 (2022), 47–53. https://doi.org/10.1038/s41586-022-05172-4 doi: 10.1038/s41586-022-05172-4

|
| [2] |
G. Heidel, V. Khoromskaia, B. Khoromskij, V. Schulz, Tensor product method for fast solution of optimal control problems with fractional multidimensional Laplacian in constraints, J. Comput. Phys., 424 (2021), 109865. https://doi.org/10.1016/j.jcp.2020.109865 doi: 10.1016/j.jcp.2020.109865
|
| [3] |
C. Quesada, G. Xu, D. González, I. Alfaro, A. Leygue, M. Visonneau, et al., Un método de descomposición propia generalizada para operadores diferenciales de alto orden, Rev. Int. Metod. Numer., 31 (2015), 188–197. https://doi.org/10.1016/j.rimni.2014.09.001 doi: 10.1016/j.rimni.2014.09.001
|
| [4] | A. Nouy, Low-rank methods for high-dimensional approximation and model order reduction, Soc. Ind. Appl. Math., 2017,171–226. |
| [5] |
A. Falcó, A. Nouy, Proper generalized decomposition for nonlinear convex problems in tensor Banach spaces, Numer. Math., 121 (2012), 503–530. https://doi.org/10.1007/s00211-011-0437-5 doi: 10.1007/s00211-011-0437-5
|
| [6] |
I. Georgieva, C. Hofreither, Greedy low-rank approximation in Tucker format of solutions of tensor linear systems, J. Comput. Appl. Math., 358 (2019), 206–220. https://doi.org/10.1016/j.cam.2019.03.002 doi: 10.1016/j.cam.2019.03.002
|
| [7] |
A. Ammar, F. Chinesta, A. Falcó, On the convergence of a Greedy Rank-One Update algorithm for a class of linear systems, Arch. Comput. Methods Eng., 17 (2010), 473–486. https://doi.org/10.1007/s11831-010-9048-z doi: 10.1007/s11831-010-9048-z
|
| [8] |
J. A. Conejero, A. Falcó, M. Mora-Jiménez, Structure and approximation properties of laplacian-like matrices, Results Math., 78 (2023), 184. https://doi.org/10.1007/s00025-023-01960-0 doi: 10.1007/s00025-023-01960-0
|
| [9] | J. Swift, P. C. Hohenberg, Hydrodynamic fluctuations at the convective instability, Phys. Rev. A, 15 (1977), 319–328. |
| [10] |
V. de Silva, L. H. Lim, Tensor rank and the ill-posedness of the best low-rank approximation problem, SIAM J. Matrix Anal. Appl., 30 (2008), 1084–1127. https://doi.org/10.1137/06066518X doi: 10.1137/06066518X
|
| [11] |
A. Falcó, L. Hilario, N. Montés, M. Mora, Numerical strategies for the galerkin–proper generalized decomposition method, Math. Comput. Model., 57 (2013), 1694–1702. https://doi.org/10.1016/j.mcm.2011.11.012 doi: 10.1016/j.mcm.2011.11.012
|
| [12] |
W. Hackbusch, B. Khoromskij, S. Sauter, E. Tyrtyshnikov, Use of tensor formats in elliptic eigenvalue problems, Numer. Lin. Algebra Appl., 19 (2012), 133–151. https://doi.org/10.1002/nla.793 doi: 10.1002/nla.793
|
| [13] | MATLAB, version R2021b, The MathWorks Inc., Natick, Massachusetts, 2021. |
Figures(5) / Tables(2)

J. Alberto Conejero, Antonio Falcó, María Mora–Jiménez. A pre-processing procedure for the implementation of the greedy rank-one algorithm to solve high-dimensional linear systems[J]. AIMS Mathematics, 2023, 8(11): 25633-25653. doi: 10.3934/math.20231308







 DownLoad:
DownLoad: