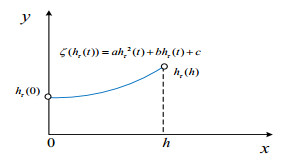
The focus of this paper was to explore the stability issues associated with delayed neural networks (DNNs). We introduced a novel approach that departs from the existing methods of using quadratic functions to determine the negative definite of the Lyapunov-Krasovskii functional's (LKFs) derivative $ \dot{V}(t) $. Instead, we proposed a new method that utilizes the conditions of positive definite quadratic function to establish the positive definiteness of LKFs. Based on this approach, we constructed a novel the relaxed LKF that contains delay information. In addition, some combinations of inequalities were extended and used to reduce the conservatism of the results obtained. The criteria for achieving delay-dependent asymptotic stability were subsequently presented in the framework of linear matrix inequalities (LMIs). Finally, a numerical example confirmed the effectiveness of the theoretical result.
Citation: Guoyi Li, Jun Wang, Kaibo Shi, Yiqian Tang. Some novel results for DNNs via relaxed Lyapunov functionals[J]. Mathematical Modelling and Control, 2024, 4(1): 110-118. doi: 10.3934/mmc.2024010
The focus of this paper was to explore the stability issues associated with delayed neural networks (DNNs). We introduced a novel approach that departs from the existing methods of using quadratic functions to determine the negative definite of the Lyapunov-Krasovskii functional's (LKFs) derivative $ \dot{V}(t) $. Instead, we proposed a new method that utilizes the conditions of positive definite quadratic function to establish the positive definiteness of LKFs. Based on this approach, we constructed a novel the relaxed LKF that contains delay information. In addition, some combinations of inequalities were extended and used to reduce the conservatism of the results obtained. The criteria for achieving delay-dependent asymptotic stability were subsequently presented in the framework of linear matrix inequalities (LMIs). Finally, a numerical example confirmed the effectiveness of the theoretical result.

| [1] |
Z. Tan, J. Chen, Q. Kang, M. Zhou, A. Abdullah, S. Khaled, Dynamic embedding projection-gated convolutional neural networks for text classification, IEEE Trans. Neural Networks Learn. Syst., 33 (2022), 973–982. https://doi.org/10.1109/TNNLS.2020.3036192 doi: 10.1109/TNNLS.2020.3036192

|
| [2] |
W. Niu, C. Ma, X. Sun, M. Li, Z. Gao, A brain network analysis-based double way deep neural network for emotion recognition, IEEE Trans. Neural Syst. Rehabil. Eng., 31 (2023), 917–925. https://doi.org/10.1109/TNSRE.2023.3236434 doi: 10.1109/TNSRE.2023.3236434
|
| [3] |
J. C. G. Diaz, H. Zhao, Y. Zhu, P. Samuel, H. Sebastian, Recurrent neural network equalization for wireline communication systems, IEEE Trans. Circuits Syst. II, 69 (2022), 2116–2120. https://doi.org/10.1109/TCSII.2022.3152051 doi: 10.1109/TCSII.2022.3152051
|
| [4] |
X. Li, R. Guo, J. Lu, T. Chen, X. Qian, Causality-driven graph neural network for early diagnosis of pancreatic cancer in non-contrast computerized tomography, IEEE Trans. Med. Imag., 42 (2023), 1656–1667. https://doi.org/10.1109/TMI.2023.3236162 doi: 10.1109/TMI.2023.3236162
|
| [5] |
F. Fang, Y. Liu, J. H. Park, Y. Liu, Outlier-resistant nonfragile control of T-S fuzzy neural networks with reaction-diffusion terms and its application in image secure communication, IEEE Trans. Fuzzy Syst., 31 (2023), 2929–2942. https://doi.org/10.1109/TFUZZ.2023.3239732 doi: 10.1109/TFUZZ.2023.3239732
|
| [6] |
Z. Zhang, J. Liu, G. Liu, J. Wang, J. Zhang, Robustness verification of swish neural networks embedded in autonomous driving systems, IEEE Trans. Comput. Soc. Syst., 10 (2023), 2041–2050. https://doi.org/10.1109/TCSS.2022.3179659 doi: 10.1109/TCSS.2022.3179659
|
| [7] |
S. Zhou, H. Xu, G. Zhang, T. Ma, Y. Yang, Leveraging deep convolutional neural networks pre-trained on autonomous driving data for vehicle detection from roadside LiDAR data, IEEE Trans. Intell. Transp. Syst., 23 (2022), 22367–22377. https://doi.org/10.1109/TITS.2022.3183889 doi: 10.1109/TITS.2022.3183889
|
| [8] |
Y. Bai, T. Chaolu, S. Bilige, The application of improved physics-informed neural network (IPINN) method in finance, Nonlinear Dyn., 107 (2022), 3655–3667. https://doi.org/10.1007/s11071-021-07146-z doi: 10.1007/s11071-021-07146-z
|
| [9] |
G. Rajchakit, R. Sriraman, Robust passivity and stability analysis of uncertain complex-valued impulsive neural networks with time-varying delays, Neural Process. Lett., 33 (2021), 581–606. https://doi.org/10.1007/s11063-020-10401-w doi: 10.1007/s11063-020-10401-w
|
| [10] |
A. Pratap, R. Raja, R. P. Agarwal, J. Alzabut, M. Niezabitowski, H. Evren, Further results on asymptotic and finite-time stability analysis of fractional-order time-delayed genetic regulatory networks, Neurocomputing, 475 (2022), 26–37. https://doi.org/10.1016/j.neucom.2021.11.088 doi: 10.1016/j.neucom.2021.11.088
|
| [11] |
G. Rajchakit, R. Sriraman, N. Boonsatit, P. Hammachukiattikul, C. P. Lim, P. Agarwal, Global exponential stability of Clifford-valued neural networks with time-varying delays and impulsive effects, Adv. Differ. Equations, 208 (2021), 26–37. https://doi.org/10.1186/s13662-021-03367-z doi: 10.1186/s13662-021-03367-z
|
| [12] |
H. Lin, H. Zeng, X. Zhang, W. Wang, Stability analysis for delayed neural networks via a generalized reciprocally convex inequality, IEEE Trans. Neural Networks Learn. Syst., 34 (2023), 7191–7499. https://doi.org/10.1109/TNNLS.2022.3144032 doi: 10.1109/TNNLS.2022.3144032
|
| [13] |
Z. Zhang, X. Zhang, T. Yu, Global exponential stability of neutral-type Cohen-Grossberg neural networks with multiple time-varying neutral and discrete delays, Neurocomputing, 490 (2022), 124–131. https://doi.org/10.1016/j.neucom.2022.03.068 doi: 10.1016/j.neucom.2022.03.068
|
| [14] |
H. Wang, Y. He, C. Zhang, Type-dependent average dwell time method and its application to delayed neural networks with large delays, IEEE Trans. Neural Networks Learn. Syst., 35 (2024), 2875–2880. https://doi.org/10.1109/TNNLS.2022.3184712 doi: 10.1109/TNNLS.2022.3184712
|
| [15] |
Z. Sheng, C. Lin, B. Chen, Q. Wang, Asymmetric Lyapunov-Krasovskii functional method on stability of time-delay systems, Int. J. Robust Nonlinear Control, 31 (2021), 2847–2854. https://doi.org/10.1002/rnc.5417 doi: 10.1002/rnc.5417
|
| [16] |
L. Guo, S. Huang, L. Wu, Novel delay-partitioning approaches to stability analysis for uncertain Lur'e systems with time-varying delays, J. Franklin Inst., 358 (2021), 3884–3900. https://doi.org/10.1016/j.jfranklin.2021.02.030 doi: 10.1016/j.jfranklin.2021.02.030
|
| [17] |
J. H. Kim, Further improvement of Jensen inequality and application to stability of time-delayed systems, Automatica, 64 (2016), 3884–3900. https://doi.org/10.1016/j.automatica.2015.08.025 doi: 10.1016/j.automatica.2015.08.025
|
| [18] |
J. Chen, X. Zhang, J. H. Park, S. Xu, Improved stability criteria for delayed neural networks using a quadratic function negative-definiteness approach, IEEE Trans. Neural Networks Learn. Syst., 33 (2020), 1348–1354. https://doi.org/10.1109/TNNLS.2020.3042307 doi: 10.1109/TNNLS.2020.3042307
|
| [19] |
G. Kong, L. Guo, Stability analysis of delayed neural networks based on improved quadratic function condition, Neurocomputing, 524 (2023), 158–166. https://doi.org/10.1016/j.neucom.2022.12.012 doi: 10.1016/j.neucom.2022.12.012
|
| [20] |
Z. Zhai, H. Yan, S. Chen, C. Chen, H. Zeng, Novel stability analysis methods for generalized neural networks with interval time-varying delay, Inf. Sci., 635 (2023), 208–220. https://doi.org/10.1016/j.ins.2023.03.041 doi: 10.1016/j.ins.2023.03.041
|
| [21] |
T. Lee, J. Park, M. Park, O. Kwon, H. Jung, On stability criteria for neural networks with time-varying delay using Wirtinger-based multiple integral inequality, J. Franklin Inst., 352 (2015), 5627–5645. https://doi.org/10.1016/j.jfranklin.2015.08.024 doi: 10.1016/j.jfranklin.2015.08.024
|
| [22] |
X. Zhang, Q. Han, X. Ge, The construction of augmented Lyapunov-Krasovskii functionals and the estimation of their derivatives in stability analysis of time-delay systems: a survey, Int. J. Syst. Sci., 53 (2022), 2480–2495. https://doi.org/10.1080/00207721.2021.2006356 doi: 10.1080/00207721.2021.2006356
|
| [23] |
L. V. Hien, H. Trinh, Refined Jensen-based inequality approach to stability analysis of time-delay systems, IET Control Theory Appl., 9 (2015), 2188–2194. https://doi.org/10.1049/iet-cta.2014.0962 doi: 10.1049/iet-cta.2014.0962
|
| [24] |
F. Yang, J. He, L. Li, Matrix quadratic convex combination for stability of linear systems with time-varying delay via new augmented Lyapunov functional, 2016 12th World Congress on Intelligent Control and Automation, 2016, 1866–1870. https://doi.org/10.1109/WCICA.2016.7578791 doi: 10.1109/WCICA.2016.7578791
|
| [25] |
C. Zhang, Y. He, L. Jiang, M. Wu, Stability analysis for delayed neural networks considering both conservativeness and complexity, IEEE Trans. Neural Networks Learn. Syst., 27 (2016), 1486–1501. https://doi.org/10.1109/TNNLS.2015.2449898 doi: 10.1109/TNNLS.2015.2449898
|
| [26] |
S. Ding, Z. Wang, Y. Wu, H. Zhang, Stability criterion for delayed neural networks via Wirtinger-based multiple integral inequality, Neurocomputing, 214 (2016), 53–60. https://doi.org/10.1016/j.neucom.2016.04.058 doi: 10.1016/j.neucom.2016.04.058
|
| [27] |
B. Yang, J. Wang, X. Liu, Improved delay-dependent stability criteria for generalized neural networks with time-varying delays, Inf. Sci., 214 (2017), 299–312. https://doi.org/10.1016/j.ins.2017.08.072 doi: 10.1016/j.ins.2017.08.072
|
| [28] |
B. Yang, J. Wang, J. Wang, Stability analysis of delayed neural networks via a new integral inequality, Neural Networks, 88 (2017), 49–57. https://doi.org/10.1016/j.neunet.2017.01.008 doi: 10.1016/j.neunet.2017.01.008
|
| [29] |
C. Hua, Y. Wang, S. Wu, Stability analysis of neural networks with time-varying delay using a new augmented Lyapunov-Krasovskii functional, Neurocomputing, 332 (2019), 1–9. https://doi.org/10.1016/j.neucom.2018.08.044 doi: 10.1016/j.neucom.2018.08.044
|







Figures(8) / Tables(1)
Guoyi Li, Jun Wang, Kaibo Shi, Yiqian Tang. Some novel results for DNNs via relaxed Lyapunov functionals[J]. Mathematical Modelling and Control, 2024, 4(1): 110-118. doi: 10.3934/mmc.2024010







 DownLoad:
DownLoad: