The aim of this work is to introduce a two-dimensional macroscopic traffic model for multiple populations of vehicles. Starting from the paper [
Citation: Caterina Balzotti, Simone Göttlich. A two-dimensional multi-class traffic flow model[J]. Networks and Heterogeneous Media, 2021, 16(1): 69-90. doi: 10.3934/nhm.2020034
The aim of this work is to introduce a two-dimensional macroscopic traffic model for multiple populations of vehicles. Starting from the paper [

| [1] |
Vehicular traffic, crowds, and swarms: From kinetic theory and multiscale methods to applications and research perspectives. Math. Models Methods Appl. Sci. (2019) 29: 1901-2005. 
|
| [2] |
Derivation of continuum traffic flow models from microscopic follow-the-leader models. SIAM J. Appl. Math. (2002) 63: 259-278.
|
| [3] |
Resurrection of "second order" models of traffic flow. SIAM J. Appl. Math. (2000) 60: 916-944.
|
| [4] |
An $n$-populations model for traffic flow. European J. Appl. Math. (2003) 14: 587-612.
|
| [5] | S. Bertoluzza, S. Falletta, G. Russo and C.-W. Shu, Numerical Solutions of Partial Differential Equations, Advanced Courses in Mathematics, CRM Barcelona, Birkhäuser Verlag, Basel, 2009. |
| [6] | B. N. Chetverushkin, N. G. Churbanova, Y. N. Karamzin and M. A. Trapeznikova, A two-dimensional macroscopic model of traffic flows based on KCFD-schemes, in ECCOMAS CFD 2006: Proceedings of the European Conference on Computational Fluid Dynamics, Egmond aan Zee, The Netherlands, September 5-8, 2006, Citeseer, 2006. |
| [7] |
A $2\times 2$ hyperbolic traffic flow model. Math. Comput. Modelling (2002) 35: 683-688.
|
| [8] |
A traffic model aware of real time data. Math. Models Methods Appl. Sci. (2016) 26: 445-467.
|
| [9] |
A fluid dynamic approach for traffic forecast from mobile sensors data. Commun. Appl. Ind. Math. (2010) 1: 54-71.
|
| [10] |
C. M. Dafermos, Hyperbolic Conservation Laws in Continuum Physics, 4$^{th}$ edition, Grundlehren der Mathematischen Wissenschaften, 325, Springer-Verlag, Berlin, 2016. doi: 10.1007/978-3-662-49451-6
|
| [11] |
A continuum theory of traffic dynamics for freeways with special lanes. Transport. Res. B-Meth. (1997) 31: 83-102.
|
| [12] |
In traffic flow, cellular automata = kinematic waves. Transp. Res. B-Meth. (2006) 40: 396-403.
|
| [13] |
Comparative model accuracy of a data-fitted generalized Aw-Rascle-Zhang model. Netw. Heterog. Media (2014) 9: 239-268.
|
| [14] |
Data-fitted first-order traffic models and their second-order generalizations: Comparison by trajectory and sensor data. Transport. Res. Rec. (2013) 2391: 32-43.
|
| [15] | M. Garavello, K. Han and B. Piccoli, Models for Vehicular Traffic on Networks, American Institute of Mathematical Sciences, 2016. |
| [16] |
Nonlinear follow-the-leader models of traffic flow. Oper. Res. (1961) 9: 545-567.
|
| [17] |
The Aw-Rascle vehicular traffic flow model with phase transitions. Math. Comput. Modelling (2006) 44: 287-303.
|
| [18] | A difference method for numerical calculation of discontinuous solutions of the equations of hydrodynamics. Matematicheskii Sbornik (1959) 89: 271-306. |
| [19] |
D. Helbing, From microscopic to macroscopic traffic models, in A Perspective Look at Nonlinear Media, Lecture Notes in Physics, 503, Springer, Berlin, 1998, 122–139. doi: 10.1007/BFb0104959
|
| [20] |
Multi-class traffic models on road networks. Commun. Math. Sci. (2006) 4: 591-608.
|
| [21] |
A two-dimensional data-driven model for traffic flow on highways. Netw. Heterog. Media (2018) 13: 217-240.
|
| [22] |
Macroscopic modeling of multilane motorways using a two-dimensional second-order model of traffic flow. SIAM J. Appl. Math. (2018) 78: 2252-2278.
|
| [23] |
Models for dense multilane vehicular traffic. SIAM J. Math. Anal. (2019) 51: 3694-3713.
|
| [24] |
Vlasov-Fokker-Planck models for multilane traffic flow. Commun. Math. Sci. (2003) 1: 1-12.
|
| [25] | E. Kallo, A. Fazekas, S. Lamberty and M. Oeser, Microscopic traffic data obtained from videos recorded on a German motorway, https://data.mendeley.com/datasets/tzckcsrpn6/1, 2019. |
| [26] |
A hierarchy of models for multilane vehicular traffic. Ⅰ. Modeling. SIAM J. Appl. Math. (1999) 59: 983-1001.
|
| [27] |
A hierarchy of models for multilane vehicular traffic. Ⅱ. Numerical investigations. SIAM J. Appl. Math. (1999) 59: 1002-1011.
|
| [28] |
Kinetic derivation of macroscopic anticipation models for vehicular traffic. SIAM J. Appl. Math. (2000) 60: 1749-1766.
|
| [29] |
A mechanism to describe the formation and propagation of stop-and-go waves in congested freeway traffic. Philos. T. R. Soc. A (2010) 368: 4519-4541.
|
| [30] |
Two-phase bounded-acceleration traffic flow model: Analytical solutions and applications. Transp. Res. Rec. (2003) 1852: 220-230.
|
| [31] |
(2002) Finite Volume Methods for Hyperbolic Problems. Cambridge: Cambridge Texts in Applied Mathematics, Cambridge University Press.
|
| [32] |
On kinematic waves. Ⅱ. A theory of traffic flow on long crowded roads. Proc. Roy. Soc. A (1955) 229: 317-345.
|
| [33] |
P. Nelson, A kinetic model of vehicular traffic and its associated bimodal equilibrium solutions, in Special Issue Devoted to the Proceedings of the 13th International Conference on Transport Theory (Riccione, 1993), 24, 1995,383–409. doi: 10.1080/00411459508205136
|
| [34] |
Nonlinear effects in the dynamics of car following. Oper. Res. (1961) 9: 209-229.
|
| [35] |
On estimation of a probability density function and mode. Ann. Math. Statist. (1962) 33: 1065-1076.
|
| [36] |
A kinetic model for traffic flow with continuum implications. Transport. Plan. Techn. (1979) 5: 131-138.
|
| [37] |
Second-order models and traffic data from mobile sensors. Transp. Res. C-Emer. (2015) 52: 32-56.
|
| [38] |
An operational analysis of traffic dynamics. J. Appl. Phys. (1953) 24: 274-281.
|
| [39] |
A Boltzmann-like approach for traffic flow. Oper. Res. (1960) 8: 789-797.
|
| [40] |
Kinetic models for traffic flow resulting in a reduced space of microscopic velocities. Kinet. Relat. Models (2017) 10: 823-854.
|
| [41] |
Shock waves on the highway. Oper. Res. (1956) 4: 42-51.
|
| [42] |
Remarks on some nonparametric estimates of a density function. Ann. Math. Statist. (1956) 27: 832-837.
|
| [43] | Empirical features of congested traffic states and their implications for traffic modeling. Transport. Sci. (2007) 41: 135-166. |
| [44] | US Department of Transportation and Federal Highway Administration, Next Generation Simulation (NGSIM), http://ops.fhwa.dot.gov/trafficanalysistools/ngsim.htm. |
| [45] |
A multi-class traffic flow model–an extension of LWR model with heterogeneous drivers. Transport. Res. A-Pol (2002) 36: 827-841.
|
| [46] |
A non-equilibrium traffic model devoid of gas-like behavior. Transp. Res. B (2002) 36: 275-290.
|
| [47] |
Two-dimensional Riemann problem for a single conservation law. Trans. Amer. Math. Soc. (1989) 312: 589-619.
|
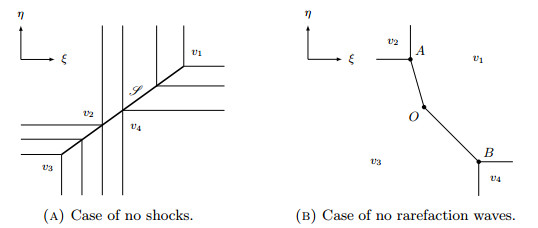
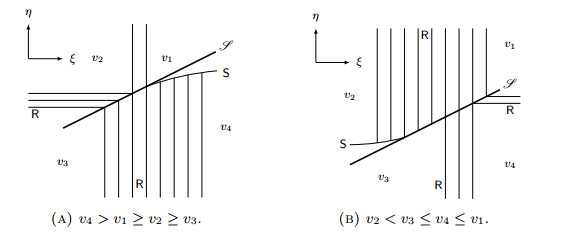
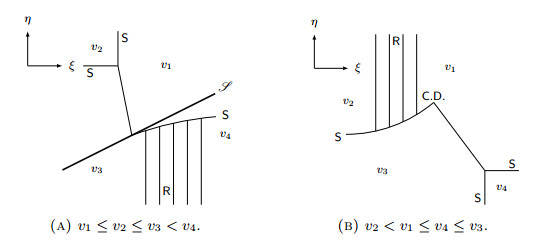
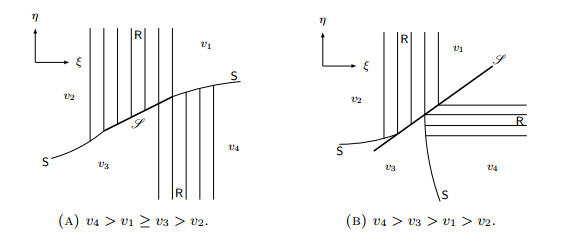
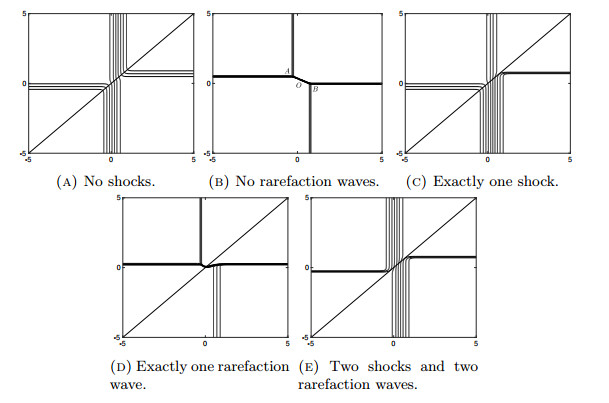

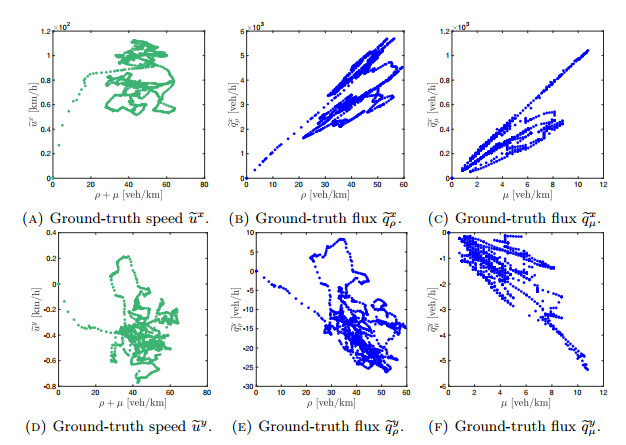
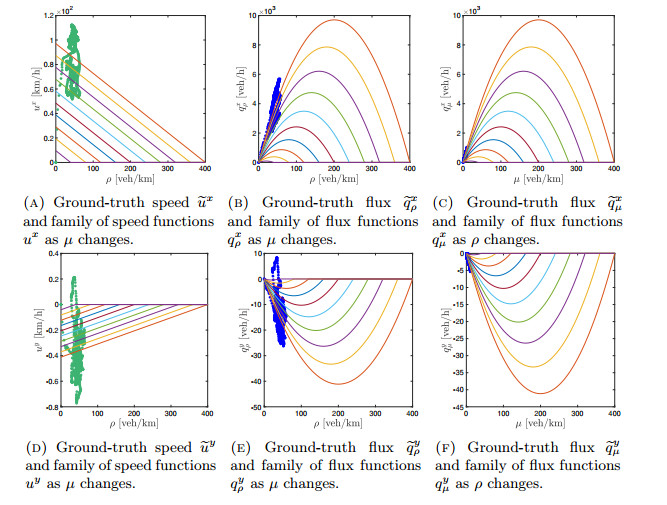
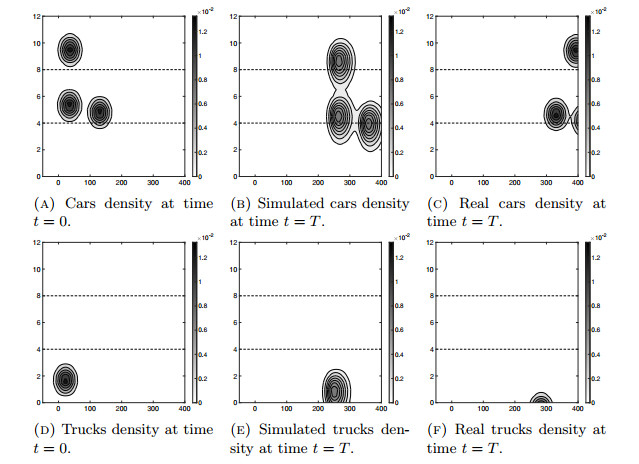
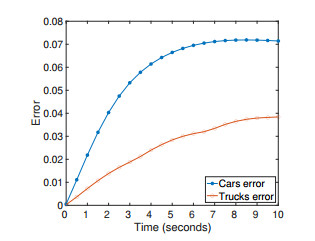
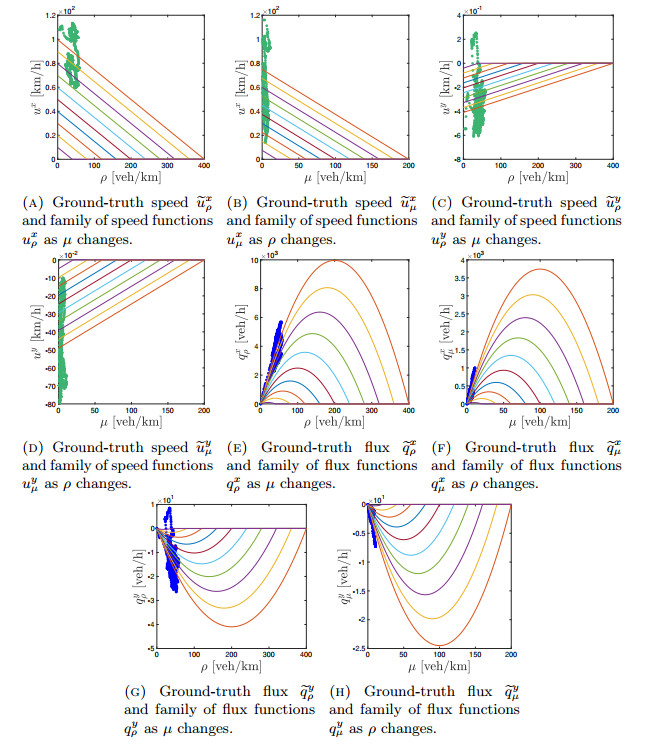
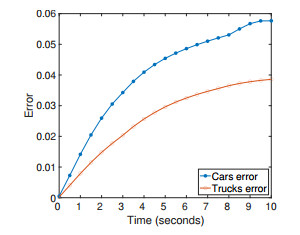
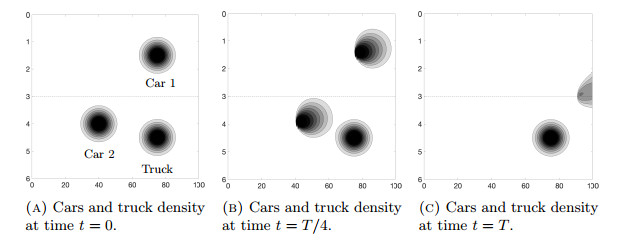
Figures(14)
Caterina Balzotti, Simone Göttlich. A two-dimensional multi-class traffic flow model[J]. Networks and Heterogeneous Media, 2021, 16(1): 69-90. doi: 10.3934/nhm.2020034







 DownLoad:
DownLoad: