Patients diagnosed with diffuse large B-cell lymphoma (DLBCL) have high cure rates with current treatment options including immuno-polychemotherapy. However, around 30% of cases do not respond or develop relapse disease. For this, it is necessary to search for new therapeutic options. In recent years, therapy using chimeric antigen receptor (CAR) T-cells has been a strategy for those patients with LBDCG in progression or relapse, although only 30–40% of cases achieve durable remissions. The programmed death-1 (PD-1) receptor regulates the T-cell-mediated immune response through binding to its ligands (PD-L1). Some tumor cells present high expression of PD-L1, which down-regulates T-cell activation. The beneficial antitumor activity of PD-1 and PD-L1 has been widely demonstrated in certain solid organ malignancies. However, their utility in the treatment of lymphomas is complex. To date, different clinical trials have demonstrated its usefulness as an innovative therapeutic alternative in these tumors. In this review article, we evaluate the literature on the role of the PD-1/PD-L1 pathway in DLBCL and describe future strategies involving these new anticancer agents in this lymphoid neoplasm.
Citation: Luis Miguel Juárez-Salcedo, Luis Manuel González, Samir Dalia. Immunotherapy for diffuse large B-cell lymphoma: current use of immune checkpoint inhibitors therapy[J]. AIMS Medical Science, 2023, 10(3): 259-272. doi: 10.3934/medsci.2023020
Patients diagnosed with diffuse large B-cell lymphoma (DLBCL) have high cure rates with current treatment options including immuno-polychemotherapy. However, around 30% of cases do not respond or develop relapse disease. For this, it is necessary to search for new therapeutic options. In recent years, therapy using chimeric antigen receptor (CAR) T-cells has been a strategy for those patients with LBDCG in progression or relapse, although only 30–40% of cases achieve durable remissions. The programmed death-1 (PD-1) receptor regulates the T-cell-mediated immune response through binding to its ligands (PD-L1). Some tumor cells present high expression of PD-L1, which down-regulates T-cell activation. The beneficial antitumor activity of PD-1 and PD-L1 has been widely demonstrated in certain solid organ malignancies. However, their utility in the treatment of lymphomas is complex. To date, different clinical trials have demonstrated its usefulness as an innovative therapeutic alternative in these tumors. In this review article, we evaluate the literature on the role of the PD-1/PD-L1 pathway in DLBCL and describe future strategies involving these new anticancer agents in this lymphoid neoplasm.

| [1] |
Swerdlow SH, Campo E, Pileri SA, et al. (2016) The 2016 revision of the World Health Organization classification of lymphoid neoplasms. Blood 127: 2375-2390. https://doi.org/10.1182/blood-2016-01-643569 
|
| [2] |
Alaggio R, Amador C, Anagnostopoulos I, et al. (2022) The 5th edition of the World Health Organization classification of haematolymphoid tumours: lymphoid neoplasms. Leukemia 36: 1720-1748. https://doi.org/10.1038/s41375-022-01620-2
|
| [3] |
Keane C, Vari F, Hertzberg M, et al. (2015) Ratios of T-cell immune effectors and checkpoint molecules as prognostic biomarkers in diffuse large B-cell lymphoma: A population-based study. Lancet Haematol 2: e445-455. https://doi.org/10.1016/S2352-3026(15)00150-7
|
| [4] |
Purroy N, Bergua J, Gallur L, et al. (2015) Long-term follow-up of dose-adjusted EPOCH plus rituximab (DA-EPOCH-R) in untreated patients with poor prognosis large B-cell lymphoma. A phase II study conducted by the Spanish PETHEMA group. Br J Haematol 169: 188-198. https://doi.org/10.1111/bjh.13273
|
| [5] | Major A, Smith SM (2021) DA-R-EPOCH vs R-CHOP in DLBCL: how do we choose?. Clin Adv Hematol Oncol 19: 698-709. |
| [6] |
Dunleavy K (2018) Approach to the diagnosis and treatment of adult Burkitt's lymphoma. J Oncol Pract 14: 665-671. https://doi.org/10.1200/JOP.18.00148
|
| [7] |
Howlett C, Snedecor SJ, Landsburg DJ, et al. (2015) Front-line, dose-escalated immunochemotherapy is associated with a significant progression-free survival advantage in patients with double-hit lymphomas: A systematic review and meta-analysis. Br J Haematol 170: 504-514. https://doi.org/10.1111/bjh.13463
|
| [8] |
Gisselbrecht C, Glass B, Mounier N, et al. (2010) Salvage regimens with autologous transplantation for relapsed large B-cell lymphoma in the rituximab era. J Clin Oncol 28: 4184-4190. https://doi.org/10.1200/JCO.2010.28.1618
|
| [9] |
Crump M, Kuruvilla J, Couban S, et al. (2014) Randomized comparison of gemcitabine, dexamethasone, and cisplatin versus dexamethasone, cytarabine, and cisplatin chemotherapy before autologous stem-cell transplantation for relapsed and refractory aggressive lymphomas: NCIC-CTG LY.12. J Clin Oncol 32: 3490-3496. https://doi.org/10.1200/JCO.2013.53.9593
|
| [10] |
Crump M, Neelapu SS, Farooq U, et al. (2017) Outcomes in refractory diffuse large B-cell lymphoma: results from the international SCHOLAR-1 study. Blood 130: 1800-1808. https://doi.org/10.1182/blood-2017-03-769620
|
| [11] |
Locke F, Miklos DB, Jacobson C, et al. (2021) Primary analysis of ZUMA‑7: A phase 3 randomized trial of axicabtagene ciloleucel (Axi-Cel) versus standard‑of‑care therapy in patients with relapsed/refractory large B-cell lymphoma. Blood 138: 2. https://doi.org/10.1182/blood-2021-148039
|
| [12] |
Kamdar M, Solomon SR, Arnason J, et al. (2022) Lisocabtagene maraleucel versus standard of care with salvage chemotherapy followed by autologous stem cell transplantation as second-line treatment in patients with relapsed or refractory large B-cell lymphoma (TRANSFORM): results from an interim analysis of an open-label, randomised, phase 3 trial. Lancet 399: 2294-2308. https://doi.org/10.1016/S0140-6736(22)00662-6
|
| [13] |
Nastoupil LJ, Jain MD, Feng L, et al. (2020) Standard-of-care axicabtagene ciloleucel for relapsed or refractory large B-cell lymphoma: results from the US lymphoma CAR T consortium. J Clin Oncol 38: 3119-3128. https://doi.org/10.1200/JCO.19.02104
|
| [14] |
Schuster SJ, Svoboda J, Chong EA, et al. (2017) Chimeric antigen receptor T cells in refractory B-cell lymphomas. N Engl J Med 377: 2545-2554. https://doi.org/10.1056/NEJMoa1708566
|
| [15] |
Schuster SJ, Tam CS, Borchmann P, et al. (2021) Long-term clinical outcomes of tisagenlecleucel in patients with relapsed or refractory aggressive B-cell lymphomas (JULIET): A multicentre, open-label, single-arm, phase 2 study. Lancet Oncol 22: 1403-1415. https://doi.org/10.1016/S1470-2045(21)00375-2
|
| [16] |
Zhang X, Schwartz JCD, Guo X, et al. (2004) Structural and functional analysis of the costimulatory receptor programmed death-1. Immunity 20: 337-347. https://doi.org/10.1016/s1074-7613(04)00051-2
|
| [17] |
Dermani FK, Samadi P, Rahmani G, et al. (2019) PD-1/PD-L1 immune checkpoint: potential target for cancer therapy. J Cell Physiol 234: 1313-1325. https://doi.org/10.1002/jcp.27172
|
| [18] |
Chatterjee P, Patsoukis N, Freeman GJ, et al. (2013) Distinct roles of PD-1 ITSM and ITIM in regulating interactions with SHP-2, ZAP-70 and Lck, and PD-1-mediated inhibitory function. Blood 122: 191. https://doi.org/10.1182/blood.V122.21.191.191
|
| [19] |
Youngnak P, Kozono Y, Kozono H, et al. (2003) Differential binding properties of B7-H1 and B7-DC to programmed death-1. Biochem Biophys Res Commun 307: 672-677. https://doi.org/10.1016/s0006-291x(03)01257-9
|
| [20] |
Juárez-Salcedo LM, Sandoval-Sus J, Sokol L, et al. (2017) The role of anti-PD-1 and anti-PD-L1 agents in the treatment of diffuse large B-cell lymphoma: the future is now. Crit Rev Oncol Hematol 113: 52-62. https://doi.org/10.1016/j.critrevonc.2017.02.027
|
| [21] |
Xu-Monette ZY, Zhou J, Young KH (2018) PD-1 expression and clinical PD-1 blockade in B-cell lymphomas. Blood 131: 68-83. https://doi.org/10.1182/blood-2017-07-740993
|
| [22] |
Cioroianu AI, Stinga PI, Sticlaru L, et al. (2019) Tumor microenvironment in diffuse large B-Cell lymphoma: role and prognosis. Anal Cell Pathol 2019: 8586354. https://doi.org/10.1155/2019/8586354
|
| [23] |
Ansell SM (2016) Where do programmed death-1 inhibitors fit in the management of malignant lymphoma?. J Oncol Pract 12: 101-106. https://doi.org/10.1200/JOP.2015.009191
|
| [24] |
Sun C, Mezzadra R, Schumacher TN (2018) Regulation and function of the PD-L1 checkpoint. Immunity 48: 434-452. https://doi.org/10.1016/j.immuni.2018.03.014
|
| [25] |
Song MK, Park BB, Uhm J (2019) Understanding immune evasion and therapeutic targeting associated with PD-1/PD-L1 pathway in diffuse large B-cell lymphoma. Int J Mol Sci 20: 1326. https://doi.org/10.3390/ijms20061326
|
| [26] |
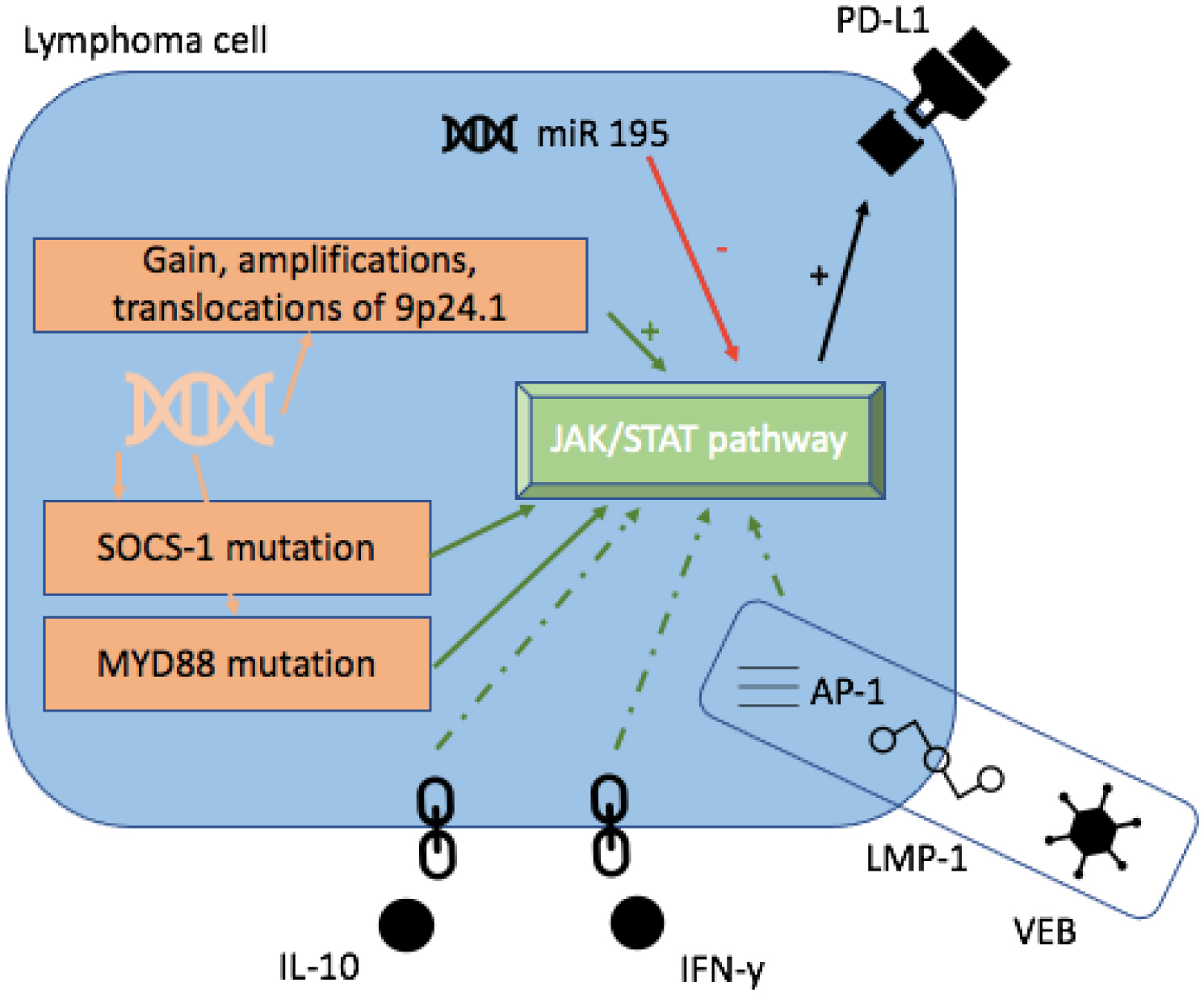
Georgiou K, Chen L, Berglund M, et al. (2016) Genetic basis of PD-L1 overexpression in diffuse large B-cell lymphomas. Blood 127: 3026-3034. https://doi.org/10.1182/blood-2015-12-686550
|
| [27] |
Satou A, Nakamura S (2021) EBV-positive B-cell lymphomas and lymphoproliferative disorders: review from the perspective of immune escape and immunodeficiency. Cancer Med 10: 6777-6785. https://doi.org/10.1002/cam4.4198
|
| [28] |
Shi Y, Liu Z, Lin Q, et al. (2021) MiRNAs and cancer: key link in diagnosis and therapy. Genes 12: 1289. https://doi.org/10.3390/genes12081289
|
| [29] |
He B, Yan F, Wu C (2018) Overexpressed miR-195 attenuated immune escape of diffuse large B-cell lymphoma by targeting PD-L1. Biomed Pharmacother 98: 95-101. https://doi.org/10.1016/j.biopha.2017.11.146
|
| [30] |
Ansell SM, Minnema MC, Johnson P, et al. (2019) Nivolumab for relapsed/refractory diffuse large B-cell lymphoma in patients ineligible for or having failed autologous transplantation: A single-arm, phase II study. J Clin Oncol 37: 481-489. https://doi.org/10.1200/JCO.18.00766
|
| [31] |
Godfrey J, Tumuluru S, Bao R, et al. (2019) PD-L1 gene alterations identify a subset of diffuse large B-cell lymphoma harboring a T-cell-inflamed phenotype. Blood 133: 2279-2290. https://doi.org/10.1182/blood-2018-10-879015
|
| [32] |
Hu LY, Xu XL, Rao HL, et al. (2017) Expression and clinical value of programmed cell death-ligand 1 (PD-L1) in diffuse large B cell lymphoma: A retrospective study. Chin J Cancer 36: 94. https://doi.org/10.1186/s40880-017-0262-z
|
| [33] |
Roemer MGM, Advani RH, Ligon AH, et al. (2016) PD-L1 and PD-L2 genetic alterations define classical hodgkin lymphoma and predict outcome. J Clin Oncol 34: 2690-2697. https://doi.org/10.1200/JCO.2016.66.4482
|
| [34] |
Kiyasu J, Miyoshi H, Hirata A, et al. (2015) Expression of programmed cell death ligand 1 is associated with poor overall survival in patients with diffuse large B-cell lymphoma. Blood 126: 2193-2201. https://doi.org/10.1182/blood-2015-02-629600
|
| [35] |
Andorsky DJ, Yamada RE, Said J, et al. (2011) Programmed death ligand 1 is expressed by non-hodgkin lymphomas and inhibits the activity of tumor-associated T cells. Clin Cancer Res 17: 4232-4244. https://doi.org/10.1158/1078-0432.CCR-10-2660
|
| [36] |
Tuscano JM, Maverakis E, Groshen S, et al. (2019) A phase I study of the combination of rituximab and ipilimumab in patients with relapsed/refractory B-cell lymphoma. Clin Cancer Res 25: 7004-7013. https://doi.org/10.1158/1078-0432.CCR-19-0438
|
| [37] |
Zhang J, Medeiros LJ, Young KH (2018) Cancer immunotherapy in diffuse large B-cell lymphoma. Front Oncol 8: 351. https://doi.org/10.3389/fonc.2018.00351
|
| [38] |
Lesokhin AM, Ansell SM, Armand P, et al. (2016) Nivolumab in patients with relapsed or refractory hematologic malignancy: preliminary results of a phase Ib study. J Clin Oncol 34: 2698-2704. https://doi.org/10.1200/JCO.2015.65.9789
|
| [39] |
Smith SD, Till BG, Shadman MS, et al. (2020) Pembrolizumab with R-CHOP in previously untreated diffuse large B-cell lymphoma: potential for biomarker driven therapy. Br J Haematol 189: 1119-1126. https://doi.org/10.1111/bjh.16494
|
| [40] |
Green MR, Monti S, Rodig SJ, et al. (2010) Integrative analysis reveals selective 9p24.1 amplification, increased PD-1 ligand expression, and further induction via JAK2 in nodular sclerosing Hodgkin lymphoma and primary mediastinal large B-cell lymphoma. Blood 116: 3268-3277. https://doi.org/10.1182/blood-2010-05-282780
|
| [41] |
Camus V, Bigenwald C, Ribrag V, et al. (2021) Pembrolizumab in the treatment of refractory primary mediastinal large B-cell lymphoma: safety and efficacy. Expert Rev Anticancer Ther 21: 941-956. https://doi.org/10.1080/14737140.2021.1953986
|
| [42] |
Shah NJ, Kelly WJ, Liu SV, et al. (2018) Product review on the Anti-PD-L1 antibody atezolizumab. Hum Vaccin Immunother 14: 269-276. https://doi.org/10.1080/21645515.2017.1403694
|
| [43] |
Younes A, Burke JM, Cheson BD, et al. (2023) Safety and efficacy of atezolizumab with rituximab and CHOP in previously untreated diffuse large B-cell lymphoma. Blood Adv 7: 1488-1495. https://doi.org/10.1182/bloodadvances.2022008344
|
| [44] |
Palomba ML, Till BG, Park SI, et al. (2022) Combination of atezolizumab and obinutuzumab in patients with relapsed/refractory follicular lymphoma and diffuse large B-cell lymphoma: results from a phase 1b study. Clin Lymphoma Myeloma Leuk 22: e443-e451. https://doi.org/10.1016/j.clml.2021.12.010
|
| [45] |
Palomba ML, Cartron G, Popplewell L, et al. (2022) Combination of atezolizumab and tazemetostat in patients with relapsed/refractory diffuse large B-cell lymphoma: results from a phase Ib study. Clin Lymphoma Myeloma Leuk 22: 504-512. https://doi.org/10.1016/j.clml.2021.12.014
|
| [46] |
Jeanson A, Barlesi F (2017) MEDI 4736 (durvalumab) in non-small cell lung cancer. Expert Opin Biol Ther 17: 1317-1323. https://doi.org/10.1080/14712598.2017.1351939
|
| [47] |
Nowakowski GS, Willenbacher W, Greil R, et al. (2022) Safety and efficacy of durvalumab with R-CHOP or R2-CHOP in untreated, high-risk DLBCL: A phase 2, open-label trial. Int J Hematol 115: 222-232. https://doi.org/10.1007/s12185-021-03241-4
|
Figures(1) / Tables(1)

Luis Miguel Juárez-Salcedo, Luis Manuel González, Samir Dalia. Immunotherapy for diffuse large B-cell lymphoma: current use of immune checkpoint inhibitors therapy[J]. AIMS Medical Science, 2023, 10(3): 259-272. doi: 10.3934/medsci.2023020







 DownLoad:
DownLoad: