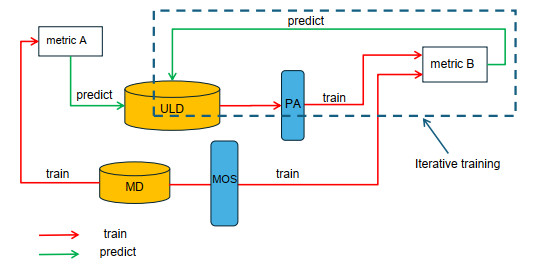
No-reference image quality assessment is crucial for evaluating perceptual quality across diverse image-processing applications. Given the challenge of accruing mean opinion scores for images, utilizing data augmentation and transfer learning is vital for training predictive networks. This paper presents a new iterative transfer learning technique, which helps to transfer knowledge between heterogeneous network architectures, and overcomes the problem of overlearning when training on small datasets. The proposed method used a large amount of unlabeled data during training, improving its ability to handle different image quality conditions. We also presented a two-branch convolutional neural network architecture, which merges multi-scale and multi-level attributes efficiently. This architecture emphasizes both local detail extraction and high-level comprehension, and the result was fast execution time and minimal memory overhead. Empirical results showed that applying iterative transfer learning to train a two-branch convolutional neural network achieved superior real-time performance and at the same time exhibited good performance in spearman's rank order correlation coefficient. Furthermore, the model manifested robustness for the noisy mean opinion score, which is prevalent in available datasets, and during data augmentation processes.
Citation: Sheyda Ghanbaralizadeh Bahnemiri, Mykola Pnomarenko, Karen Eguiazarian. Iterative transfer learning with large unlabeled datasets for no-reference image quality assessment[J]. Applied Computing and Intelligence, 2024, 4(2): 107-124. doi: 10.3934/aci.2024007
No-reference image quality assessment is crucial for evaluating perceptual quality across diverse image-processing applications. Given the challenge of accruing mean opinion scores for images, utilizing data augmentation and transfer learning is vital for training predictive networks. This paper presents a new iterative transfer learning technique, which helps to transfer knowledge between heterogeneous network architectures, and overcomes the problem of overlearning when training on small datasets. The proposed method used a large amount of unlabeled data during training, improving its ability to handle different image quality conditions. We also presented a two-branch convolutional neural network architecture, which merges multi-scale and multi-level attributes efficiently. This architecture emphasizes both local detail extraction and high-level comprehension, and the result was fast execution time and minimal memory overhead. Empirical results showed that applying iterative transfer learning to train a two-branch convolutional neural network achieved superior real-time performance and at the same time exhibited good performance in spearman's rank order correlation coefficient. Furthermore, the model manifested robustness for the noisy mean opinion score, which is prevalent in available datasets, and during data augmentation processes.

| [1] | P. Mohammadi, A. Ebrahimi-Moghadam, S. Shirani, Subjective and objective quality assessment of image: a survey, arXiv: 1406.7799. http://dx.doi.org/10.48550/arXiv.1406.7799 |
| [2] | S. Möller, A. Raake, Quality of experience: advanced concepts, applications and methods, Cham: Springer, 2014. http://dx.doi.org/10.1007/978-3-319-02681-7 |
| [3] |
H. Liu, I. Heynderickx, A perceptually relevant no-reference blockiness metric based on local image characteristics, EURASIP J. Adv. Sig. Pr., 2009 (2009), 263540. http://dx.doi.org/10.1155/2009/263540 doi: 10.1155/2009/263540

|
| [4] |
S. Golestaneh, D. Chandler, No-reference quality assessment of JPEG images via a quality relevance map, IEEE Signal Proc. Lett., 21 (2014), 155–158. http://dx.doi.org/10.1109/LSP.2013.2296038 doi: 10.1109/LSP.2013.2296038
|
| [5] |
Y. Zhan, R. Zhang, No-reference JPEG image quality assessment based on blockiness and luminance change, IEEE Signal Proc. Lett., 24 (2017), 760–764. http://dx.doi.org/10.1109/LSP.2017.2688371 doi: 10.1109/LSP.2017.2688371
|
| [6] |
H. Liu, N. Klomp, I. Heynderickx, A no-reference metric for perceived ringing artifacts in images, IEEE T. Circ. Syst. Vid., 20 (2010), 529–539. http://dx.doi.org/10.1109/TCSVT.2009.2035848 doi: 10.1109/TCSVT.2009.2035848
|
| [7] |
L. Liang, S. Wang, J. Chen, S. Ma, D. Zhao, W. Gao, No-reference perceptual image quality metric using gradient profiles for JPEG2000, Signal Process.-Image, 25 (2010), 502–516. http://dx.doi.org/10.1016/j.image.2010.01.007 doi: 10.1016/j.image.2010.01.007
|
| [8] |
N. Ponomarenko, V. Lukin, O. Eremeev, K. Egiazarian, J. Astola, Sharpness metric for no-reference image visual quality assessment, Proceedings of Image Processing: Algorithms and Systems X; and Parallel Processing for Imaging Applications II, 2012, 829519. http://dx.doi.org/10.1117/12.906393 doi: 10.1117/12.906393
|
| [9] |
N, Narvekar, L. Karam, A no-reference perceptual image sharpness metric based on a cumulative probability of blur detection, Proceedings of International Workshop on Quality of Multimedia Experience, 2009, 87–91. http://dx.doi.org/10.1109/QOMEX.2009.5246972 doi: 10.1109/QOMEX.2009.5246972
|
| [10] |
F. Crete, T. Dolmiere, P. Ladret, M. Nicolas, The blur effect: perception and estimation with a new no-reference perceptual blur metric, Proceedings of Human vision and electronic imaging XII, 2007, 649201. http://dx.doi.org/10.1117/12.702790 doi: 10.1117/12.702790
|
| [11] |
C. Ma, C. Yang, X. Yang, M. Yang, Learning a no-reference quality metric for single-image super-resolution, Comput. Vis. Image Und., 158 (2017), 1–16. http://dx.doi.org/10.1016/j.cviu.2016.12.009 doi: 10.1016/j.cviu.2016.12.009
|
| [12] |
K. Zhang, D. Zhu, J. Li, X. Gao, F. Gao, J. Lu, Learning stacking regression for no-reference super-resolution image quality assessment, Signal Process., 178 (2021), 107771. http://dx.doi.org/10.1016/j.sigpro.2020.107771 doi: 10.1016/j.sigpro.2020.107771
|
| [13] |
A. Shulev, A. Gotchev, A. Foi, I. Roussev, Threshold selection in transform-domain denoising of speckle pattern fringes, Proceedings of Holography 2005: International Conference on Holography, Optical Recording, and Processing of Information, 2006, 625220. http://dx.doi.org/10.1117/12.677284 doi: 10.1117/12.677284
|
| [14] |
V. Lukin, D. Fevralev, N. Ponomarenko, S. Abramov, O. Pogrebnyak, K. Egiazarian, et al., Discrete cosine transform–-based local adaptive filtering of images corrupted by nonstationary noise, J. Electron. Imag., 19 (2010), 023007. http://dx.doi.org/10.1117/1.3421973 doi: 10.1117/1.3421973
|
| [15] |
X. Liu, M. Tanaka, M. Okutomi, Noise level estimation using weak textured patches of a single noisy image, Proceedings of 19th IEEE International Conference on Image Processing, 2012,665–668. http://dx.doi.org/10.1109/ICIP.2012.6466947 doi: 10.1109/ICIP.2012.6466947
|
| [16] | Z. Yue, H. Yong, Q. Zhao, D. Meng, L. Zhang, Variational denoising network: toward blind noise modeling and removal, Proceedings of 33rd Conference on Neural Information Processing Systems, 2019, 1–12. |
| [17] |
S. Bahnemiri, M. Ponomarenko, K. Egiazarian, Learning-based noise component map estimation for image denoising, IEEE Signal Proc. Lett., 29 (2022), 1407–1411. http://dx.doi.org/10.1109/LSP.2022.3169706 doi: 10.1109/LSP.2022.3169706
|
| [18] |
A. Moorthy, A. Bovik, Blind image quality assessment: from natural scene statistics to perceptual quality, IEEE T. Image Process., 20 (2011), 3350–3364. http://dx.doi.org/10.1109/TIP.2011.2147325 doi: 10.1109/TIP.2011.2147325
|
| [19] |
A. Mittal, A. Moorthy, A. Bovik, No-reference image quality assessment in the spatial domain, IEEE T. Image Process., 21 (2012), 4695–4708. http://dx.doi.org/10.1109/TIP.2012.2214050 doi: 10.1109/TIP.2012.2214050
|
| [20] |
J. Yan, X. Bai, Y. Xiao, Y. Zhang, X. Lv, No-reference remote sensing image quality assessment based on gradient-weighted natural scene statistics in spatial domain, J. Electron. Imaging, 28 (2019), 013033. http://dx.doi.org/10.1117/1.JEI.28.1.013033 doi: 10.1117/1.JEI.28.1.013033
|
| [21] |
A. Mittal, R. Soundararajan, A. Bovik, Making a "completely blind" image quality analyzer, IEEE Signal Proc. Lett., 20 (2013), 209–212. http://dx.doi.org/10.1109/LSP.2012.2227726 doi: 10.1109/LSP.2012.2227726
|
| [22] |
M. Saad, A. Bovik, C. Charrier, Blind image quality assessment: a natural scene statistics approach in the DCT domain, IEEE T. Image Process., 21 (2012), 3339–3352. http://dx.doi.org/10.1109/TIP.2012.2191563 doi: 10.1109/TIP.2012.2191563
|
| [23] |
A. Moorthy, A. Bovik, A two-step framework for constructing blind image quality indices, IEEE Signal Proc. Lett., 17 (2010), 513–516. http://dx.doi.org/10.1109/LSP.2010.2043888 doi: 10.1109/LSP.2010.2043888
|
| [24] |
Y. Zhang, A. Moorthy, D. Chandler, A. Bovik, C-DIIVINE: no-reference image quality assessment based on local magnitude and phase statistics of natural scenes, Signal Process.-Image, 29 (2014), 725–747. http://dx.doi.org/10.1016/j.image.2014.05.004 doi: 10.1016/j.image.2014.05.004
|
| [25] | R. Campos, E. Salles, Robust statistics and no-reference image quality assessment in curvelet domain, arXiv: 1902.03842. http://dx.doi.org/10.48550/arXiv.1902.03842 |
| [26] |
Y. Zhang, D. Chandler, No-reference image quality assessment based on log-derivative statistics of natural scenes, J. Electron. Imaging, 22 (2013), 043025. http://dx.doi.org/10.1117/1.JEI.22.4.043025 doi: 10.1117/1.JEI.22.4.043025
|
| [27] |
X. Chen, Q. Zhang, M. Lin, G. Yang, C. He, No-reference color image quality assessment: from entropy to perceptual quality, J. Image Video Proc., 2019 (2019), 77. http://dx.doi.org/10.1186/s13640-019-0479-7 doi: 10.1186/s13640-019-0479-7
|
| [28] |
F. Ou, Y. Wang, G. Zhu, A novel blind image quality assessment method based on refined natural scene statistics, Proceedings of IEEE International Conference on Image Processing (ICIP), 2019, 1004–1008. http://dx.doi.org/10.1109/ICIP.2019.8803047 doi: 10.1109/ICIP.2019.8803047
|
| [29] |
L. Liu, H. Dong, H. Huang, A. Bovik, No-reference image quality assessment in curvelet domain, Signal Process.-Image, 29 (2014), 494–505. http://dx.doi.org/10.1016/j.image.2014.02.004 doi: 10.1016/j.image.2014.02.004
|
| [30] |
A. Smola, B. Schölkopf, A tutorial on support vector regression, Stat. Comput., 14 (2004), 199–222. http://dx.doi.org/10.1023/B:STCO.0000035301.49549.88 doi: 10.1023/B:STCO.0000035301.49549.88
|
| [31] |
L. Kang, P. Ye, Y. Li, D. Doermann, Convolutional neural networks for no-reference image quality assessment, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014, 1733–1740. http://dx.doi.org/10.1109/CVPR.2014.224 doi: 10.1109/CVPR.2014.224
|
| [32] |
Y. Li, L. Po, L. Feng, F. Yuan, No-reference image quality assessment with deep convolutional neural networks, Proceedings of IEEE International Conference on Digital Signal Processing (DSP), 2016,685–689. http://dx.doi.org/10.1109/ICDSP.2016.7868646 doi: 10.1109/ICDSP.2016.7868646
|
| [33] |
T. Lu, A. Dooms, Towards content independent no-reference image quality assessment using deep learning, Proceedings of IEEE 4th International Conference on Image, Vision and Computing (ICIVC), 2019,276–280. http://dx.doi.org/10.1109/ICIVC47709.2019.8981378 doi: 10.1109/ICIVC47709.2019.8981378
|
| [34] |
Z. Ying, H. Niu, P. Gupta, D. Mahajan, D. Ghadiyaram, A. Bovik, From patches to pictures (PaQ-2-PiQ): mapping the perceptual space of picture quality, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, 3575–3585. http://dx.doi.org/10.1109/CVPR42600.2020.00363 doi: 10.1109/CVPR42600.2020.00363
|
| [35] |
V. Hosu, H. Lin, T. Sziranyi, D. Saupe, KonIQ-10k: an ecologically valid database for deep learning of blind image quality assessment, IEEE T. Image Process., 29 (2020), 4041–4056. http://dx.doi.org/10.1109/TIP.2020.2967829 doi: 10.1109/TIP.2020.2967829
|
| [36] |
N. Ponomarenko, O. Eremeev, V. Lukin, K. Egiazarian, Statistical evaluation of no-reference image visual quality metrics, Proceedings of 2nd European Workshop on Visual Information Processing (EUVIP), 2010, 50–54. http://dx.doi.org/10.1109/EUVIP.2010.5699121 doi: 10.1109/EUVIP.2010.5699121
|
| [37] |
M. Ponomarenko, S. Bahnemiri, K. Egiazarian, O. Ieremeiev, V. Lukin, V. Peltoketo, et al., Color image database HTID for verification of no-reference metrics: peculiarities and preliminary results, Proceedings of 9th European Workshop on Visual Information Processing (EUVIP), 2021, 1–6. http://dx.doi.org/10.1109/EUVIP50544.2021.9484005 doi: 10.1109/EUVIP50544.2021.9484005
|
| [38] |
Y. Fang, H. Zhu, Y. Zeng, K. Ma, Z. Wang, Perceptual quality assessment of smartphone photography, Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, 3677–3686. http://dx.doi.org/10.1109/CVPR42600.2020.00373 doi: 10.1109/CVPR42600.2020.00373
|
| [39] |
D. Ghadiyaram, A. Bovik, Massive online crowdsourced study of subjective and objective picture quality, IEEE T. Image Process., 25 (2016), 372–387. http://dx.doi.org/10.1109/TIP.2015.2500021 doi: 10.1109/TIP.2015.2500021
|
| [40] |
H. Otroshi-Shahreza, A. Amini, H. Behroozi, No-reference image quality assessment using transfer learning, Proceedings of 9th International Symposium on Telecommunications (IST), 2018,637–640. http://dx.doi.org/10.1109/ISTEL.2018.8661024 doi: 10.1109/ISTEL.2018.8661024
|
| [41] |
Y. Feng, Y. Cai, No-reference image quality assessment through transfer learning, Proceedings of IEEE 2nd International Conference on Signal and Image Processing (ICSIP), 2017, 90–94. http://dx.doi.org/10.1109/SIPROCESS.2017.8124512 doi: 10.1109/SIPROCESS.2017.8124512
|
| [42] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, arXiv: 1409.1556. http://dx.doi.org/10.48550/arXiv.1409.1556 |
| [43] |
C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, 2818–2826. http://dx.doi.org/10.1109/CVPR.2016.308 doi: 10.1109/CVPR.2016.308
|
| [44] | A. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: efficient convolutional neural networks for mobile vision applications, arXiv: 1704.04861. http://dx.doi.org/10.48550/arXiv.1704.04861 |
| [45] |
H. Talebi, P. Milanfar, NIMA: neural image assessment, IEEE T. Image Process., 27 (2018), 3998–4011. http://dx.doi.org/10.1109/TIP.2018.2831899 doi: 10.1109/TIP.2018.2831899
|
| [46] |
F. Chollet, Xception: deep learning with depthwise separable convolutions, Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, 1251–1258. http://dx.doi.org/10.1109/CVPR.2017.195 doi: 10.1109/CVPR.2017.195
|
| [47] |
S. Bianco, L. Celona, P. Napoletano, R. Schettini, On the use of deep learning for blind image quality assessment, SIViP, 12 (2018), 355–362. http://dx.doi.org/10.1007/s11760-017-1166-8 doi: 10.1007/s11760-017-1166-8
|
| [48] |
X. Liu, J. Van De Weijer, A. Bagdanov, Rankiqa: learning from rankings for no-reference image quality assessment, Proceedings of IEEE International Conference on Computer Vision (ICCV), 2017, 1040–1049. http://dx.doi.org/10.1109/ICCV.2017.118 doi: 10.1109/ICCV.2017.118
|
| [49] | O. Ronneberger, P. Fischer, T. Brox, U-net: convolutional networks for biomedical image segmentation, In: Medical image computing and computer-assisted intervention, Cham: Springer, 2015,234–241. http://dx.doi.org/10.1007/978-3-319-24574-4_28 |
| [50] |
J. Gu, G. Meng, S. Xiang, C. Pan, Blind image quality assessment via learnable attention-based pooling, Pattern Recogn., 91 (2019), 332–344. http://dx.doi.org/10.1016/j.patcog.2019.02.021 doi: 10.1016/j.patcog.2019.02.021
|
| [51] |
S. Yang, Q. Jiang, W. Lin, Y. Wang, SGDNet: an end-to-end saliency-guided deep neural network for no-reference image quality assessment, Proceedings of the 27th ACM International Conference on Multimedia, 2019, 1383–1391. http://dx.doi.org/10.1145/3343031.3350990 doi: 10.1145/3343031.3350990
|
| [52] |
P. Grüning, E. Barth, Fp-nets for blind image quality assessment, Journal of Perceptual Imaging, 4 (2021), jpi0143. http://dx.doi.org/10.2352/J.Percept.Imaging.2021.4.1.010402 doi: 10.2352/J.Percept.Imaging.2021.4.1.010402
|
| [53] | W. Lu, W. Sun, X. Min, Z. Zhang, T. Wang, W. Zhu, et al., Blind surveillance image quality assessment via deep neural network combined with the visual saliency, In: Artificial intelligence, Cham: Springer, 2022,136–146. http://dx.doi.org/10.1007/978-3-031-20500-2_11 |
| [54] |
S. Su, Q. Yan, Y. Zhu, C. Zhang, X. Ge, J. Sun, Blindly assess image quality in the wild guided by a self-adaptive hyper network, Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, 3667–3676. http://dx.doi.org/10.1109/CVPR42600.2020.00372 doi: 10.1109/CVPR42600.2020.00372
|
| [55] |
S. Golestaneh, S. Dadsetan, K. Kitani, No-reference image quality assessment via transformers, relative ranking, and self-consistency, Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, 1220–1230. http://dx.doi.org/10.1109/WACV51458.2022.00404 doi: 10.1109/WACV51458.2022.00404
|
| [56] |
M. Ponomarenko, S. Bahnemiri, K. Egiazarian, Transfer learning for no-reference image quality metrics using large temporary image sets, Electronic Imaging, 34 (2022), 219-1–219-5. http://dx.doi.org/10.2352/EI.2022.34.14.COIMG-219 doi: 10.2352/EI.2022.34.14.COIMG-219
|
| [57] |
A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, et al., The open images dataset v4: unified image classification, object detection, and visual relationship detection at scale, Int. J. Comput. Vis., 128 (2020), 1956–1981. http://dx.doi.org/10.1007/s11263-020-01316-z doi: 10.1007/s11263-020-01316-z
|
| [58] |
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016,770–778. http://dx.doi.org/10.1109/CVPR.2016.90 doi: 10.1109/CVPR.2016.90
|
| [59] |
A. Kaipio, M. Ponomarenko, K. Egiazarian, Merging of MOS of large image databases for no-reference image visual quality assessment, Proceedings of IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP), 2020, 1–6. http://dx.doi.org/10.1109/MMSP48831.2020.9287141 doi: 10.1109/MMSP48831.2020.9287141
|
| [60] |
W. Zhang, K. Ma, J. Yan, D. Deng, Z. Wang, Blind image quality assessment using a deep bilinear convolutional neural network, IEEE T. Circ. Syst. Vid., 30 (2020), 36–47. http://dx.doi.org/10.1109/TCSVT.2018.2886771 doi: 10.1109/TCSVT.2018.2886771
|
| [61] |
P. Madhusudana, N. Birkbeck, Y. Wang, B. Adsumilli, A. Bovik, Image quality assessment using contrastive learning, IEEE T. Image Process., 31 (2022), 4149–4161. http://dx.doi.org/10.1109/TIP.2022.3181496 doi: 10.1109/TIP.2022.3181496
|
| [62] |
N. Ahmed, S. Asif, BIQ2021: a large-scale blind image quality assessment database, J. Electron. Imaging, 31 (2022), 053010. http://dx.doi.org/10.1117/1.JEI.31.5.053010 doi: 10.1117/1.JEI.31.5.053010
|






Figures(7) / Tables(3)
Sheyda Ghanbaralizadeh Bahnemiri, Mykola Pnomarenko, Karen Eguiazarian. Iterative transfer learning with large unlabeled datasets for no-reference image quality assessment[J]. Applied Computing and Intelligence, 2024, 4(2): 107-124. doi: 10.3934/aci.2024007







 DownLoad:
DownLoad: