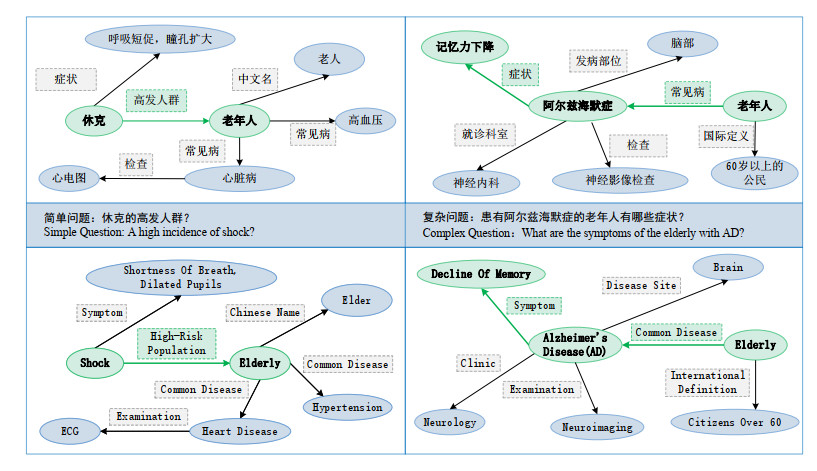
Chinese medical knowledge-based question answering (cMed-KBQA) is a vital component of the intelligence question-answering assignment. Its purpose is to enable the model to comprehend questions and then deduce the proper answer from the knowledge base. Previous methods solely considered how questions and knowledge base paths were represented, disregarding their significance. Due to entity and path sparsity, the performance of question and answer cannot be effectively enhanced. To address this challenge, this paper presents a structured methodology for the cMed-KBQA based on the cognitive science dual systems theory by synchronizing an observation stage (System 1) and an expressive reasoning stage (System 2). System 1 learns the question's representation and queries the associated simple path. Then System 2 retrieves complicated paths for the question from the knowledge base by using the simple path provided by System 1. Specifically, System 1 is implemented by the entity extraction module, entity linking module, simple path retrieval module, and simple path-matching model. Meanwhile, System 2 is performed by using the complex path retrieval module and complex path-matching model. The public CKBQA2019 and CKBQA2020 datasets were extensively studied to evaluate the suggested technique. Using the metric average F1-score, our model achieved 78.12% on CKBQA2019 and 86.60% on CKBQA2020.
Citation: Meiling Wang, Xiaohai He, Zhao Zhang, Luping Liu, Linbo Qing, Yan Liu. Dual-process system based on mixed semantic fusion for Chinese medical knowledge-based question answering[J]. Mathematical Biosciences and Engineering, 2023, 20(3): 4912-4939. doi: 10.3934/mbe.2023228
Chinese medical knowledge-based question answering (cMed-KBQA) is a vital component of the intelligence question-answering assignment. Its purpose is to enable the model to comprehend questions and then deduce the proper answer from the knowledge base. Previous methods solely considered how questions and knowledge base paths were represented, disregarding their significance. Due to entity and path sparsity, the performance of question and answer cannot be effectively enhanced. To address this challenge, this paper presents a structured methodology for the cMed-KBQA based on the cognitive science dual systems theory by synchronizing an observation stage (System 1) and an expressive reasoning stage (System 2). System 1 learns the question's representation and queries the associated simple path. Then System 2 retrieves complicated paths for the question from the knowledge base by using the simple path provided by System 1. Specifically, System 1 is implemented by the entity extraction module, entity linking module, simple path retrieval module, and simple path-matching model. Meanwhile, System 2 is performed by using the complex path retrieval module and complex path-matching model. The public CKBQA2019 and CKBQA2020 datasets were extensively studied to evaluate the suggested technique. Using the metric average F1-score, our model achieved 78.12% on CKBQA2019 and 86.60% on CKBQA2020.

| [1] | K. Bollacker, R. Cook, P. Tufts, Freebase: a shared database of structured general human knowledge, in Proceedings of the 22nd national conference on Artificial intelligence, 2 (2007), 1962–1963. |
| [2] |
C. Bizer, J. Lehmann, G. Kobilarov, S. Auer, C. Becker, R. Cyganiak, et al., Dbpedia-A crystallization point for the web of data, J. Web Semant., 7 (2009), 154–165. https://doi.org/10.1016/j.websem.2009.07.002 doi: 10.1016/j.websem.2009.07.002

|
| [3] |
V. Denny, M. Krötzsch, Wikidata: a free collaborative knowledgebase, Commun. ACM, 57 (2014), 78–85. https://doi.org/10.1145/2629489 doi: 10.1145/2629489
|
| [4] | X. Niu, X. Sun, H. Wang, S. Rong, G. Qi, Y. Yu, Zhishi: me-weaving Chinese linking open data, in International Semantic Web Conference, Springer, Berlin, Heidelberg, (2011), 205–220. https://doi.org/10.1007/978-3-642-25093-4_14 |
| [5] | B. Xu, Y. Xu, J. Liang, C. Xie, B. Liang, W. Cui, et al., CN-DBpedia: A never-ending Chinese knowledge extraction system, in International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Springer, Cham, (2017), 428–438. |
| [6] | Q. Cai, A. Yates, Large-scale semantic parsing via schema matching and lexicon extension, in Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, 1 (2013), 423–433. |
| [7] | J. Berant, A. Chou, R. Frostig, P. Liang, Semantic parsing on freebase from question-answer pairs, in Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, (2013), 1533–1544. |
| [8] |
S. Reddy, M. Lapata, M. Steedman, Large-scale semantic parsing without question-answer pairs, Trans. Assoc. Comput. Ling., 2 (2014), 377–392. https://doi.org/10.1162/tacl_a_00190 doi: 10.1162/tacl_a_00190
|
| [9] | W. Yih, M. Chang, X. He, J. Gao, Semantic parsing via staged query graph generation: Question answering with knowledge base, in Proceedings of the Joint Conference of the 53rd Annual Meeting of the ACL and the 7th International Joint Conference on Natural Language Processing of the AFNLP, (2015), 1–11. |
| [10] |
S. Reddy, O. Täckström, M. Collins, T. Kwiatkowski, D. Das, M. Steedman, et al., Transforming dependency structures to logical forms for semantic parsing, Trans. Assoc. Comput. Ling., 4 (2016), 127–140. https://doi.org/10.1162/tacl_a_00088 doi: 10.1162/tacl_a_00088
|
| [11] | E. Hoffer, N. Ailon, Deep metric learning using triplet network, International Workshop on Similarity-based Pattern Recognition, (2015), 84–92. |
| [12] | N. Francis, A. Green, P. Guagliardo, L. Libkin, T. Lindaaker, V. Marsault, et al., Cypher: An evolving query language for property graphs, in Proceedings of the 2018 International Conference on Management of Data, (2018), 1433–1445. https://doi.org/10.1145/3183713.3190657 |
| [13] | X. Yao, B. Durme, Information extraction over structured data: Question answering with freebase, in Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, 1 (2014), 956–966. |
| [14] | M. Petrochuk, L. Zettlemoyer, Simplequestions nearly solved: A new upperbound and baseline approach, preprint, arXiv: 1804.08798. https://doi.org/10.48550/arXiv.1804.08798 |
| [15] | T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, preprint, arXiv: 1301.3781. https://doi.org/10.48550/arXiv.1301.3781 |
| [16] | J. Pennington, R. Socher, C. D. Manning, Glove: Global vectors for word representation, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, (2014), 1532–1543. |
| [17] | J. Devlin, M. W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, (2019), 4171–4186. |
| [18] | Z. Yang, Z. Dai, Y. Yang, J. Carbonell, R. Salakhutdinov, Q. Le, XLNet: generalized autoregressive pretraining for language understanding, in Proceedings of the 33rd International Conference on Neural Information Processing Systems, (2019), 5753–5763. |
| [19] | A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever, Language models are unsupervised multitask learners, OpenAI blog, 1 (2019), 9–24. |
| [20] |
L. Li, Y. Zhai, J. Gao, L. Wang, L. Hou, J. Zhao, Stacking-BERT model for Chinese medical procedure entity normalization, Math. Biosci. Eng., 20 (2023), 1018–1036. https://doi.org/10.3934/mbe.2023047 doi: 10.3934/mbe.2023047
|
| [21] |
C. Li, K. Ma, Entity recognition of Chinese medical text based on multi-head self-attention combined with BILSTM-CRF, Math. Biosci. Eng., 19 (2022), 2206–2218. https://doi.org/10.3934/mbe.2022103 doi: 10.3934/mbe.2022103
|
| [22] |
S. A. Sloman, The empirical case for two systems of reasoning, Psychol. Bull., 119 (1996), 3–22. https://doi.org/10.1037/0033-2909.119.1.3 doi: 10.1037/0033-2909.119.1.3
|
| [23] |
J. St. B. T. Evans, In two minds: dual-process accounts of reasoning, Trends Cognit. Sci., 7 (2003), 454–459. https://doi.org/10.1016/j.tics.2003.08.012 doi: 10.1016/j.tics.2003.08.012
|
| [24] |
J. St. B. T. Evans, Dual-processing accounts of reasoning, judgment, and social cognition, Annu. Rev. Psychol., 59 (2008), 255–278. https://doi.org/10.1146/annurev.psych.59.103006.093629 doi: 10.1146/annurev.psych.59.103006.093629
|
| [25] | B. Alan, Working memory, Science, 255 (1992), 556–559. https://doi.org/10.1126/science.1736359 |
| [26] |
R. M. Terol, P. M. Barco, M. Palomar, A knowledge based method for the medical question answering problem, Comput. Biol. Med., 37 (2007), 1511–1521. https://doi.org/10.1016/j.compbiomed.2007.01.013 doi: 10.1016/j.compbiomed.2007.01.013
|
| [27] | Q. Cai, A. Yates, Large-scale semantic parsing via schema matching and lexicon extension, in Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, 1 (2013), 423–433. |
| [28] | J. Berant, A. Chou, R. Frostig, P. Liang, Semantic parsing on freebase from question-answer pairs, in Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, (2013), 1533–1544. |
| [29] | T. Kwiatkowski, E. Choi, Y. Artzi, L. Zettlemoyer, Scaling semantic parsers with on-the-fly ontology matching, in Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, (2013), 1545–1556. |
| [30] | K. Luo, F. Lin, X. Luo, K. Q. Zhu, Knowledge base question answering via encoding of complex query graphs, in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, (2018), 2185–2194. https://doi.org/10.18653/v1/D18-1242 |
| [31] | P. Kapanipathi, I. Abdelaziz, S. Ravishankar, S. Roukos, A. G. Gray, R. F. Astudillo, et al., Question answering over knowledge bases by leveraging semantic parsing and neuro-symbolic reasoning, in Proceedings of the AAAI Conference on Artificial Intelligence, (2020), 1–10. |
| [32] |
S. Zhu, X. Cheng, S. Su, Knowledge-based question answering by tree-to-sequence learning, Neurocomputing, 372 (2020), 64–72. https://doi.org/10.1016/j.neucom.2019.09.003 doi: 10.1016/j.neucom.2019.09.003
|
| [33] | Y. Chen, H. Li, Y. Hua, G. Qi, Formal query building with query structure prediction for complex question answering over knowledge base, in Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, (2021), 3751–3758. https://doi.org/10.24963/ijcai.2020/519 |
| [34] | B. Min, R. Grishman, L. Wan, C. Wang, D. Gondek Distant supervision for relation extraction with an incomplete knowledge base, in Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics, (2013), 777–782. |
| [35] | H. Sun, B. Dhingra, M. Zaheer, K. Mazaitis, R. Salakhutdinov, W. W. Cohen, Open domain question answering using early fusion of knowledge bases and text, in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, (2018), 4231–4242. https://doi.org/10.18653/v1/D18-1455 |
| [36] | H. Sun, T. B. Weiss, W. W. Cohen, Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text, in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, (2019), 2380–2390. https://doi.org/10.18653/v1/D19-1242 |
| [37] | W. Xiong, M. Yu, S. Chang, X. Guo, W. Wang, Improving question answering over incomplete kbs with knowledge-aware reader, in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, (2019), 4258–4264. https://doi.org/10.18653/v1/P19-1417 |
| [38] | J. Han, B. Cheng, X. Wang, Open domain question answering based on text enhanced knowledge graph with hyperedge infusion, in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, (2020), 1475–1481. https://doi.org/10.18653/v1/2020.findings-emnlp.133 |
| [39] | A. Saxena, A. Tripathi, P. Talukdar, Improving multi-hop question answering over knowledge graphs using knowledge base embeddings, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, (2020), 4498–4507. https://doi.org/10.18653/v1/2020.acl-main.412 |
| [40] | A. Bordes, J. Weston, N. Usunier, Open question answering with weakly supervised embedding models, in Joint European Conference on Machine Learning and Knowledge Discovery in Databases, (2014), 165–180. |
| [41] | D. Guo, D. Tang, N. Duan, M. Zhou, J. Yin, Dialog-to-action: conversational question answering over a large-scale knowledge base, in Proceedings of the 32nd International Conference on Neural Information Processing Systems, 7 (2018), 2946–2955. |
| [42] | X. Huang, J. Zhang, D. Li, P. Li, Knowledge graph embedding based question answering, in Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, (2019), 105–113. https://doi.org/10.1145/3289600.3290956 |
| [43] | R. Wang, M. Wang, J. Liu, W. Chen, M. Cochez, S. Decker, Leveraging knowledge graph embeddings for natural language question answering, in International Conference on Database Systems for Advanced Applications, 11446 (2019), 659–675. https://doi.org/10.1007/978-3-030-18576-3_39 |
| [44] | L. Dong, F. Wei, M. Zhou, K. Xu, Question answering over freebase with multi-column convolutional neural networks, in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 1 (2015), 260–269. |
| [45] | Y. Lai, Y. Feng, X. Yu, Z. Wang, K. Xu, D. Zhao, Lattice cnns for matching based chinese question answering, in Proceedings of the AAAI Conference on Artificial Intelligence, 33 (2019), 6634–6641. https://doi.org/10.1609/aaai.v33i01.33016634 |
| [46] | Y. Hao, Y. Zhang, K. Liu, S. He, Z. Liu, H. Wu, et al., An end-to-end model for question answering over knowledge base with cross-attention combining global knowledge, in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, 1 (2017), 221–231. https://doi.org/10.18653/v1/P17-1021 |
| [47] | K. Tai, R. Socher, C. D. Manning, Improved semantic representations from tree-structured long short-term memory networks, in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 1 (2015), 1556–1566. |
| [48] | M. Cao, S. Li, X. Wang, Z. Yang, H. Lin,, DUTIR: Chinese open domain knowledge base question answering system, in Proceedings of the Evaluation Tasks at the China Conference on Knowledge Graph and Semantic Computing, 1 (2019), 1–6. |
| [49] | P. Zhang, K. Wu, Z. Zhu, Y. Jia, X. Zhou, W. Chen, et al., Combining neural network models with rules for Chinese knowledge base question answering, in Proceedings of the Evaluation Tasks at the China Conference on Knowledge Graph and Semantic Computing, 1 (2019), 1–12. |
| [50] | Z. Wang, Y. Hou, M. Wang, C. Li, Chinese knowledge base question answering method based on fusion feature, in Proceedings of the evaluation tasks at the china conference on knowledge graph and semantic computing, 1 (2020), 1–7. |
| [51] | J. Luo, C. Yin, X. Wu, L. Zhou, H. Zhong, Chinese knowledge base question answering system based on mixed semantic similarity, in Proceedings of the Evaluation Tasks at the China Conference on Knowledge Graph and Semantic Computing, 1 (2019), 1–12. |
| [52] | K. Wu, X. Zhou, Z. Li, X. Liang, W. Chen, Path selection for Chinese knowledge base question answering, J. Chin. Inf. Process., 35 (2021), 113–122. |
| [53] | M. Tang, H. Xiong, L. Wang, X. Lin, A dynamic answering path based fusion model for KGQA, in International Conference on Knowledge Science, Engineering and Management, 12274 (2020), 235–246. https://doi.org/10.1007/978-3-030-55130-8_21 |
| [54] |
H. Xiong, S. Wang, M. Tang, L. Wang, X. Lin, Knowledge graph question answering with semantic oriented fusion model, Knowl.-Based Syst., 221 (2021), 106954–106964. https://doi.org/10.1016/j.knosys.2021.106954 doi: 10.1016/j.knosys.2021.106954
|
| [55] | W. Dai, H. Liu, Y. Liu, R. Lv, S. Chen, An integrated path formulation method for open domain question answering over knowledge base, in Proceedings of the Evaluation Tasks at the China Conference on Knowledge Graph and Semantic Computing, 1 (2020), 1–10. |
| [56] | H. Zhang, R. Li, S. Wang, J. Huang, Retrieval-matching knowledge base question answering system based on pre-trained language model, in Proceedings of the Evaluation Tasks at the China Conference on Knowledge Graph and Semantic Computing, 1 (2020), 1–10. |
| [57] | Y. Cui, W. Che, T. Liu, B. Qin, S. Wang, G. Hu, Revisiting pre-trained models for Chinese natural language processing, in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 1 (2020), 657–668. https://doi.org/10.18653/v1/2020.findings-emnlp.58 |
| [58] | B. Steiner, Z. DeVito, S. Chintala, S. Gross, A. Paske, F. Massa, et al., Pytorch: An imperative style, high-performance deep learning library, in Proceedings of the Advances in Neural Information Processing Systems, (2019), 8026–8037. |
| [59] | Y. Zhao, H. Zhou, A. Zhang, R. Xie, Q. Li, F. Zhuang, Connecting embeddings based on multiplex relational graph attention networks for knowledge graph entity typing, IEEE Trans. Knowl. Data Eng., (2022), 1–12. https://doi.org/10.1109/TKDE.2022.3142056 |
| [60] |
H. Zhu, X. He, M. Wang, M. Zhang, L. Qing, Medical visual question answering via corresponding feature fusion combined with semantic attention, Math. Biosci. Eng., 19 (2022), 10192–10212. https://doi.org/10.3934/mbe.2022478 doi: 10.3934/mbe.2022478
|
| [61] | D. Prakash, L. Tuan, L. Thomas, B. Yoshua, B. Xavier, Graph neural networks with learnable structural and positional representations, preprint, arXiv: 2110.07875. https://doi.org/10.48550/arXiv.2110.07875 |








Figures(9) / Tables(2)

Meiling Wang, Xiaohai He, Zhao Zhang, Luping Liu, Linbo Qing, Yan Liu. Dual-process system based on mixed semantic fusion for Chinese medical knowledge-based question answering[J]. Mathematical Biosciences and Engineering, 2023, 20(3): 4912-4939. doi: 10.3934/mbe.2023228







 DownLoad:
DownLoad: