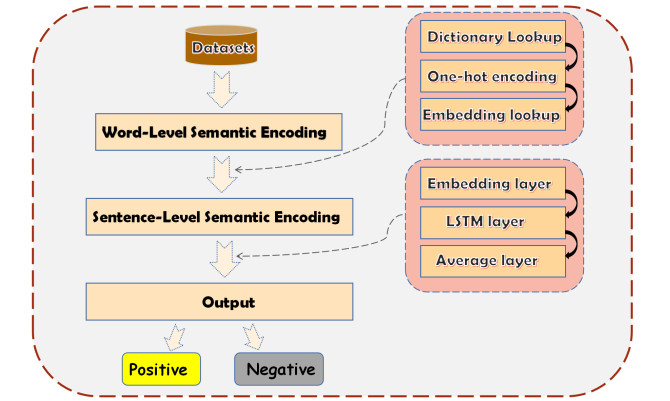
As the college students have been a most active user group in various social media, it remains significant to make effective sentiment analysis for college public opinions. Capturing the direction of public opinion in the student community in a timely manner and guiding students to develop the right values can help in the ideological management of universities. Universally, the recurrent neural networks have been the mainstream technology in terms of sentiment analysis. Nevertheless, the existing research works more emphasized semantic characteristics in vertical direction, yet failing to capture sematic characteristics in horizonal direction. In other words, it is supposed to increase more balance into sentiment analysis models. To remedy such gap, this paper presents a novel sentiment analysis method based on multi-scale deep learning for college public opinions. To fit for bidirectional semantic characteristics, a typical sequential neural network with two propagation paths is selected as the backbone. It is then extended with more layers in horizonal direction. Such design is able to balance both model depth and model breadth. At last, some experiments on a real-world social media dataset are conducted for evaluation, well acknowledging efficiency of the proposed analysis model.
Citation: Qiao Xiang, Tianhong Huang, Qin Zhang, Yufeng Li, Amr Tolba, Isack Bulugu. A novel sentiment analysis method based on multi-scale deep learning[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 8766-8781. doi: 10.3934/mbe.2023385
As the college students have been a most active user group in various social media, it remains significant to make effective sentiment analysis for college public opinions. Capturing the direction of public opinion in the student community in a timely manner and guiding students to develop the right values can help in the ideological management of universities. Universally, the recurrent neural networks have been the mainstream technology in terms of sentiment analysis. Nevertheless, the existing research works more emphasized semantic characteristics in vertical direction, yet failing to capture sematic characteristics in horizonal direction. In other words, it is supposed to increase more balance into sentiment analysis models. To remedy such gap, this paper presents a novel sentiment analysis method based on multi-scale deep learning for college public opinions. To fit for bidirectional semantic characteristics, a typical sequential neural network with two propagation paths is selected as the backbone. It is then extended with more layers in horizonal direction. Such design is able to balance both model depth and model breadth. At last, some experiments on a real-world social media dataset are conducted for evaluation, well acknowledging efficiency of the proposed analysis model.

| [1] |
E. K. W. Leow, B. P. Nguyen, M. C. H. Chua, Robo-advisor using genetic algorithm and BERT sentiments from tweets for hybrid portfolio optimisation, Expert Syst. Appl., 179 (2021), 115060. https://doi.org/10.1016/j.eswa.2021.115060 doi: 10.1016/j.eswa.2021.115060

|
| [2] |
Z. Guo, K. Yu, A. Jolfaei, F. Ding, N. Zhang, Fuz-spam: Label smoothing-based fuzzy detection of spammers in internet of things, IEEE Trans. Fuzzy Syst., 30 (2022), 4543–4554. https://doi.org/10.1109/TFUZZ.2021.3130311 doi: 10.1109/TFUZZ.2021.3130311
|
| [3] | L. Zhao, Z. Bi, A. Hawbani, K. Yu, Y. Zhang, M. Guizani, Elite: An intelligent digital twin-based hierarchical routing scheme for softwarized vehicular networks, IEEE Trans. Mob. Comput., 2022. https://doi.org/10.1109/TMC.2022.3179254 |
| [4] | F. Ding, B. Fan, Z. Shen, K. Yu, G. Srivastava, K. Dev, et al., Securing facial bioinformation by eliminating adversarial perturbations, IEEE Trans. Ind. Inf., 2022. https://doi.org/10.1109/TII.2022.3201572 |
| [5] |
M. Dragoni, I. Donadello, E. Cambria, Ontosenticnet 2: Enhancing reasoning within sentiment analysis, IEEE Intell. Syst., 37 (2022), 103–110. https://doi.org/10.1109/MIS.2021.3093659 doi: 10.1109/MIS.2021.3093659
|
| [6] | S. Zhang, H. Gu, K. Chi, L. Huang, K. Yu, S. Mumtaz, Drl-based partial offloading for maximizing sum computation rate of wireless powered mobile edge computing network, IEEE Trans. Wireless Commun., 2022. https://doi.org/10.1109/TWC.2022.3188302 |
| [7] |
Z. Cai, Z. He, X. Guan, Y. Li, Collective data-sanitization for preventing sensitive information inference attacks in social networks, IEEE Trans. Dependable Secure Comput., 15 (2018), 577–590. https://doi.org/10.1109/TDSC.2016.2613521 doi: 10.1109/TDSC.2016.2613521
|
| [8] | F. Ding, Z. Shen, G. Zhu, S. Kwong, Y. Zhou, S. Lyu, Exs-gan: Synthesizing anti-forensics images via extra supervised gan, IEEE Trans. Cybern., 2022. https://doi.org/10.1109/TCYB.2022.3210294 |
| [9] |
L. Malandri, C. Porcel, F. Xing, J. Serrano-Guerrero, E. Cambria, Soft computing for recommender systems and sentiment analysis, Appl. Soft Comput., 118 (2022), 108246. https://doi.org/10.1016/j.asoc.2021.108246 doi: 10.1016/j.asoc.2021.108246
|
| [10] |
Y. Li, H. Ma, L. Wang, S. Mao, G. Wang, Optimized content caching and user association for edge computing in densely deployed heterogeneous networks, IEEE Trans. Mob. Comput., 21 (2022), 2130–2142. https://doi.org/10.1109/TMC.2020.3033563 doi: 10.1109/TMC.2020.3033563
|
| [11] |
F. Ding, Y. Shi, G. Zhu, Y. Q. Shi, Real-time estimation for the parameters of gaussian filtering via deep learning, J. Real-Time Image Process., 17 (2020), 17–27. https://doi.org/10.1007/s11554-019-00907-5 doi: 10.1007/s11554-019-00907-5
|
| [12] | Y. Zhu, W. X. Zheng, Observer-based control for cyber-physical systems with periodic dosattacks via a cyclic switching strategy, IEEE Trans. Autom. Control, 65 (2019), 3714–3721. |
| [13] |
X. Zheng, Z. Cai, Privacy-preserved data sharing towards multiple parties in industrial iots, IEEE J. Sel. Areas Commun., 38 (2020), 968–979. https://doi.org/10.1109/JSAC.2020.2980802 doi: 10.1109/JSAC.2020.2980802
|
| [14] | L. Chen, Y. Zhu, C. K. Ahn, Adaptive neural network-based observer design for switched systems with quantized measurements, IEEE Trans. Neural Networks Learn. Syst., 2021. |
| [15] |
M. Qorib, T. Oladunni, M. Denis, E. Ososanya, P. Cotae, Covid-19 vaccine hesitancy: Text mining, sentiment analysis and machine learning on COVID-19 vaccination twitter dataset, Expert Syst. Appl., 212 (2023), 118715. https://doi.org/10.1016/j.eswa.2022.118715 doi: 10.1016/j.eswa.2022.118715
|
| [16] |
F. Ding, Y. Shi, G. Zhu, Y. Q. Shi, Smoothing identification for digital image forensics, Multimedia Tools Appl., 78 (2019), 8225–8245. https://doi.org/10.1007/s11042-018-6807-6 doi: 10.1007/s11042-018-6807-6
|
| [17] | S. Liu, S. Huang, S. Wang, K. Muhammad, P. Bellavista, J. D. Ser, Visual tracking in complex scenes: A location fusion mechanism based on the combination of multiple visual cognition flows, Inf. Fusion, 2023. https://doi.org/10.1016/j.inffus.2023.02.005 |
| [18] |
A. Keramatfar, H. Amirkhani, A. J. Bidgoly, Modeling tweet dependencies with graph convolutional networks for sentiment analysis, Cogn. Comput., 14 (2022), 2234–224. https://doi.org/10.1007/s12559-021-09986-8 doi: 10.1007/s12559-021-09986-8
|
| [19] |
Q. Zhang, K. Yu, Z. Guo, S. Garg, J. J. P. C. Rodrigues, M. M. Hassan, et al., Graph neural network-driven traffic forecasting for the connected internet of vehicles, IEEE Trans. Netw. Sci. Eng., 9 (2022), 3015–302. https://doi.org/10.1109/TNSE.2021.3126830 doi: 10.1109/TNSE.2021.3126830
|
| [20] |
Z. Guo, K. Yu, A. K. Bashir, D. Zhang, Y. D. Al-Otaibi, M. Guizani, Deep information fusion-driven poi scheduling for mobile social networks, IEEE Network, 36 (2022), 210–216. https://doi.org/10.1109/MNET.102.2100394 doi: 10.1109/MNET.102.2100394
|
| [21] |
S. Liu, Y. Li, W. Fu, Human-centered attention-aware networks for action recognition, Int. J. Intell. Syst., 37 (2022), 10968–10987. https://doi.org/10.1002/int.23029 doi: 10.1002/int.23029
|
| [22] |
S. Liu, P. Gao, Y. Li, W. Fu, W. Ding, Multi-modal fusion network with complementarity and importance for emotion recognition, Inf. Sci., 619 (2023), 679–694. https://doi.org/10.1016/j.ins.2022.11.076 doi: 10.1016/j.ins.2022.11.076
|
| [23] | Z. Guo, K. Yu, A. Jolfaei, G. Li, F. Ding, A. Beheshti, Mixed graph neural network-based fake news detection for sustainable vehicular social networks, IEEE Trans. Intell. Transp. Syst., 2022. https://doi.org/10.1109/TITS.2022.3185013 |
| [24] |
D. Peng, D. He, Y. Li, Z. Wang, Integrating terrestrial and satellite multibeam systems toward 6g: Techniques and challenges for interference mitigation, IEEE Wireless Commun., 29 (2022), 24–31. https://doi.org/10.1109/MWC.002.00293 doi: 10.1109/MWC.002.00293
|
| [25] |
Z. Guo, K. Yu, Z. Lv, K. K. R. Choo, P. Shi, J. J. P. C. Rodrigues, Deep federated learning enhanced secure poi microservices for cyber-physical systems, IEEE Wireless Commun., 29 (2022), 22–29. https://doi.org/10.1109/MWC.002.2100272 doi: 10.1109/MWC.002.2100272
|
| [26] |
B. P. Nguyen, W. L. Tay, C. K. Chui, Robust biometric recognition from palm depth images for gloved hands, IEEE Trans. Hum.-Mach. Syst., 45 (2015), 799–804. https://doi.org/10.1109/THMS.2015.2453203 doi: 10.1109/THMS.2015.2453203
|
| [27] | A. X. Wang, S. S. Chukova, B. P. Nguyen, Implementation and analysis of centroid displacement-based k-nearest neighbors, in Advanced Data Mining and Applications: 18th International Conference, (2022), 431–443. https://doi.org/10.1007/978-3-031-22064-7_31 |
| [28] | A. X. Wang, S. S. Chukova, B. P. Nguyen, Ensemble k-nearest neighbors based on centroid displacement, Inf. Sci., 2023. |
| [29] | K. B. Rashmi, H. S. Guruprasad, B. R. Shambhavi, Sentiment classification on bilingual code-mixed texts for dravidian languages using machine learning methods, in Working Notes of FIRE 2021–Forum for Information Retrieval Evaluation, (2021), 899–907. http://ceur-ws.org/Vol-3159/T6-3.pdf |
| [30] |
R. Maipradit, H. Hata, K. Matsumoto, Sentiment classification using n-gram inverse document frequency and automated machine learning, IEEE Softw., 36 (2019), 65–70. https://doi.org/10.1109/MS.2019.2919573 doi: 10.1109/MS.2019.2919573
|
| [31] |
Y. Li, N. Li, Sentiment analysis of weibo comments based on graph neural network, IEEE Access, 10 (2022), 23497–23510. https://doi.org/10.1109/ACCESS.2022.3154107 doi: 10.1109/ACCESS.2022.3154107
|
| [32] |
S. O. Alhumoud, A. A. A. Wazrah, Arabic sentiment analysis using recurrent neural networks: A review, Artif. Intell. Rev., 55 (2022), 707–748. https://doi.org/10.1007/s10462-021-09989-9 doi: 10.1007/s10462-021-09989-9
|
| [33] |
Z. Jin, M. Tao, X. Zhao, Y. Hu, Social media sentiment analysis based on dependency graph and co-occurrence graph, Cogn. Comput., 14 (2022), 1039–1054. https://doi.org/10.1007/s12559-022-10004-8 doi: 10.1007/s12559-022-10004-8
|
| [34] |
J. He, H. Hu, Language reinforced superposition multimodal fusion for sentiment analysis, IEEE Signal Process. Lett., 29 (2022), 1347–1351. https://doi.org/10.1109/LSP.2022.3180668 doi: 10.1109/LSP.2022.3180668
|
| [35] | C. Q. Huang, F. Jiang, Q. H. Huang, X. Z. Wang, Z. M. Han, W. Y. Huang, Dual-graph attention convolution network for 3-d point cloud classification, IEEE Trans. Neural Networks Learn. Syst., 2022. |
| [36] | Z. Lin, H. Wang, S. Li, Pavement anomaly detection based on transformer and self-supervised learning, Autom. Constr., 143 (2022), 104544. |
| [37] | C. Huang, Z. Han, M. Li, X. Wang, W. Zhao, Sentiment evolution with interaction levels in blended learning environments: Using learning analytics and epistemic network analysis, Australas. J. Educ. Technol., 37 (2021), 81–95. |
| [38] |
K. Jia, Sentiment classification of microblog: A framework based on BERT and CNN with attention mechanism, Comput. Electr. Eng., 101 (2022), 108032. https://doi.org/10.1016/j.compeleceng.2022.108032 doi: 10.1016/j.compeleceng.2022.108032
|
| [39] |
V. Harendranath, S. Rodda, Penguin rider optimization algorithm-based deep recurrent neural network for sentiment classification of political twitter data, Int. J. Web Serv. Res., 19 (2022), 1–25. https://doi.org/10.4018/IJWSR.299019 doi: 10.4018/IJWSR.299019
|
| [40] | A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng, C. Potts, Learning word vectors for sentiment analysis, in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, (2011), 142–150. |
| [41] |
R. Das, T. D. Singh, A multi-stage multimodal framework for sentiment analysis of assamese in low resource setting, Expert Syst. Appl., 204 (2022), 117575. https://doi.org/10.1016/j.eswa.2022.117575 doi: 10.1016/j.eswa.2022.117575
|






Figures(7) / Tables(2)

Qiao Xiang, Tianhong Huang, Qin Zhang, Yufeng Li, Amr Tolba, Isack Bulugu. A novel sentiment analysis method based on multi-scale deep learning[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 8766-8781. doi: 10.3934/mbe.2023385







 DownLoad:
DownLoad: