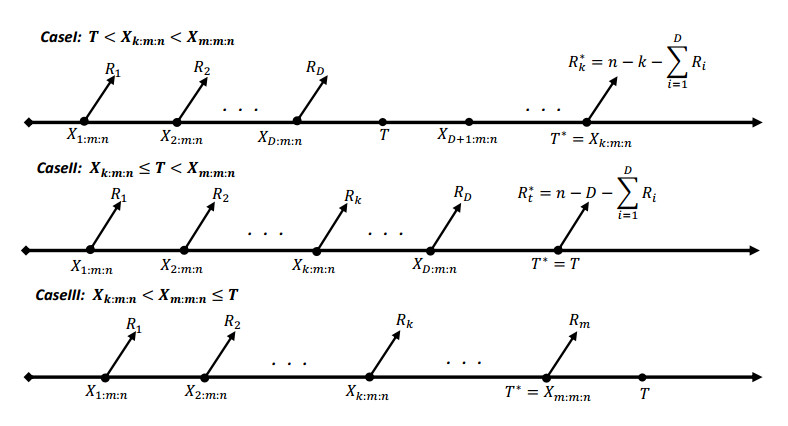
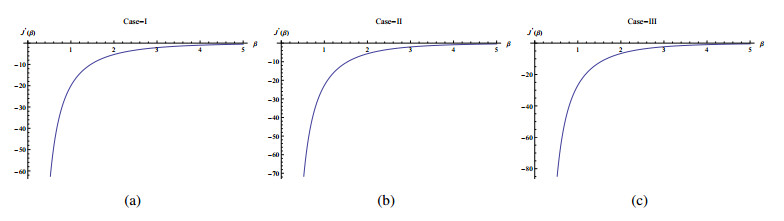
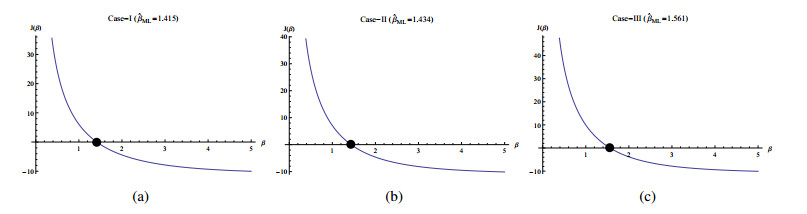
In this paper, we use the generalized progressive hybrid censoring sample from the Burr Type-Ⅻ distribution to estimate the unknown parameters, reliability and hazard functions. We apply the maximum likelihood (ML) and the Bayesian estimation under different prior distributions and different loss functions; namely; are the squared error, Linex and general entropy. Also, we construct the classical and credible intervals of the unknown parameters as well as for the survival and hazard functions. In addition, we investigate the performance of the point estimation by using the mean square error (MSE) and expected bias (EB) and performance of the interval estimation using the average length and coverage probability. Further, we develop the Bayesian one- and two- samples Bayesan prediction for the non-observed failures in the progressive censoring. In order to show the performance and usefulness of the inferential procedures, we carry out some simulation experiments using MCMC Algorithm for the Bayesian approach based on different prior distributions. Finally, we apply the theatrical finding to some real life data set.
Citation: Magdy Nagy, Khalaf S. Sultan, Mahmoud H. Abu-Moussa. Analysis of the generalized progressive hybrid censoring from Burr Type-Ⅻ lifetime model[J]. AIMS Mathematics, 2021, 6(9): 9675-9704. doi: 10.3934/math.2021564
In this paper, we use the generalized progressive hybrid censoring sample from the Burr Type-Ⅻ distribution to estimate the unknown parameters, reliability and hazard functions. We apply the maximum likelihood (ML) and the Bayesian estimation under different prior distributions and different loss functions; namely; are the squared error, Linex and general entropy. Also, we construct the classical and credible intervals of the unknown parameters as well as for the survival and hazard functions. In addition, we investigate the performance of the point estimation by using the mean square error (MSE) and expected bias (EB) and performance of the interval estimation using the average length and coverage probability. Further, we develop the Bayesian one- and two- samples Bayesan prediction for the non-observed failures in the progressive censoring. In order to show the performance and usefulness of the inferential procedures, we carry out some simulation experiments using MCMC Algorithm for the Bayesian approach based on different prior distributions. Finally, we apply the theatrical finding to some real life data set.

| [1] | N. Balakrishnan, R. Aggarwala, Progressive censoring: theory, methods, and applications, Springer Science & Business Media, 2000. |
| [2] |
N. Balakrishnan, Progressive censoring methodology: an appraisal, Test, 16 (2007), 211. doi: 10.1007/s11749-007-0061-y

|
| [3] |
E. Cramer, G. Iliopoulos, Adaptive progressive Type-Ⅱ censoring, Test, 19 (2010), 342–358. doi: 10.1007/s11749-009-0167-5
|
| [4] |
M. Z. Raqab, A. Asgharzadeh, R. Valiollahi, Prediction for Pareto distribution based on progressively Type-Ⅱ censored samples, Comput. Stat. Data Anal., 54 (2010), 1732–1743. doi: 10.1016/j.csda.2010.02.005
|
| [5] |
M. M. El-Din, A. R. Shafay, One-and two-sample Bayesian prediction intervals based on progressively Type-Ⅱ censored data, Stat. Pap. (Berl), 54 (2013), 287–307. doi: 10.1007/s00362-011-0426-x
|
| [6] | N. Balakrishnan, A. C. Cohen, Order statistics & inference: estimation methods, Academic Press, San Diego, 1991. |
| [7] | D. Kundu, A. Joarder, Analysis of Type-Ⅱ progressively hybrid censored data, Comput. Stat. Data Anal., 50, (2006), 2509–2528. |
| [8] | A. Childs, B. Chandrasekar, N. Balakrishnan, Exact likelihood inference for an exponential parameter under progressive hybrid censoring schemes, In: Statistical Models and Methods for Biomedical and Technical Systems, Birkhäuser Boston, 2008,319–330. |
| [9] |
C. T. Lin, C. C. Chou, Y. L. Huang, Inference for the Weibull distribution with progressive hybrid censoring, Comput. Stat. Data Anal., 56 (2012), 451–467. doi: 10.1016/j.csda.2011.09.002
|
| [10] |
C. T. Lin, Y. L. Huang, On progressive hybrid censored exponential distribution, J. Stat. Comput. Simul., 82 (2012), 689–709. doi: 10.1080/00949655.2010.550581
|
| [11] |
F. Hemmati, E. Khorram, Statistical analysis of the log-normal distribution under Type-Ⅱ progressive hybrid censoring schemes, Commun. Stat. Simul. Comput., 42 (2013), 52–75. doi: 10.1080/03610918.2011.633195
|
| [12] |
M. M. El-Din, Y. Abdel-Aty, M. H. Abu-Moussa, Statistical inference for the Gompertz distribution based on Type-Ⅱ progressively hybrid censored data, Commun. Stat. Simul. Comput., 46 (2017), 6242–6260. doi: 10.1080/03610918.2016.1202270
|
| [13] |
Y. Cho, H. Sun, K. Lee, Exact likelihood inference for an exponential parameter under generalized progressive hybrid censoring scheme, Stat. Methodol., 23 (2015), 18–34. doi: 10.1016/j.stamet.2014.09.002
|
| [14] |
M. M. El-Din, A. R. Shafay, M. Nagy, Statistical inference under adaptive progressive censoring scheme, Comput. Stat., 33 (2018), 31–74. doi: 10.1007/s00180-017-0745-z
|
| [15] |
M. M. El-Din, M. Nagy, M. H. Abu-Moussa, Estimation and prediction for gompertz distribution under the generalized progressive hybrid censored data, Ann. Data Sci., 6 (2019), 673–705. doi: 10.1007/s40745-019-00199-3
|
| [16] | M. H. Abu-Moussa, M. M. El-Din, M. A. Mosilhy, Statistical inference for Gompertz distribution using the adaptive-general progressive Type-Ⅱ censored samples, Am. J. Math. Manag. Sci., (2020), 1–23. |
| [17] |
K. Lee, H. Sun, Y. Cho, Exact likelihood inference of the exponential parameter under generalized Type Ⅱ progressive hybrid censoring, J. Korean Stat. Soc., 45 (2016), 123–136. doi: 10.1016/j.jkss.2015.08.003
|
| [18] | P. Parviz, H. Panahi, Classical and Bayesian inference for the Burr Type Ⅻ distribution under generalized progressive Type Ⅰ hybrid censored sample, J. Stat. Theory App., 19 (2020), 547–557. |
| [19] |
R. Calabria, G. Pulcini, Point estimation under asymmetric loss functions for left-truncated exponential samples, Commun. Stat. Theory Methods, 25 (1996), 585–600. doi: 10.1080/03610929608831715
|
| [20] |
D. R. Wingo, Maximum likelihood estimation of Burr Ⅻ distribution parameters under Type-Ⅱ censoring, Microelectron. Reliab., 33 (1993), 1251–1257. doi: 10.1016/0026-2714(93)90126-J
|
| [21] | W. H. Greene, Econometric analysis 4th edition, International edition, New Jersey: Prentice Hall, 2000,201–215. |
| [22] | A. Agresti, Logistic regression, Categorical data analysis, Wiley & Sons, Inc, 2002. |
| [23] |
E. K. Al-Hussaini, Z. F. Jaheen, Bayesian estimation of the parameters, reliability and failure rate functions of the Burr Type Ⅻ failure model, J. Stat. Comput. Simul., 41 (1992), 31–40. doi: 10.1080/00949659208811389
|
| [24] |
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, E. Teller, Equation of state calculations by fast computing machines, J. Chem. Phys., 21 (1953), 1087–1092. doi: 10.1063/1.1699114
|
| [25] |
I. Basak, P. Basak, N. Balakrishnan, On some predictors of times to failure of censored items in progressively censored samples, Comput. Stat. Data Anal., 50 (2006), 1313–1337. doi: 10.1016/j.csda.2005.01.011
|
| [26] |
N. Balakrishnan, A. Childs, B. Chandrasekar, An efficient computational method for moments of order statistics under progressive censoring, Stat. Probab. Lett., 60 (2002), 359–365. doi: 10.1016/S0167-7152(02)00267-5
|
| [27] |
H. K. T. Ng, D. Kundu, P. S. Chan, Statistical analysis of exponential lifetimes under an adaptive TypeⅡ progressive censoring scheme, Nav. Res. Logist., 56 (2009), 687–698. doi: 10.1002/nav.20371
|
 math-06-09-564-Supplementary.nb math-06-09-564-Supplementary.nb |
 |
Figures(3) / Tables(11)

Magdy Nagy, Khalaf S. Sultan, Mahmoud H. Abu-Moussa. Analysis of the generalized progressive hybrid censoring from Burr Type-Ⅻ lifetime model[J]. AIMS Mathematics, 2021, 6(9): 9675-9704. doi: 10.3934/math.2021564







 DownLoad:
DownLoad: