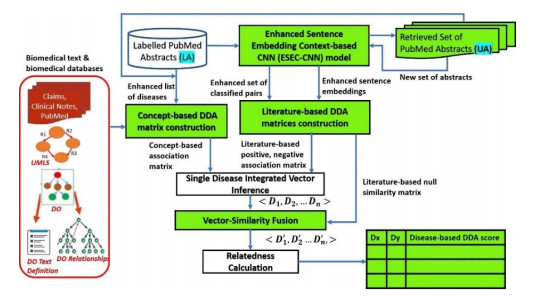
Objective: Quantification of disease-disease association (DDA) enables the understanding of disease relationships for discovering disease progression and finding comorbidity. For effective DDA strength calculation, there is a need to address the main challenge of integration of various biomedical aspects of DDA is to obtain an information rich disease representation. Materials and Methods: An enhanced and integrated DDA framework is developed that integrates enriched literature-based with concept-based DDA representation. The literature component of the proposed framework uses PubMed abstracts and consists of improved neural network model that classifies DDAs for an enhanced literaturebased DDA representation. Similarly, an ontology-based joint multi-source association embedding model is proposed in the ontology component using Disease Ontology (DO), UMLS, claims insurance, clinical notes etc. Results and Discussion: The obtained information rich disease representation is evaluated on different aspects of DDA datasets such as Gene, Variant, Gene Ontology (GO) and a human rated benchmark dataset. The DDA scores calculated using the proposed method achieved a high correlation mainly in gene-based dataset. The quantified scores also shown better correlation of 0.821, when evaluated on human rated 213 disease pairs. In addition, the generated disease representation is proved to have substantial effect on correlation of DDA scores for different categories of disease pairs. Conclusion: The enhanced context and semantic DDA framework provides an enriched disease representation, resulting in high correlated results with different DDA datasets. We have also presented the biological interpretation of disease pairs. The developed framework can also be used for deriving the strength of other biomedical associations.
Citation: Karpaga Priyaa Kartheeswaran, Arockia Xavier Annie Rayan, Geetha Thekkumpurath Varrieth. Enhanced disease-disease association with information enriched disease representation[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 8892-8932. doi: 10.3934/mbe.2023391
Objective: Quantification of disease-disease association (DDA) enables the understanding of disease relationships for discovering disease progression and finding comorbidity. For effective DDA strength calculation, there is a need to address the main challenge of integration of various biomedical aspects of DDA is to obtain an information rich disease representation. Materials and Methods: An enhanced and integrated DDA framework is developed that integrates enriched literature-based with concept-based DDA representation. The literature component of the proposed framework uses PubMed abstracts and consists of improved neural network model that classifies DDAs for an enhanced literaturebased DDA representation. Similarly, an ontology-based joint multi-source association embedding model is proposed in the ontology component using Disease Ontology (DO), UMLS, claims insurance, clinical notes etc. Results and Discussion: The obtained information rich disease representation is evaluated on different aspects of DDA datasets such as Gene, Variant, Gene Ontology (GO) and a human rated benchmark dataset. The DDA scores calculated using the proposed method achieved a high correlation mainly in gene-based dataset. The quantified scores also shown better correlation of 0.821, when evaluated on human rated 213 disease pairs. In addition, the generated disease representation is proved to have substantial effect on correlation of DDA scores for different categories of disease pairs. Conclusion: The enhanced context and semantic DDA framework provides an enriched disease representation, resulting in high correlated results with different DDA datasets. We have also presented the biological interpretation of disease pairs. The developed framework can also be used for deriving the strength of other biomedical associations.

| [1] |
M. Žitnik, V. Janjić, C. Larminie, B. Zupan, N. Pržulj, Discovering disease- disease associations by fusing systems-level molecular data, Sci. Rep., 3 (2013), 1–9. https://doi.org/10.1038/srep03202 doi: 10.1038/srep03202

|
| [2] |
S. Bang, J. H. Kim, H. Shin, Causality modeling for directed disease network, Bioinformatics, 32 (2016), 437–444. https://doi.org/10.1093/bioinformatics/btw439 doi: 10.1093/bioinformatics/btw439
|
| [3] |
A. Suratanee, K. Plaimas, DDA: A novel network-based scoring method to identify disease-disease associations, Bioinform. Biol. Insights, 9 (2015), 175–186. https://doi.org/10.4137/bbi.s35237 doi: 10.4137/bbi.s35237
|
| [4] |
J. Yang, S. J. Wu, S. Y. Yang, J. W. Peng, S. N. Wang, F. Y. Wang, et al., DNetDB: The human disease network database based on dysfunctional regulation mechanism, BMC Syst. Biol., 10 (2016), 1–8. https://doi.org/10.1186/s12918-016-0280-5 doi: 10.1186/s12918-016-0280-5
|
| [5] |
J. Li, B. Gong, X. Chen, T. Liu, C. Wu, F. Zhang, et al., DOSim: An R package for similarity between diseases based on disease ontology, BMC Bioinformatics., 12 (2011), 1–10. https://doi.org/10.1186/1471-2105-12-266 doi: 10.1186/1471-2105-12-266
|
| [6] |
D. A. Davis, N. V. Chawla, Exploring and exploiting disease interactions from multi-relational gene and phenotype networks, PLoS One, 6 (2011), 22670. https://doi.org/10.1371/journal.pone.0022670 doi: 10.1371/journal.pone.0022670
|
| [7] |
Y. Li, P. Agarwal, A pathway-based view of human diseases and disease relationships, PLoS One, 4 (2009), 4346. https://doi.org/10.1371/journal.pone.0004346 doi: 10.1371/journal.pone.0004346
|
| [8] |
S. S. Deepika, T. V. Geetha, Pattern-based bootstrapping framework for biomedical relation extraction, Eng. Appl. Artif. Intell., 99 (2021), 104130. https://doi.org/10.1016/j.engappai.2020.104130 doi: 10.1016/j.engappai.2020.104130
|
| [9] |
C. A. Hidalgo, N. Blumm, A. L. Barabási, N. A. Christakis, A dynamic network approach for the study of human phenotypes, PLoS Comput. Biol., 5 (2009), 1000353. https://doi.org/10.1371/journal.pcbi.1000353 doi: 10.1371/journal.pcbi.1000353
|
| [10] |
X. Zhang, R. Zhang, Y. Jiang, P. Sun, G. Tang, X. Wang, et al., The expanded human disease network combining protein-protein interaction information, Eur. J. Hum. Genet., 19 (2011), 783–788. https://doi.org/10.1038/ejhg.2011.30 doi: 10.1038/ejhg.2011.30
|
| [11] |
Y. Hu, M. Zhou, H. Shi, H. Ju, Q. Jiang, L. Cheng, Measuring disease similarity and predicting disease-related ncRNAs by a novel method, BMC Med. Genomics, 10 (2017), 67–74. https://doi.org/10.1186/s12920-017-0315-9 doi: 10.1186/s12920-017-0315-9
|
| [12] |
L. M. Schriml, J. B. Munro, M. Schor, D, Olley, C. McCracken, V. Felix, et al., The human disease ontology 2022 update, Nucleic Acids Res., 50 (2022), 1255–1261. https://doi.org/10.1093/nar/gkab1063 doi: 10.1093/nar/gkab1063
|
| [13] |
S. Carbon, E. Douglass, N. Dunn, B. M. Good, N. L. Harris, S. E. Lewis, et al., The gene ontology resource: 20 years and still GOing strong, Nucleic Acids Res., 47 (2019), 330–338. https://doi.org/10.1093/nar/gky1055 doi: 10.1093/nar/gky1055
|
| [14] |
S. Köhler, M. Gargano, N. Matentzoglu, L. C. Carmody, D. Lewis-Smith, N. A Vasilevsky, et al., The human phenotype ontology in 2021, Nucleic Acids Res., 49 (2021), 1207–1217. https://doi.org/10.1093/nar/gkaa1043 doi: 10.1093/nar/gkaa1043
|
| [15] |
O. Bodenreider, The Unified Medical Language System (UMLS): Integrating biomedical terminology, Nucleic Acids Res., 32 (2004), 267–270. https://doi.org/10.1093/nar/gkh061 doi: 10.1093/nar/gkh061
|
| [16] |
D. L. Ngo, N. Yamamoto, V. A. Tran, N. G. Nguyen, D. Phan, F. R. Lumbanraja, et al., Application of word embedding to drug repositioning, J. Biomed. Sci. Eng., 09 (2016), 7–16, http://doi.org/10.4236/jbise.2016.91002 doi: 10.4236/jbise.2016.91002
|
| [17] |
P. T. Lai, W. L. Lu, T. R. Kuo, C. R. Chung, J. C. Han, R. T. H. Tsai, et al., Using a large margin context-aware convolutional neural network to automatically extract disease-disease association from literature: Comparative analytic study, JMIR Med. Inform., 7 (2019), 14502. https://doi.org/10.2196/14502 doi: 10.2196/14502
|
| [18] | R. O'Shea, Gextext: disease network extraction from biomedical literature, preprint, arXiv1911.02562. |
| [19] | M. V. Korff, B. Deffarges, T. Sander, Data mining in MEDLINE for disease-disease associations via second order co-occurrence, in 2015 IEEE Symposium Series on Computational Intelligence, (2015), 314–321, https://doi.org/10.1109/SSCI.2015.54 |
| [20] | A. L. Beam, B. Kompa, A. Schmaltz, I. Fried, G. Weber, N. Palmer, et al., Clinical concept embeddings learned from massive sources of medical data, Pac. Symp. Biocomput., 25 (2018), 295–306. |
| [21] |
A. B. Holmes, A. Hawson, F. Liu, C. Friedman, H. Khiabanian, R. Rabadan, Discovering disease associations by integrating electronic clinical data and medical literature, PLoS One, 6 (2011), 21132. https://doi.org/10.1371/journal.pone.0021132 doi: 10.1371/journal.pone.0021132
|
| [22] | S. Ghosh, P. Chakraborty, E. Cohn, J. S. Brownstein, N. Ramakrishnan, Characterizing diseases from unstructured text: A vocabulary driven Word2vec approach, preprint, arXiv.1603.00106. |
| [23] |
J. Park, K. Kim, W. Hwang, D. Lee, Concept embedding to measure semantic relatedness for biomedical information ontologies, J. Biomed. Inform., 94 (2019), 103182. https://doi.org/10.1016/j.jbi.2019.103182 doi: 10.1016/j.jbi.2019.103182
|
| [24] |
J. Z. Wang, Z. Du, R. Payattakool, P. S. Yu, C. F. Chen, A new method to measure the semantic similarity of GO terms, Bioinformatics, 23 (2007), 1274–1281. https://doi.org/10.1093/bioinformatics/btm087 doi: 10.1093/bioinformatics/btm087
|
| [25] | P. Resnik, Using information content to evaluate semantic similarity in a taxonomy, preprint, arXiv: cmp-lg/9511007. |
| [26] | D. Lin, An information-theoretic definition of similarity, in International Conference on Machine Learning, 98 (1998), 296–304. |
| [27] | S. Mathur, D. Dinakarpandian, Automated ontological gene annotation for computing disease similarity, Summit Transl Bioinform., (2010), 12–16. |
| [28] |
S. Mathur, D. Dinakarpandian, Finding disease similarity based on implicit semantic similarity, J. Biomed. Inform., 45 (2012), 363–371, https://doi.org/10.1016/j.jbi.2011.11.017 doi: 10.1016/j.jbi.2011.11.017
|
| [29] |
F. Z. Smaili, X. Gao, R. Hoehndorf, Onto2Vec: Joint vector-based representation of biological entities and their ontology-based annotations, Bioinformatics, 34 (2018), 52–60, doi: https://doi.org/10.1093/bioinformatics/bty259 doi: 10.1093/bioinformatics/bty259
|
| [30] |
L. Cheng, J. Li, P. Ju, J. Peng, Y. Wang, SemFunSim: A new method for measuring disease similarity by integrating semantic and gene functional association, PLoS One, 9 (2014), 99415. https://doi.org/10.1371/journal.pone.0099415 doi: 10.1371/journal.pone.0099415
|
| [31] |
S. Su, L. Zhang, J. Liu, An effective method to measure disease similarity using gene and phenotype associations, Front. Genet., 10 (2019), 1–8. https://doi.org/10.3389/fgene.2019.00466 doi: 10.3389/fgene.2019.00466
|
| [32] |
S. Jiang, W. Wu, N. Tomita, C. Ganoe, S. Hassanpour, Multi-Ontology Refined Embeddings (MORE): A hybrid multi-ontology and corpus-based semantic representation model for biomedical concepts, J. Biomed. Inform., 111 (2020), 103581. https://doi.org/10.1016/j.jbi.2020.103581 doi: 10.1016/j.jbi.2020.103581
|
| [33] | Z. Yu, B. C. Wallace, T. Johnson, T. Cohen, Retrofitting concept vector representations of medical concepts to improve estimates of semantic similarity and relatedness, preprint, arXiv.1709.07357. |
| [34] |
E. Nourani, V. Reshadat, Association extraction from biomedical literature based on representation and transfer learning, J. Theor. Biol., 488 (2020), 110112. https://doi.org/10.1016/j.jtbi.2019.110112 doi: 10.1016/j.jtbi.2019.110112
|
| [35] | Y. Peng, Z. Lu, Deep learning for extracting protein-protein interactions from biomedical literature, in Proceedings of the BioNLP 2017 workshop, (2017), 29–38. http://doi.org/10.18653/v1/W17-2304 |
| [36] |
C. Quan, L. Hua, X. Sun, W. Bai, Multichannel convolutional neural network for biological relation extraction, Biomed Res. Int., (2016), 1850404. https://doi.org/10.1155/2016/1850404 doi: 10.1155/2016/1850404
|
| [37] |
N. K. Rakhi, R. Tuwani, J. Mukherjee, G. Bagler, Data-driven analysis of biomedical literature suggests broad-spectrum benefits of culinary herbs and spices, PLoS One, 13 (2018), 1–20, doi: https://doi.org/10.1371/journal.pone.0198030 doi: 10.1371/journal.pone.0198030
|
| [38] |
J. Li, X. Zhu, J. Y. Chen, Building disease-specific drug-protein connectivity maps from molecular interaction networks and PubMed abstracts, PLoS Comput. Biol., 5 (2009), 1000450. https://doi.org/10.1371/journal.pcbi.1000450 doi: 10.1371/journal.pcbi.1000450
|
| [39] |
H. W. Chun, Y. Tsuruoka, J. D. Kim, R. Shiba, N. Nagata, T. Hishiki, et al., Extraction of gene-disease relations from medline using domain dictionaries and machine learning, Pac. Symp. Biocomput., 15 (2006), 4–15. https://doi.org/10.1142/9789812701626_0002 doi: 10.1142/9789812701626_0002
|
| [40] |
C. Perez-Iratxeta, P. Bork, M. A. Andrade, Association of genes to genetically inherited diseases using data mining, Nat. Genet., 31 (2002), 316–319. https://doi.org/10.1038/ng895 doi: 10.1038/ng895
|
| [41] |
S. Pletscher-Frankild, A. Pallejà, K. Tsafou, J. X. Binder, L. J. Jensen, DISEASES: Text mining and data integration of disease-gene associations, Methods, 74 (2015), 83–89. https://doi.org/10.1016/j.ymeth.2014.11.020 doi: 10.1016/j.ymeth.2014.11.020
|
| [42] |
J. Lee, S. Kim, S. Lee, K. Lee, J. Kang, On the efficacy of per-relation basis performance evaluation for PPI extraction and a high-precision rule-based approach, BMC Med. Inform. Decis. Mak., 13 (2013), 1–12. https://doi.org/10.1186/1472-6947-13-S1-S7 doi: 10.1186/1472-6947-13-S1-S7
|
| [43] |
M. Song, W. C. Kim, D. Lee, G. E. Heo, K. Y. Kang, PKDE4J: Entity and relation extraction for public knowledge discovery, J. Biomed. Inform., 57 (2015), 320–332. https://doi.org/10.1016/j.jbi.2015.08.008 doi: 10.1016/j.jbi.2015.08.008
|
| [44] |
L. Tari, J. Hakenberg, G. Gonzalez, C. Baral, Querying parse tree database of medline text to synthesize user-specific biomolecular networks, Pac. Symp. Biocomput., 98 (2009), 87–98. https://doi.org/10.1142/9789812836939_0009 doi: 10.1142/9789812836939_0009
|
| [45] |
B. Bhasuran, J. Natarajan, Automatic extraction of gene-disease associations from literature using joint ensemble learning, PLoS One, 13 (2018), 1–22. https://doi.org/10.1371/journal.pone.0200699 doi: 10.1371/journal.pone.0200699
|
| [46] |
Y. Zhang, Z. Lu, Exploring semi-supervised variational autoencoders for biomedical relation extraction, Methods, 166 (2019), 112–119. https://doi.org/10.1016/j.ymeth.2019.02.021 doi: 10.1016/j.ymeth.2019.02.021
|
| [47] |
N. Rosário-Ferreira, V. Guimarães, V. S. Costa, I. S. Moreira, SicknessMiner: a deep-learning-driven text-mining tool to abridge disease-disease associations, BMC Bioinformatics, 22 (2021), 1–12. https://doi.org/10.1186/s12859-021-04397-w doi: 10.1186/s12859-021-04397-w
|
| [48] | M. Asada, M. Miwa, Y. Sasaki, Extracting drug-drug interactions with attention CNNs, in Proceedings of the BioNLP 2017 workshop, (2017), 9–18. http://doi.org/10.18653/v1/W17-2302 |
| [49] | Y. Hsieh, Y. Chang, N. Chang, W. Hsu, Identifying rotein-protein interactions in biomedical literature using recurrent neural networks with long short-term memory, in Proceedings of the The 8th International Joint Conference on Natural Language Processing, (2017), 240–245. |
| [50] |
L. Hua, C. Quan, A shortest dependency path based convolutional neural network for protein-protein relation extraction, Biomed Res. Int., (2016), 8479587. https://doi.org/10.1155/2016/8479587 doi: 10.1155/2016/8479587
|
| [51] | X. Wang, L. Zhu, Z. Zheng, M. Xu, Y. Yang, Align and tell: Boosting text-video retrieval with local alignment and fine-grained supervision, IEEE Trans. Multimedia, (2022), 1–11. https://doi.org/10.1109/TMM.2022.3204444 |
| [52] | R. Xu, L. Li, Q. Q. Wang, DRiskKB: A large-scale disease-disease risk relationship knowledge base constructed from biomedical text, BMC Bioinformatics, 15 (2014) 105. https://doi.org/10.1186/1471-2105-15-105 |
| [53] |
D. Wei, T. Kang, H. A. Pincus, C. Weng, Construction of disease similarity networks using concept embedding and ontology, Stud. Health Technol. Inform., 264 (2019), 442–446. https://doi.org/10.3233/shti190260 doi: 10.3233/shti190260
|
| [54] |
S. V. S. Pakhomov, G. Finley, R. McEwan, Y. Wang, G. B. Melton, Corpus domain effects on distributional semantic modeling of medical terms, Bioinformatics, 32 (2016), 3635–3644. https://doi.org/10.1093/bioinformatics/btw529 doi: 10.1093/bioinformatics/btw529
|
| [55] | G. K. Mazandu, N. J. Mulder, Information content-based gene ontology semantic similarity approaches: Toward a unified framework theory, Biomed Res. Int., (2013). https://doi.org/10.1155/2013/292063 |
| [56] |
X. Song, L. Li, P. K. Srimani, P. S. Yu, J. Z. Wang, Measure the semantic similarity of go terms using aggregate information content, IEEE/ACM Trans. Comput. Biol. Bioinform., 11 (2014), 468–476. https://doi.org/10.1109/tcbb.2013.176 doi: 10.1109/tcbb.2013.176
|
| [57] |
Z. Teng, M. Guo, X. Liu, Q. Dai, C. Wang, P. Xuan, Measuring gene functional similarity based on group-wise comparison of GO terms, Bioinformatics, 29 (2013), 1424–1432. https://doi.org/10.1093/bioinformatics/btt160 doi: 10.1093/bioinformatics/btt160
|
| [58] |
C. Zhao, Z. Wang, GOGO: An improved algorithm to measure the semantic similarity between gene ontology terms, Sci. Rep., 8 (2018), 1–10. https://doi.org/10.1038/s41598-018-33219-y doi: 10.1038/s41598-018-33219-y
|
| [59] | Z. Wu, M. Palmer, Verb semantics and lexical selection, in Proceedings of the 32nd annual meeting on Association for Computational Linguistics, (1994), 133–138. https://doi.org/10.3115/981732.981751 |
| [60] | R. Richardson, A. Smeaton, J. Murphy, Using WordNet as a knowledge base for measuring semantic similarity between words, Tech. Rep. Work. Pap. 9 (1994). |
| [61] |
J. Cheng, M. S. Cline, J. Martin, D. Finkelstein, T. Awad, D. Kulp, et al., A knowledge-based clustering algorithm driven by Gene Ontology, J. Biopharm. Stat., 14 (2004), 687–700. https://doi.org/10.1081/bip-200025659 doi: 10.1081/bip-200025659
|
| [62] |
H. Wu, Z. Su, F. Mao, V. Olman, Y. Xu, Prediction of functional modules based on comparative genome analysis and Gene Ontology application, Nucleic Acids Res., 33 (2005), 2822–2837. https://doi.org/10.1093/nar/gki573 doi: 10.1093/nar/gki573
|
| [63] |
D. Wang, J. Wang, M. Lu, F. Song, Q. Cui, Inferring the human microRNA functional similarity and functional network based on microRNA-associated diseases, Bioinformatics, 26 (2010), 1644–1650. https://doi.org/10.1093/bioinformatics/btq241 doi: 10.1093/bioinformatics/btq241
|
| [64] |
G. K. Mazandu, N. J. Mulder, A topology-based metric for measuring term similarity in the gene ontology, Adv. Bioinformatics, (2012), 975783. https://doi.org/10.1155/2012/975783 doi: 10.1155/2012/975783
|
| [65] |
A. B. Kamran, H. Naveed, GOntoSim: A semantic similarity measure based on LCA and common descendants, Sci. Rep., 12 (2022), 3818. https://doi.org/10.1038/s41598-022-07624-3 doi: 10.1038/s41598-022-07624-3
|
| [66] |
J. Camacho-Collados, M. T. Pilehvar, R. Navigli, NASARI: Integrating explicit knowledge and corpus statistics for a multilingual representation of concepts and entities, Artif. Intell., 240 (2016), 36–64. https://doi.org/10.1016/j.artint.2016.07.005 doi: 10.1016/j.artint.2016.07.005
|
| [67] |
Z. H. Guo, Z. H. You, D. S. Huang, H. C. Yi, K. Zheng, Z. H. Chen, et al., MeSHHeading2vec: A new method for representing MeSH headings as vectors based on graph embedding algorithm, Brief. Bioinform., 22 (2021), 2085–2095. https://doi.org/10.1093/bib/bbaa037 doi: 10.1093/bib/bbaa037
|
| [68] |
X. Zhong, R. Kaalia, J. C. Rajapakse, GO2Vec: Transforming GO terms and proteins to vector representations via graph embeddings, BMC Genomics, 20 (2019), 918. https://doi.org/10.1186/s12864-019-6272-2 doi: 10.1186/s12864-019-6272-2
|
| [69] |
F. Z. Smaili, X. Gao, R. Hoehndorf, OPA2Vec: Combining formal and informal content of biomedical ontologies to improve similarity-based prediction, Bioinformatics, 35 (2019), 2133–2140. https://doi.org/10.1093/bioinformatics/bty933 doi: 10.1093/bioinformatics/bty933
|
| [70] |
J. Lee, D. Lee, K. H. Lee, Literature mining for context-specific molecular relations using multimodal representations (COMMODAR), BMC Bioinformatics, 21 (2020), 250. https://doi.org/10.1186/s12859-020-3396-y doi: 10.1186/s12859-020-3396-y
|
| [71] |
L. Deng, D. Ye, J. Zhao, J. Zhang, MultiSourcDSim: An integrated approach for exploring disease similarity, BMC Med. Inform. Decis. Mak., 19 (2019), 269. https://doi.org/10.1186/s12911-019-0968-8 doi: 10.1186/s12911-019-0968-8
|
| [72] |
P. Li, Y. Nie, J. Yu, Fusing literature and full network data improves disease similarity computation, BMC Bioinformatics, 17 (2016), 326. https://doi.org/10.1186/s12859-016-1205-4 doi: 10.1186/s12859-016-1205-4
|
| [73] |
C. H. Wei, A. Allot, R. Leaman, Z. Lu, PubTator central: automated concept annotation for biomedical full text articles, Nucleic Acids Res., 47 (2019), 587–593. https://doi.org/10.1093/nar/gkz389 doi: 10.1093/nar/gkz389
|
| [74] |
J. Piñero, J. M. R. Anguita, J. S. Pitarch, F. Ronzano, E. Centeno, F. Sanz, et al., The DisGeNET knowledge platform for disease genomics: 2019 update, Nucleic Acids Res., 48 (2020), 845–855. https://doi.org/10.1093/nar/gkz1021 doi: 10.1093/nar/gkz1021
|
| [75] |
L. E. Salnikova, E. V. Chernyshova, L. A. Anastasevich, S. S. Larin, Gene-and disease-based expansion of the knowledge on inborn errors of immunity, Front. Immunol., 10 (2019), 2475. https://doi.org/10.3389/fimmu.2019.02475 doi: 10.3389/fimmu.2019.02475
|
| [76] |
T. Pedersen, S. V. S. Pakhomov, S. Patwardhan, C. G. Chute, Measures of semantic similarity and relatedness in the biomedical domain, J. Biomed. Inform., 40 (2007), 288–299. https://doi.org/10.1016/j.jbi.2006.06.004 doi: 10.1016/j.jbi.2006.06.004
|
| [77] |
A. P. Davis, C. J. Grondin, R. J. Johnson, D. Sciaky, J. Wiegers, T. C. Wiegers, et al., Comparative Toxicogenomics Database (CTD): Update 2021, Nucleic Acids Res., 49 (2021), 1138–1143. https://doi.org/10.1093/nar/gkaa891 doi: 10.1093/nar/gkaa891
|
| [78] | S. Manchanda, A. Anand, Representation learning of drug and disease terms for drug repositioning, in 2017 3rd IEEE International Conference on Cybernetics (CYBCON), (2017), 1–6. https://doi.org/10.1109/CYBConf.2017.7985802 |
| [79] |
J. J. Lastra-Díaz, J. Goikoetxea, M. A. Hadj Taieb, A. García-Serrano, M. Ben Aouicha, E. Agirre, A reproducible survey on word embeddings and ontology-based methods for word similarity: Linear combinations outperform the state of the art, Eng. Appl. Artif. Intell., 85 (2019), 645–665. https://doi.org/10.1016/j.engappai.2019.07.010 doi: 10.1016/j.engappai.2019.07.010
|
| [80] | M. de Marneffe, C. D. Manning, Stanford typed dependencies manual, 2008. Available from: https://downloads.cs.stanford.edu/nlp/software/dependencies_manual.pdf |
| [81] | Y. Tsuruoka, J. Tsujii, Bidirectional inference with the easiest-first strategy for tagging sequence data, Proceedings of Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing (HLT/EMNLP), (2005), 467–474. http://doi.org/10.3115/1220575.1220634 |
| [82] | T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, Distributed representations of words and phrases and their compositionality, in Proceedings of the 26th International Conference on Neural Information Processing Systems, 2 (2013), 3111–3119. |
| [83] | S. Pyysalo, F. Ginter, H. Moen, T. Salakoski, S. Ananiadou, Distributional semantics resources for biomedical text processing, Proceedings of the 5th International Symposium on Languages in Biology and Medicine, 5 (2013), 39–44. |
| [84] | Y. Tang, Deep Learning using Linear Support Vector Machines, preprint, arXiv: 1306.0239. |
| [85] | E. Choi, M. T. Bahadori, L. Song, W. F. Stewart, J. Sun, GRAM: Graph-based attention model for healthcare representation learning, in Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, (2017), 787–795. https://doi.org/10.1145%2F3097983.3098126 |
| [86] | L. Song, C. W. Cheong, K. Yin, W. K. Cheung, B. C. M. Fung, J. Poon, Medical concept embedding with multiple ontological representations, in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, (2019), 4613–4619. https://doi.org/10.24963/ijcai.2019/641 |
| [87] | Q. Le, T. Mikolov, Distributed representations of sentences and documents, preprint, arXiv: 1405.4053 |
| [88] |
A. Schlicker, F. S. Domingues, J. Rahnenführer, T. Lengauer, A new measure for functional similarity of gene products based on gene ontology, BMC Bioinformatics, 7 (2006), 302. https://doi.org/10.1186/1471-2105-7-302 doi: 10.1186/1471-2105-7-302
|
| [89] | M. Miwa, M. Bansal, End-to-end relation extraction using LSTMs on sequences and tree structures, in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 1 (2016), 1105–1116. http://doi.org/10.18653/v1/P16-1105 |
| [90] | D. Zeng, K. Liu, S. Lai, G. Zhou, J. Zhao, Relation classification via convolutional deep neural network, in Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, (2014), 2335–2344. |
| [91] |
J. Devlin, M. W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 1 (2019), 4171–4186. http://doi.org/10.18653/v1/N19-1423 doi: 10.18653/v1/N19-1423
|
| [92] |
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, et al., BioBERT: A pre-trained biomedical language representation model for biomedical text mining, Bioinformatics, 36 (2020), 1234–1240. https://doi.org/10.1093/bioinformatics/btz682 doi: 10.1093/bioinformatics/btz682
|
| [93] | J. Pennington, R. Socher, C. D. Manning, Glove: Global vectors for word representation, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), (2014), 1532–1543. http://doi.org/10.3115/v1/D14-1162 |








Figures(9) / Tables(17)

Karpaga Priyaa Kartheeswaran, Arockia Xavier Annie Rayan, Geetha Thekkumpurath Varrieth. Enhanced disease-disease association with information enriched disease representation[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 8892-8932. doi: 10.3934/mbe.2023391







 DownLoad:
DownLoad: