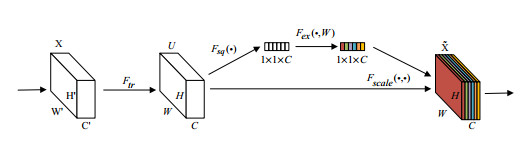
For wearable electrocardiogram (ECG) acquisition, it was easy to infer motion artifices and other noises. In this paper, a novel end-to-end ECG denoising method was proposed, which was implemented by fusing the Efficient Channel Attention (ECA-Net) and the cycle consistent generative adversarial network (CycleGAN) method. The proposed denoising model was optimized by using the ECA-Net method to highlight the key features and introducing a new loss function to further extract the global and local ECG features. The original ECG signal came from the MIT-BIH Arrhythmia Database. Additionally, the noise signals used in this method consist of a combination of Gaussian white noise and noises sourced from the MIT-BIH Noise Stress Test Database, including EM (Electrode Motion Artifact), BW (Baseline Wander) and MA (Muscle Artifact), as well as mixed noises composed of EM+BW, EM+MA, BW+MA and EM+BW+MA. Moreover, corrupted ECG signals were generated by adding different levels of single and mixed noises to clean ECG signals. The experimental results show that the proposed method has better denoising performance and generalization ability with higher signal-to-noise ratio improvement (SNRimp), as well as lower root-mean-square error (RMSE) and percentage-root-mean-square difference (PRD).
Citation: Peng Zhang, Mingfeng Jiang, Yang Li, Ling Xia, Zhefeng Wang, Yongquan Wu, Yaming Wang, Huaxiong Zhang. An efficient ECG denoising method by fusing ECA-Net and CycleGAN[J]. Mathematical Biosciences and Engineering, 2023, 20(7): 13415-13433. doi: 10.3934/mbe.2023598
For wearable electrocardiogram (ECG) acquisition, it was easy to infer motion artifices and other noises. In this paper, a novel end-to-end ECG denoising method was proposed, which was implemented by fusing the Efficient Channel Attention (ECA-Net) and the cycle consistent generative adversarial network (CycleGAN) method. The proposed denoising model was optimized by using the ECA-Net method to highlight the key features and introducing a new loss function to further extract the global and local ECG features. The original ECG signal came from the MIT-BIH Arrhythmia Database. Additionally, the noise signals used in this method consist of a combination of Gaussian white noise and noises sourced from the MIT-BIH Noise Stress Test Database, including EM (Electrode Motion Artifact), BW (Baseline Wander) and MA (Muscle Artifact), as well as mixed noises composed of EM+BW, EM+MA, BW+MA and EM+BW+MA. Moreover, corrupted ECG signals were generated by adding different levels of single and mixed noises to clean ECG signals. The experimental results show that the proposed method has better denoising performance and generalization ability with higher signal-to-noise ratio improvement (SNRimp), as well as lower root-mean-square error (RMSE) and percentage-root-mean-square difference (PRD).

| [1] |
J. Wang, R. Li, R. Li, B. Fu, A knowledge-based deep learning method for ECG signal delineation, Future Gener. Comput. Syst., 109 (2020), 56−66. https://doi.org/10.1016/j.future.2020.02.068 doi: 10.1016/j.future.2020.02.068

|
| [2] | J. Y. Seo, Y. H. Noh, D. U. Jeong, Research of the deep learning model for denoising of ECG signal and classification of arrhythmias, in International Conference on Intelligent Human Computer Interaction, (2022), 198−204. https://doi.org/10.1007/978-3-030-98404-5_19 |
| [3] |
P. Singh, G. Pradhan, S. Shahnawazuddin, Denoising of ECG signal by non-local estimation of approximation coefficients in DWT, Biocybern. Biomed. Eng., 37 (2017), 599−610. https://doi.org/10.1016/j.bbe.2017.06.001 doi: 10.1016/j.bbe.2017.06.001
|
| [4] |
H. Hao, H. Wang, N. ur Rehman, L. Chen, H. Tian, An improved multivariate wavelet denoising method using subspace projection, IEICE Trans. Fundamentals Electron. Commun. Comput. Sci., 100 (2017), 769−775. https://doi.org/10.1587/transfun.E100.A.769 doi: 10.1587/transfun.E100.A.769
|
| [5] |
Z. Wang, J. Zhu, T. Yan, L. Yang, A new modified wavelet-based ECG denoising, Comput. Assisted Surg., 24 (2019), 174−183. https://doi.org/10.1080/24699322.2018.1560088 doi: 10.1080/24699322.2018.1560088
|
| [6] |
Y. Ye, W. He, Y. Cheng, W. Huang, Z. Zhang, A robust random forest-based approach for heart rate monitoring using photoplethysmography signal contaminated by intense motion artifacts, Sensors, 17 (2017), 385. https://doi.org/10.3390/s17020385 doi: 10.3390/s17020385
|
| [7] |
M. Zhang, G. Wei, An integrated EMD adaptive threshold denoising method for reduction of noise in ECG, PLoS One, 15 (2020), e0235330. https://doi.org/10.1371/journal.pone.0235330 doi: 10.1371/journal.pone.0235330
|
| [8] |
D. Zhang, S. Wang, F. Li, S. Tian, J. Wang, X. Ding, et al., An efficient ECG denoising method based on empirical mode decomposition, sample entropy, and improved threshold function, Wireless Commun. Mobile Comput., 2020 (2020). https://doi.org/10.1155/2020/8811962 doi: 10.1155/2020/8811962
|
| [9] | W. He, Y. Ye, Y. Li, H. Xu, L. Lu, W. Huang, et al., Variational mode decomposition-based heart rate estimation using wrist-type photoplethysmography during physical exercise, in 2018 24th International Conference on Pattern Recognition (ICPR), (2018), 3766−3771. https://doi.org/10.1109/ICPR.2018.8545685 |
| [10] | Y. Wang, D. Bai, Application of wavelet threshold method based on optimized VMD to ECG denoising, in 2021 IEEE 3rd International Conference on Frontiers Technology of Information and Computer (ICFTIC), (2021), 741−744. https://doi.org/10.1109/ICFTIC54370.2021.9647050 |
| [11] |
B. Yang, Y. Dong, C. Yu, Z. Hou, Singular spectrum analysis window length selection in processing capacitive captured biopotential signals, IEEE Sens. J., 16 (2016), 7183–7193. https://doi.org/10.1109/JSEN.2016.2594189 doi: 10.1109/JSEN.2016.2594189
|
| [12] |
S. K. Mukhopadhyay, S. Krishnan, A singular spectrum analysis-based model-free electrocardiogram denoising technique, Comput. Methods Programs Biomed., 188 (2020), 1−15. https://doi.org/10.1016/j.cmpb.2019.105304 doi: 10.1016/j.cmpb.2019.105304
|
| [13] |
H. Sharma, K. K. Sharma, Baseline wander removal of ECG signals using Hilbert vibration decomposition, Electron. Lett., 51 (2015), 447−449. https://doi.org/10.1049/el.2014.4076 doi: 10.1049/el.2014.4076
|
| [14] |
B. R. Manju, M. R. Sneha, ECG denoising using wiener filter and kalman filter, Procedia Comput. Sci., 171 (2020), 273−281. https://doi.org/10.1016/j.procs.2020.04.029 doi: 10.1016/j.procs.2020.04.029
|
| [15] |
S. M. Qaisar, Baseline wander and power-line interference elimination of ECG signals using efficient signal-piloted filtering, Healthcare Technol. Lett., 7 (2020), 114−118. https://doi.org/10.1049/htl.2019.0116 doi: 10.1049/htl.2019.0116
|
| [16] |
S. A. Malik, S. A. Parah, B. A. Malik, Power line noise and baseline wander removal from ECG signals using empirical mode decomposition and lifting wavelet transform technique, Health Tech., 12 (2022), 745−756. https://doi.org/10.1007/s12553-022-00662-x doi: 10.1007/s12553-022-00662-x
|
| [17] |
B. Liu, Y. Li, ECG signal denoising based on similar segments cooperative filtering, Biomed. Signal Process. Control, 68 (2021), 102751. https://doi.org/10.1016/j.bspc.2021.102751 doi: 10.1016/j.bspc.2021.102751
|
| [18] |
J. Wang, Y. Ye, X. Pan, X. Gao, Parallel-type fractional zero-phase filtering for ECG signal denoising, Biomed. Signal Process. Control, 18 (2015), 36–41. https://doi.org/10.1016/j.bspc.2014.10.012 doi: 10.1016/j.bspc.2014.10.012
|
| [19] |
G. Wang, L. Yang, M. Liu, X. Yuan, P. Xiong, F. Lin, et al., ECG signal denoising based on deep factor analysis, Biomed. Signal Process. Control, 57 (2020), 101824. https://doi.org/10.1016/j.bspc.2019.101824 doi: 10.1016/j.bspc.2019.101824
|
| [20] | J. Y. Zhu, T. Park, P. Isola, A. A. Efros, Unpaired image-to-image translation using cycle-consistent adversarial networks, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 2223−2232. https://doi.org/10.1109/ICCV.2017.244 |
| [21] |
S. Kiranyaz, O. C. Devecioglu, T. Ince, J. Malik, M. Chowdhury, T. Hamid, et al., Blind ECG restoration by operational cycle-GANs, IEEE Trans. Biomed. Eng., 69 (2022), 3572−3581. https://doi.org/10.1109/TBME.2022.3172125 doi: 10.1109/TBME.2022.3172125
|
| [22] |
S. Kiranyaz, J. Malik, H. B. Abdallah, T. Ince, A. Iosifidis, M. Gabbouj, Self-organized operational neural networks with generative neurons, Neural Networks, 140 (2021), 294−308. https://doi.org/10.1016/j.neunet.2021.02.028 doi: 10.1016/j.neunet.2021.02.028
|
| [23] |
J. Malik, S. Kiranyaz, M. Gabbouj, Self-organized operational neural networks for severe image restoration problems, Neural Networks, 135 (2021), 201−211. https://doi.org/10.1016/j.neunet.2020.12.014 doi: 10.1016/j.neunet.2020.12.014
|
| [24] | K. Antczak, Deep recurrent neural networks for ECG signal denoising, preprint, arXiv: 1807.11551. |
| [25] | V. Mnih, N. Heess, A. Graves, K. Kavukcuoglu, Recurrent models of visual attention, in Proceedings of the 27th International Conference on Neural Information Processing Systems, 2 (2014), 2204−2212. Available from: https://proceedings.neurips.cc/paper/2014/file/09c6c3783b4a70054da74f2538ed47c6-Paper.pdf. |
| [26] |
L. Qiu, W. Cai, M. Zhang, W. Zhu, L. Wang, Two-stage ECG signal denoising based on deep convolutional network, Physiol. Meas., 42 (2021), 115002. https://doi.org/10.1088/1361-6579/ac34ea doi: 10.1088/1361-6579/ac34ea
|
| [27] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 7132−7141. https://doi.org/10.1109/cvpr.2018.00745 |
| [28] | Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, Q. Hu, ECA-Net: efficient channel attention for deep convolutional neural networks, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 11531−11539. https://doi.org/10.1109/cvpr42600.2020.01155 |
| [29] |
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial networks, Commun. ACM, 63 (2020), 139−144. https://doi.org/10.1145/3422622 doi: 10.1145/3422622
|
| [30] | T. Zhou, P. Krähenbühl, M. Aubry, Q. Huang, A. A. Efros, Learning dense correspondence via 3d-guided cycle consistency, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 117−126. https://doi.org/10.1109/cvpr.2016.20 |
| [31] |
S. Pascual, A. Bonafonte, J. Serra, SEGAN: Speech enhancement generative adversarial network, Proc. Interspeech, (2017), 3642–3646. https://doi.org/10.21437/interspeech.2017-1428 doi: 10.21437/interspeech.2017-1428
|
| [32] |
J. Wang, R. Li, R. Li, K. Li, H. Zeng, G. Xie, et al., Adversarial de-noising of electrocardiogram, Neurocomputing, 349 (2019), 212−224. https://doi.org/10.1016/j.neucom.2019.03.083 doi: 10.1016/j.neucom.2019.03.083
|
| [33] |
Z. Wang, F. Wan, C. M. Wong, L. Zhang, Adaptive Fourier decomposition based ECG denoising, Comput. Biol. Med., 77 (2016), 195−205. https://doi.org/10.1016/j.compbiomed.2016.08.013 doi: 10.1016/j.compbiomed.2016.08.013
|








Figures(9) / Tables(5)

Peng Zhang, Mingfeng Jiang, Yang Li, Ling Xia, Zhefeng Wang, Yongquan Wu, Yaming Wang, Huaxiong Zhang. An efficient ECG denoising method by fusing ECA-Net and CycleGAN[J]. Mathematical Biosciences and Engineering, 2023, 20(7): 13415-13433. doi: 10.3934/mbe.2023598







 DownLoad:
DownLoad: