In cluster synchronization (CS), the constituents (i.e., multiple agents) are grouped into a number of clusters in accordance with a function of nodes pertaining to a network structure. By designing an appropriate algorithm, the cluster can be manipulated to attain synchronization with respect to a certain value or an isolated node. Moreover, the synchronization values among various clusters vary. The main aim of this study is to investigate the asymptotic and CS problem of coupled delayed complex-valued neural network (CCVNN) models along with leakage delay in finite-time (FT). In this paper, we describe several sufficient conditions for asymptotic synchronization by utilizing the Lyapunov theory for differential systems and the Filippov regularization framework for the realization of finite-time synchronization of CCVNNs with leakage delay. We also propose sufficient conditions for CS of the system under scrutiny. A synchronization algorithm is developed to indicate the usefulness of the theoretical results in case studies.
Citation: N. Jayanthi, R. Santhakumari, Grienggrai Rajchakit, Nattakan Boonsatit, Anuwat Jirawattanapanit. Cluster synchronization of coupled complex-valued neural networks with leakage and time-varying delays in finite-time[J]. AIMS Mathematics, 2023, 8(1): 2018-2043. doi: 10.3934/math.2023104
In cluster synchronization (CS), the constituents (i.e., multiple agents) are grouped into a number of clusters in accordance with a function of nodes pertaining to a network structure. By designing an appropriate algorithm, the cluster can be manipulated to attain synchronization with respect to a certain value or an isolated node. Moreover, the synchronization values among various clusters vary. The main aim of this study is to investigate the asymptotic and CS problem of coupled delayed complex-valued neural network (CCVNN) models along with leakage delay in finite-time (FT). In this paper, we describe several sufficient conditions for asymptotic synchronization by utilizing the Lyapunov theory for differential systems and the Filippov regularization framework for the realization of finite-time synchronization of CCVNNs with leakage delay. We also propose sufficient conditions for CS of the system under scrutiny. A synchronization algorithm is developed to indicate the usefulness of the theoretical results in case studies.

| [1] |
R. Manivannan, S. Panda, K. T. Chong, J. Cao, An Arcak-type state estimation design for time-delayed static neural networks with leakage term based on unified criteria, Neural Networks, 106 (2018), 110–126. https://doi.org/10.1016/j.neunet.2018.06.015 doi: 10.1016/j.neunet.2018.06.015

|
| [2] |
X. Zhang, C. Li, Z. He, Cluster synchronization of delayed coupled neural networks: Delay-dependent distributed impulsive control, Neural Networks, 142 (2021), 34–43. https://doi.org/10.1016/j.neunet.2021.04.026 doi: 10.1016/j.neunet.2021.04.026
|
| [3] |
W. Zhou, Y. Sun, X. Zhang, P. Shi, Cluster synchronization of coupled neural networks with Lévy noise via event-triggered pinning control, IEEE Transl. Neural Networks Learn. Syst., 106 (2021), 1–14. https://doi.org/10.1109/TNNLS.2021.3072475 doi: 10.1109/TNNLS.2021.3072475
|
| [4] |
X. Qi, H. Bao, J. Cao, Synchronization criteria for quaternion-valued coupled neural networks with impulses, Neural Networks, 128 (2020), 150–157. https://doi.org/10.1016/j.neunet.2020.04.027 doi: 10.1016/j.neunet.2020.04.027
|
| [5] |
A. Pratap, R. Raja, R. Agarwal, J. Cao, O. Bagdasar, Multi-weighted complex structure on fractional order coupled neural networks with linear coupling delay: A robust synchronization problem, Neural Process. Lett., 51 (2020), 2453–2479. https://doi.org/10.1007/s11063-019-10188-5 doi: 10.1007/s11063-019-10188-5
|
| [6] |
H. E. Elzain, S. Y. Chung, V. Senapathi, S. Sekar, N. Park, A. A. Mahmoud, Modeling of aquifer vulnerability index using deep learning neural networks coupling with optimization algorithms, Environ. Sci. Pollut. Res., 28 (2021), 57030–57045. https://doi.org/10.1007/s11356-021-14522-0 doi: 10.1007/s11356-021-14522-0
|
| [7] |
J. Xia, Y. Lu, L. Tan, Research of multimodal medical image fusion based on parameter-adaptive pulse-coupled neural network and convolutional sparse representation, Comput. Math. Methods Med., 2020 (2020), 3290136. https://doi.org/10.1155/2020/3290136 doi: 10.1155/2020/3290136
|
| [8] |
P. Chanthorn, G. Rajchakit, J. Thipcha, C. Emharuethai, R. Sriraman, C. P. Lim, R. Ramachandran, Robust stability of complex-valued stochastic neural networks with time-varying delays and parameter uncertainties, Mathematics, 8 (2020), 742. https://doi.org/10.3390/math8050742 doi: 10.3390/math8050742
|
| [9] |
G. Rajchakit, R. Sriraman, Robust passivity and stability analysis of uncertain complex-valued impulsive neural networks with time-varying delays, Neural Process. Lett., 53 (2021), 581–606. https://doi.org/10.1007/s11063-020-10401-w doi: 10.1007/s11063-020-10401-w
|
| [10] |
P. Chanthorn, G. Rajchakit, U. Humphries, P. Kaewmesri, R. Sriraman, C. P. Lim, A delay-dividing approach to robust stability of uncertain stochastic complex-valued hopfield delayed neural networks, Symmetry, 12 (2020), 683. https://doi.org/10.3390/sym12050683 doi: 10.3390/sym12050683
|
| [11] |
P. Chanthorn, G. Rajchakit, S. Ramalingam, C. P. Lim, R. Ramachandran, Robust dissipativity analysis of hopfield-type complex-valued neural networks with time-varying delays and linear fractional uncertainties, Mathematics, 8 (2020), 595. https://doi.org/10.3390/math8040595 doi: 10.3390/math8040595
|
| [12] |
L. Li, X. Shi, J. Liang, Synchronization of impulsive coupled complex-valued neural networks with delay: the matrix measure method, Neural Networks, 117 (2019), 285–294. https://doi.org/10.1016/j.neunet.2019.05.024 doi: 10.1016/j.neunet.2019.05.024
|
| [13] |
M. Hymavathi, G. Muhiuddin, M. Syed Ali, J. F. Al-Amri, N. Gunasekaran, R. Vadivel, Global exponential stability of fractional order complex-valued neural networks with leakage delay and mixed time varying delays, Fractal Fract., 6 (2022), 140. https://doi.org/10.3390/fractalfract6030140 doi: 10.3390/fractalfract6030140
|
| [14] |
N. Gunasekaran, G. Zhai, Sampled-data state-estimation of delayed complex-valued neural networks, Int. J. Syst. Sci., 51 (2020), 303–312. https://doi.org/10.1080/00207721.2019.1704095 doi: 10.1080/00207721.2019.1704095
|
| [15] |
R. Samidurai, R. Sriraman, J. Cao, Z. Tu, Effects of leakage delay on global asymptotic stability of complex‐valued neural networks with interval time‐varying delays via new complex‐valued Jensen's inequality, Int. J. Adapt. Control Signal Process., 32 (2018), 1294–312. https://doi.org/10.1002/acs.2914 doi: 10.1002/acs.2914
|
| [16] |
N. Gunasekaran, G. Zhai, Stability analysis for uncertain switched delayed complex-valued neural networks, Neurocomputing, 367 (2019), 198-206. https://doi.org/10.1016/j.neucom.2019.08.030 doi: 10.1016/j.neucom.2019.08.030
|
| [17] |
Y. Huang, J. Hou, E. Yang, Passivity and synchronization of coupled reaction-diffusion complex-valued memristive neural networks, Appl. Math. Comput., 379 (2020), 125271. https://doi.org/10.1016/j.amc.2020.125271 doi: 10.1016/j.amc.2020.125271
|
| [18] |
L. Feng, C. Hu, J. Yu, H. Jiang, S. Wen, Fixed-time synchronization of coupled memristive complex-valued neural networks, Chaos Solitons Fract., 148 (2021), 110993. https://doi.org/10.1016/j.chaos.2021.110993 doi: 10.1016/j.chaos.2021.110993
|
| [19] | W. Rudin, Real and complex analysis, McGraw-Hill, 1987. |
| [20] |
N. Benvenuto, F. Piazza, On the complex backpropagation algorithm, IEEE Trans. Signal Process., 40 (1992), 967–969. https://doi.org/10.1109/78.127967 doi: 10.1109/78.127967
|
| [21] |
T. Nitta, Solving the XOR problem and the detection of symmetry using a single complex-valued neuron, Neural Networks, 16 (2003), 1101–1105. https://doi.org/10.1016/S0893-6080(03)00168-0 doi: 10.1016/S0893-6080(03)00168-0
|
| [22] |
M. Takeda, T. Kishigami, Complex neural fields with a hopfield-like energy function and an analogy to optical fields generated in phase-conjugate resonators, J. Opt. Soc. Am., 9 (1992), 2182–2191. https://doi.org/10.1364/JOSAA.9.002182 doi: 10.1364/JOSAA.9.002182
|
| [23] |
A. Pratap, R. Raja, J. Alzabut, J. Dianavinnarasi, J. Cao, G. Rajchakit, Finite-time Mittag-Leffler stability of fractional-order quaternion-valued memristive neural networks with impulses, Neural Process. Lett., 51 (2020), 1485–1526. https://doi.org/10.1007/s11063-019-10154-1 doi: 10.1007/s11063-019-10154-1
|
| [24] |
G. Rajchakit, P. Chanthorn, P. Kaewmesri, R. Sriraman, C.P. Lim, Global Mittag-Leffler stability and stabilization analysis of fractional-order quaternion-valued memristive neural networks, Mathematics, 8 (2020), 422. https://doi.org/10.3390/math8030422 doi: 10.3390/math8030422
|
| [25] |
N. Gunasekaran, N. M. Thoiyab, P. Muruganantham, G. Rajchakit, B. Unyong, Novel results on global robust stability analysis for dynamical delayed neural networks under parameter uncertainties, IEEE Access, 8 (2020), 178108–178116. https://doi.org/10.1109/ACCESS.2020.3016743 doi: 10.1109/ACCESS.2020.3016743
|
| [26] |
U. Humphries, G. Rajchakit, P. Kaewmesri, P. Chanthorn, R. Sriraman, R. Samidurai, et al., Global stability analysis of fractional-order quaternion-valued bidirectional associative memory neural networks, Mathematics, 8 (2020), 801. https://doi.org/10.3390/math8050801 doi: 10.3390/math8050801
|
| [27] | U. Humphries, G. Rajchakit, P. Kaewmesri, P. Chanthorn, R. Sriraman, R. Samidurai et al., Stochastic memristive quaternion-valued neural networks with time delays: An analysis on mean square exponential input-to-state stability, Mathematics, 8 (2020) 815. https://doi.org/10.3390/math8050815 |
| [28] |
W. W. Zhang, H. Zhang, J. D. Cao, H. M. Zhang, D. Y. Chen, Synchronization of delayed fractional-order complex-valued neural networks with leakage delay, Phys. A Stat. Mech. Appl., 556 (2020), 124710. https://doi.org/10.1016/j.physa.2020.124710 doi: 10.1016/j.physa.2020.124710
|
| [29] |
P. Anbalagan, R. Ramachandran, J. Cao, G. Rajchakit, C. P. Lim, Global robust synchronization of fractional order complex valued neural networks with mixed time varying delays and impulses, Int. J. Control Autom. Syst., 17 (2019), 509–520. https://doi.org/10.1007/s12555-017-0563-7 doi: 10.1007/s12555-017-0563-7
|
| [30] |
N. Gunasekaran, G. Zhai, Q. Yu, Sampled-data synchronization of delayed multi-agent networks and its application to coupled circuit, Neurocomputing, 413 (2020), 499–511. https://doi.org/10.1016/j.neucom.2020.05.060 doi: 10.1016/j.neucom.2020.05.060
|
| [31] |
R. Vadivel, P. Hammachukiattikul, N. Gunasekaran, R. Saravanakumar, H. Dutta, Strict dissipativity synchronization for delayed static neural networks: An event-triggered scheme, Chaos Solitons Fract., 150 (2021), 111212. https://doi.org/10.1016/j.chaos.2021.111212 doi: 10.1016/j.chaos.2021.111212
|
| [32] |
M. Syed Ali, N. Gunasekaran, R. Agalya, Y. H. Joo, Non-fragile synchronisation of mixed delayed neural networks with randomly occurring controller gain fluctuations, Int. J. Syst. Sci., 49 (2018), 3354–3364. https://doi.org/10.1080/00207721.2018.1540730 doi: 10.1080/00207721.2018.1540730
|
| [33] |
R. Guo, S. Xu, J. Guo, Sliding-mode synchronization control of complex-valued inertial neural networks with leakage delay and time-varying delays, IEEE Trans. Syst. Man Cybern. Syst., 2022, 1–9. https://doi.org/10.1109/TSMC.2022.3193306 doi: 10.1109/TSMC.2022.3193306
|
| [34] |
N. Jayanthi, R. Santhakumari, Synchronization of time-varying time delayed neutral-type neural networks for finite-time in complex field, Math. Model. Comput., 8 (2021), 486–498. https://doi.org/10.23939/mmc2021.03.486 doi: 10.23939/mmc2021.03.486
|
| [35] |
N. Jayanthi, R. Santhakumari, Synchronization of time invariant uncertain delayed neural networks in finite time via improved sliding mode control, Math. Model. Comput., 8 (2021), 228–240. https://doi.org/10.23939/mmc2021.02.228 doi: 10.23939/mmc2021.02.228
|
| [36] |
R. Anbuvithya, S. Dheepika Sri, R. Vadivel, P. Hammachukiattikul, C. Park, G. Nallappan, Extended dissipativity synchronization for Markovian jump recurrent neural networks via memory sampled-data control and its application to circuit theory, Int. J. Nonlinear Anal. Appl., 13 (2022), 2801–2820. https://doi.org/10.22075/IJNAA.2021.25114.2919 doi: 10.22075/IJNAA.2021.25114.2919
|
| [37] |
J. Bai, H. Wu, J. Cao, Secure synchronization and identification for fractional complex networks with multiple weight couplings under DoS attacks, Comput. Appl. Math., 41 (2022), 187. https://doi.org/10.1007/s40314-022-01895-2 doi: 10.1007/s40314-022-01895-2
|
| [38] |
Z. Ruan, Y. Li, J. Hu, J. Mei, D. Xia, Finite-time synchronization of the drive-response networks by event-triggered aperiodic intermittent control, Neurocomputing, 485 (2022), 89–102 https://doi.org/10.1016/j.neucom.2022.02.037 doi: 10.1016/j.neucom.2022.02.037
|
| [39] |
N. Gunasekaran, R. Saravanakumar, Y. H. Joo, H. S. Kim, Finite-time synchronization of sampled-data T–S fuzzy complex dynamical networks subject to average dwell-time approach, Fuzzy Sets Syst., 374 (2019), 40–59. https://doi.org/10.1016/j.fss.2019.01.007 doi: 10.1016/j.fss.2019.01.007
|
| [40] |
C. Wang, H. Zhang, I. Stamova, J. Cao, Global synchronization for BAM delayed reaction-diffusion neural networks with fractional partial differential operator, J. Franklin Inst., 2022. https://doi.org/10.1016/j.jfranklin.2022.08.038 doi: 10.1016/j.jfranklin.2022.08.038
|
| [41] |
H. Zhang, Y. Cheng, H. Zhang, W. Zhang, J. Cao, Hybrid control design for Mittag-Leffler projective synchronization on FOQVNNs with multiple mixed delays and impulsive effects, Math. Comput. Simul., 197 (2022), 341–357. https://doi.org/10.1016/j.matcom.2022.02.022 doi: 10.1016/j.matcom.2022.02.022
|
| [42] |
X. Li, H. Wu, J. Cao, Prescribed-time synchronization in networks of piecewise smooth systems via a nonlinear dynamic event-triggered control strategy, Math. Comput. Simul., 203 (2023), 647-668. https://doi.org/10.1016/j.matcom.2022.07.010 doi: 10.1016/j.matcom.2022.07.010
|
| [43] |
M. Syed Ali, M. Hymavathi, G. Rajchakit, S. Saroha, L. Palanisamy, P. Hammachukiattikul, Synchronization of fractional order fuzzy BAM neural networks with time varying delays and reaction diffusion terms, IEEE Access, 8 (2020), 186551–186571. https://doi.org/10.1109/ACCESS.2020.3029145 doi: 10.1109/ACCESS.2020.3029145
|
| [44] |
D. Liu, S. Zhu, K. Sun, Global anti-synchronization of complex-valued memristive neural networks with time delays, IEEE Trans. Cybern., 49 (2019), 1735–1747. https://doi.org/10.1109/TCYB.2018.2812708 doi: 10.1109/TCYB.2018.2812708
|
| [45] |
B. Hu, Z. Guan, N. Xiong, H. Chao, Intelligent impulsive synchronization of nonlinear interconnected neural networks for image protection, IEEE Trans. Ind. Inf., 14 (2018), 3775–3787. https://doi.org/10.1109/TII.2018.2808966 doi: 10.1109/TII.2018.2808966
|
| [46] |
L. V. Gambuzza, M. Frasca, A criterion for stability of cluster synchronization in networks with external equitable partitions, Automatica, 100 (2019), 212–218. https://doi.org/10.1016/j.automatica.2018.11.026 doi: 10.1016/j.automatica.2018.11.026
|
| [47] |
J. Qin, W. Fu, Y. Shi, H. Gao, Y. Kang, Leader-following practical cluster synchronization for networks of generic linear systems: An event-based approach, IEEE Trans. Neural Networks Learn. Syst., 30 (2018), 215–224. https://doi.org/10.1109/TNNLS.2018.2817627 doi: 10.1109/TNNLS.2018.2817627
|
| [48] |
N. A. Lai, W. Xiang, Y. Zhou, Global instability of multi-dimensional plane shocks for isothermal flow, Acta Math. Sci., 42 (2022), 887–902. https://doi.org/10.1007/s10473-022-0305-7 doi: 10.1007/s10473-022-0305-7
|
| [49] |
Z. Zhang, H. Wu, Cluster synchronization in finite/fixed time for semi-Markovian switching TS fuzzy complex dynamical networks with discontinuous dynamic nodes, AIMS Math., 7 (2022), 11942–11971. https://doi.org/10.3934/math.2022666 doi: 10.3934/math.2022666
|
| [50] |
P. Liu, Z. Zeng, J. Wang, Asymptotic and finite-time cluster synchronization of coupled fractional order neural networks with time delay, IEEE Trans. Neural Networks Learn. Syst., 31 (2020), 4956–4967. https://doi.org/10.1109/TNNLS.2019.2962006 doi: 10.1109/TNNLS.2019.2962006
|
| [51] |
X. Zhang, C. Li, Z. He, Cluster synchronization of delayed coupled neural networks: Delay-dependent distributed impulsive control, Neural Networks, 142 (2021), 34–43. https://doi.org/10.1016/j.neunet.2021.04.026 doi: 10.1016/j.neunet.2021.04.026
|
| [52] |
S. Yang, C. Hu, J. Yu, H. Jiang, Finite-time cluster synchronization in complex-variable networks with fractional-order and nonlinear coupling, Neural Networks, 135 (2021), 212–224. https://doi.org/10.1016/j.neunet.2020.12.015 doi: 10.1016/j.neunet.2020.12.015
|
| [53] |
T. Yu, J. Cao, C. Huang, Finite-time cluster synchronization of coupled dynamical systems with impulsive effects, Discrete Contin. Dyn. Syst. B, 26 (2021), 3595–3620. https://doi.org/10.3934/dcdsb.2020248 doi: 10.3934/dcdsb.2020248
|
| [54] |
J. J. He, Y. Q. Lin, M. F. Ge, C. D. Liang, T. F. Ding, L. Wang, Adaptive finite-time cluster synchronization of neutral-type coupled neural networks with mixed delays, Neurocomputing, 384 (2020), 11–20. https://doi.org/10.1016/j.neucom.2019.11.046 doi: 10.1016/j.neucom.2019.11.046
|
| [55] |
R. Tang, X. Yang, X. Wan, Finite-time cluster synchronization for a class of fuzzy cellular neural networks via non-chattering quantized controllers, Neural Networks, 113 (2019), 79–90. https://doi.org/10.1016/j.neunet.2018.11.010 doi: 10.1016/j.neunet.2018.11.010
|
| [56] |
D. Liu, Y. Du, New results of stability analysis for a class of neutral-type neural network with mixed time delays, Int. J. Mach. Learn. Cybern., 6 (2015), 555–566. https://doi.org/10.1007/s13042-014-0302-9 doi: 10.1007/s13042-014-0302-9
|
| [57] |
Y. Cao, R. Samidurai, R. Sriraman, Robust passivity analysis for uncertain neural networks with leakage delay and additive time-varying delays by using general activation function, Math. Comput. Simul., 155 (2019), 57–77. https://doi.org/10.1016/j.matcom.2017.10.016 doi: 10.1016/j.matcom.2017.10.016
|
| [58] |
H. Zhang, J. Cheng, H. Zhang, W. Zhang, J. Cao, Quasi-uniform synchronization of Caputo type fractional neural networks with leakage and discrete delays, Chaos Solitons Fract., 152 (2021), 111432. https://doi.org/10.1016/j.chaos.2021.111432 doi: 10.1016/j.chaos.2021.111432
|
| [59] |
X. Wei, Z. Zhang, M. Liu, Z. Wang, J. Chen, Anti-synchronization for complex-valued neural networks with leakage delay and time-varying delays, Neurocomputing, 412 (2020), 312–319. https://doi.org/10.1016/j.neucom.2020.06.080 doi: 10.1016/j.neucom.2020.06.080
|
| [60] |
L. Wang, Q. Song, Z. Zhao, Y. Liu, F. E. Alsaadi, Synchronization of two nonidentical complex-valued neural networks with leakage delay and time-varying delays, Neurocomputing, 356 (2019), 52–59. https://doi.org/10.1016/j.neucom.2019.04.068 doi: 10.1016/j.neucom.2019.04.068
|
| [61] |
M. S. Ali, N. Gunasekaran, C. K. Ahn, P. Shi, Sampled-data stabilization for fuzzy genetic regulatory networks with leakage delays, IEEE/ACM Trans. Comput. Biol. Bioinf., 15 (2016), 271–285. https://doi.org/10.1109/TCBB.2016.2606477 doi: 10.1109/TCBB.2016.2606477
|
| [62] |
A. Pratap, R. Raja, J. Cao, G. Rajchakit, F. E. Alsaadi, Further synchronization in finite time analysis for time-varying delayed fractional order memristive competitive neural networks with leakage delay, Neurocomputing, 317 (2018), 110–126. https://doi.org/10.1016/j.neucom.2018.08.016 doi: 10.1016/j.neucom.2018.08.016
|
| [63] |
Q. Song, Z. Zhao, Stability criterion of complex-valued neural networks with both leakage delay and time-varying delays on time scales, Neurocomputing, 171 (2016), 179–184. https://doi.org/10.1016/j.neucom.2015.06.032 doi: 10.1016/j.neucom.2015.06.032
|
| [64] |
R. Samidurai, R. Sriraman, S. Zhu, Leakage delay-dependent stability analysis for complex-valued neural networks with discrete and distributed time-varying delays, Neurocomputing, 338 (2016), 262–273. https://doi.org/10.1016/j.neucom.2019.02.027 doi: 10.1016/j.neucom.2019.02.027
|
| [65] |
N. F. Rulkov, Images of synchronized chaos: Experiments with circuits, Chaos, 6 (1996), 262–279. https://doi.org/10.1063/1.166174 doi: 10.1063/1.166174
|
| [66] |
J. Zhou, Y. Zhao, Z. Wu, Cluster synchronization of fractional-order directed networks via intermittent pinning control, Physica A Stat. Mech. Appl., 519 (2019), 22–33. https://doi.org/10.1016/j.physa.2018.12.032 doi: 10.1016/j.physa.2018.12.032
|
| [67] |
S. Lakshmanan, J. H. Park, H. Y. Jung, P. Balasubramaniam, Design of state estimator for neural networks with leakage, discrete and distributed delays, Appl. Math. Comput., 218 (2012), 11297–11310. https://doi.org/10.1016/j.amc.2012.05.022 doi: 10.1016/j.amc.2012.05.022
|
| [68] |
T. Li, W. X. Zheng, C. Lin, Delay-slope-dependent stability results of recurrent neural networks, IEEE Trans. Neural Networks, 22 (2011), 2138–2143. https://doi.org/10.1109/TNN.2011.2169425 doi: 10.1109/TNN.2011.2169425
|
| [69] |
L. Wen, Y. Yu, W. Wang, Generalized Halanay inequalities for dissipativity of Volterra functional differential equations, J. Math. Anal. Appl., 347 (2008), 169–178. https://doi.org/10.1016/j.jmaa.2008.05.007 doi: 10.1016/j.jmaa.2008.05.007
|
| [70] |
X. Li, X. Fu, Effect of leakage time-varying delay on stability of nonlinear differential systems, J. Franklin Inst., 350 (2013), 1335–1344. https://doi.org/10.1016/j.jfranklin.2012.04.007 doi: 10.1016/j.jfranklin.2012.04.007
|
| [71] |
K. Kaneko, Relevance of dynamic clustering to biological networks, Phys. D Nonlinear Phenom., 75 (1994), 55–73. https://doi.org/10.1016/0167-2789(94)90274-7 doi: 10.1016/0167-2789(94)90274-7
|
| [72] |
W. Yu, J. Cao, J. Lü, Global synchronization of linearly hybrid coupled networks with time-varying delay, SIAM J. Appl. Dyn. Syst., 7 (2008), 108–133. https://doi.org/10.1137/070679090 doi: 10.1137/070679090
|
| [73] |
J. Cao, G. Chen, P. Li, Global synchronization in an array of delayed neural networks with hybrid coupling, IEEE Trans. Syst. Man Cybern., 38 (2008), 488–498. https://doi.org/10.1109/TSMCB.2007.914705 doi: 10.1109/TSMCB.2007.914705
|
| [74] |
J. Cao, W. Yu, Y. Qu, A new complex network model and convergence dynamics for reputation computation in virtual organizations, Phys. lett. A, 356 (2006), 414–425 https://doi.org/10.1016/j.physleta.2006.04.005 doi: 10.1016/j.physleta.2006.04.005
|
| [75] |
L. Hu, H. Gao, W. Zheng, Novel stability of cellular neural networks with interval time-varying delay, Neural Networks, 21 (2008), 1458–1463. https://doi.org/10.1016/j.neunet.2008.09.002 doi: 10.1016/j.neunet.2008.09.002
|
| [76] |
S. Mou, H. Gao, W. Qiang, K. Chen, New delay-dependent exponential stability for neural networks with time delay, IEEE Trans. Syst. Man Cybern., 38 (2008), 571–576. https://doi.org/10.1109/TSMCB.2007.913124 doi: 10.1109/TSMCB.2007.913124
|
| [77] |
X. Peng, H. Wu, K. Song, J. Shi, Global synchronization in finite time for fractional-order neural networks with discontinuous activations and time delays, Neural Networks, 94 (2017), 46–54. https://doi.org/10.1016/j.neunet.2017.06.011 doi: 10.1016/j.neunet.2017.06.011
|
| [78] |
Z. Ding, Z. Zeng, L. Wang, Robust finite-time stabilization of fractional-order neural networks with discontinuous and continuous activation functions under uncertainty, IEEE Trans. Neural Networks Learn. Syst., 29 (2017), 1477–1490. https://doi.org/10.1109/TNNLS.2017.2675442 doi: 10.1109/TNNLS.2017.2675442
|
| [79] |
X. Yang, Can neural networks with arbitrary delays be finite-timely synchronized, Neurocomputing, 143 (2014), 275–281. https://doi.org/10.1016/j.neucom.2014.05.064 doi: 10.1016/j.neucom.2014.05.064
|
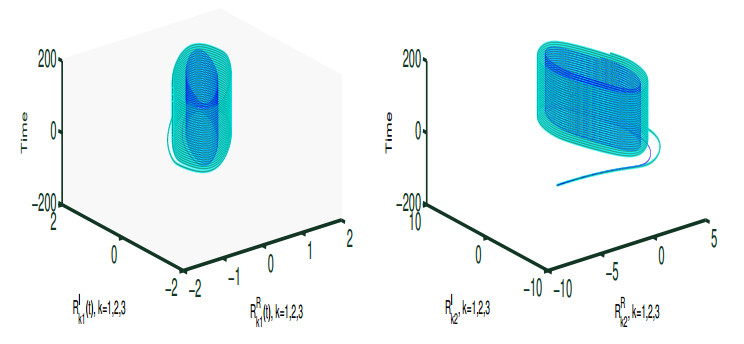
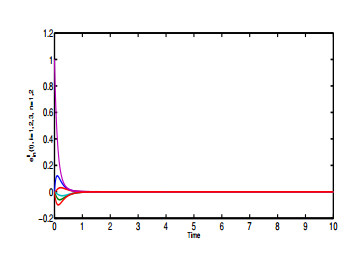
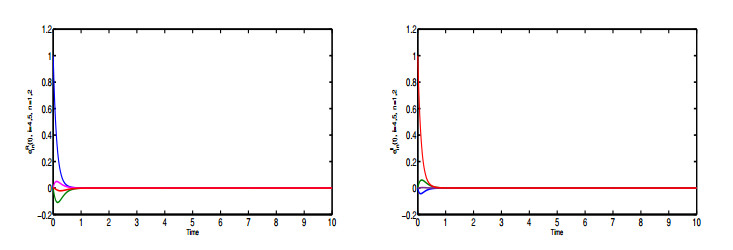
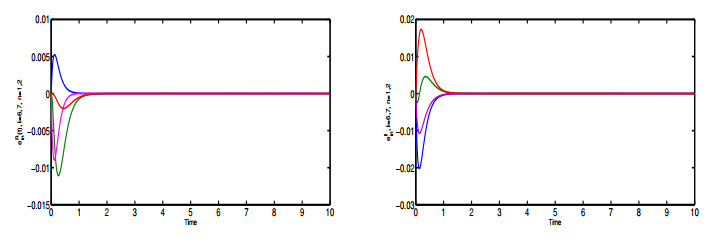
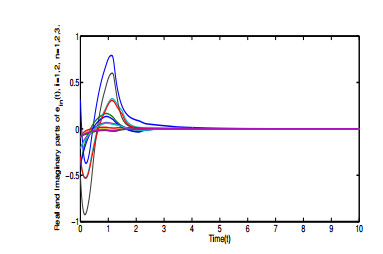
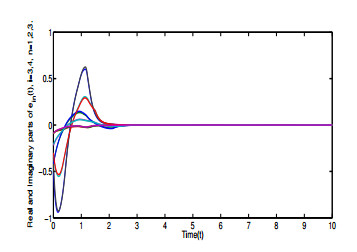
Figures(6)

N. Jayanthi, R. Santhakumari, Grienggrai Rajchakit, Nattakan Boonsatit, Anuwat Jirawattanapanit. Cluster synchronization of coupled complex-valued neural networks with leakage and time-varying delays in finite-time[J]. AIMS Mathematics, 2023, 8(1): 2018-2043. doi: 10.3934/math.2023104







 DownLoad:
DownLoad: