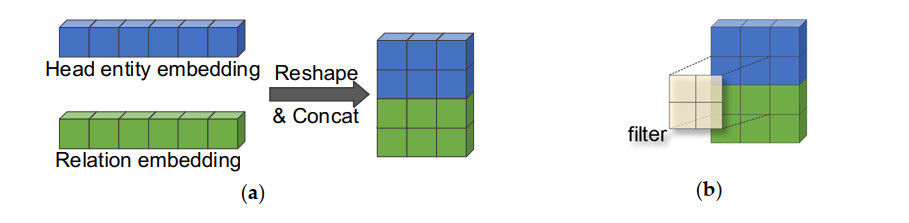
In response to the limited capability of extracting semantic information in knowledge graph completion methods, we propose a model that combines spatial transformation and attention mechanisms (STAM) for knowledge graph embedding. Firstly, spatial transformation is applied to reorganize entity embeddings and relation embeddings, enabling increased interaction between entities and relations while preserving shallow information. Next, a two-dimensional convolutional neural network is utilized to extract complex latent information among entity relations. Simultaneously, a multi-scale channel attention mechanism is constructed to enhance the capture of local detailed features and global semantic features. Finally, the surface-level shallow information and latent information are fused to obtain feature embeddings with richer semantic expression. The link prediction results on the public datasets WN18RR, FB15K237 and Kinship demonstrate that STAM achieved improvements of 8.8%, 10.5% and 6.9% in the mean reciprocal rank (MRR) evaluation metric compared to ConvE, for the respective datasets. Furthermore, in the link prediction experiments on the hydraulic engineering dataset, STAM achieves better experimental results in terms of MRR, Hits@1, Hits@3 and Hits@10 evaluation metrics, demonstrating the effectiveness of the model in the task of hydraulic engineering knowledge graph completion.
Citation: Yang Liu, Tianran Tao, Xuemei Liu, Jiayun Tian, Zehong Ren, Yize Wang, Xingzhi Wang, Ying Gao. Knowledge graph completion method for hydraulic engineering coupled with spatial transformation and an attention mechanism[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 1394-1412. doi: 10.3934/mbe.2024060
In response to the limited capability of extracting semantic information in knowledge graph completion methods, we propose a model that combines spatial transformation and attention mechanisms (STAM) for knowledge graph embedding. Firstly, spatial transformation is applied to reorganize entity embeddings and relation embeddings, enabling increased interaction between entities and relations while preserving shallow information. Next, a two-dimensional convolutional neural network is utilized to extract complex latent information among entity relations. Simultaneously, a multi-scale channel attention mechanism is constructed to enhance the capture of local detailed features and global semantic features. Finally, the surface-level shallow information and latent information are fused to obtain feature embeddings with richer semantic expression. The link prediction results on the public datasets WN18RR, FB15K237 and Kinship demonstrate that STAM achieved improvements of 8.8%, 10.5% and 6.9% in the mean reciprocal rank (MRR) evaluation metric compared to ConvE, for the respective datasets. Furthermore, in the link prediction experiments on the hydraulic engineering dataset, STAM achieves better experimental results in terms of MRR, Hits@1, Hits@3 and Hits@10 evaluation metrics, demonstrating the effectiveness of the model in the task of hydraulic engineering knowledge graph completion.

| [1] |
J. Yan, C. Wang, W. Cheng, M. Gao, A. Zhou, A retrospective of knowledge graphs, Front. Comput. Sci., 12 (2018), 55–74. https://doi.org/10.1007/s11704-016-5228-9 doi: 10.1007/s11704-016-5228-9

|
| [2] |
S. Ji, S. Pan, E. Cambria, P. Marttinen, P. S. Yu, A survey on knowledge graphs: Representation, acquisition, and applications, IEEE Trans. Neural Networks Learn. Syst., 33 (2022), 494–514. https://doi.org/10.1109/tnnls.2021.3070843 doi: 10.1109/tnnls.2021.3070843
|
| [3] |
N. Sitapure, J. S. I. Kwon, Design, exploring the potential of time-series transformers for process modeling and control in chemical systems: An inevitable paradigm shift?, Chem. Eng. Res. Des., 194 (2023), 461–477. https://doi.org/10.1016/j.cherd.2023.04.028 doi: 10.1016/j.cherd.2023.04.028
|
| [4] |
N. Sitapure, J. S. I. Kwon, Crystalgpt: Enhancing system-to-system transferability in crystallization prediction and control using time-series-transformers, Comput. Chem. Eng., 177 (2023), 108339. https://doi.org/10.1016/j.compchemeng.2023.108339 doi: 10.1016/j.compchemeng.2023.108339
|
| [5] |
J. Yan, T. Lv, Y. Yu, Construction and recommendation of a water affair knowledge graph, Sustainability, 10 (2018), 3429. https://doi.org/10.3390/su10103429 doi: 10.3390/su10103429
|
| [6] |
J. Feng, X. Xu, J. Lu, Construction and application of water conservancy information knowledge graph, Comput. Modernization, 9 (2019), 35–40. https://doi.org/10.3969/j.issn.1006-2475.2019.09.007 doi: 10.3969/j.issn.1006-2475.2019.09.007
|
| [7] |
L. Wang, X. Liu, Y. Liu, H. Li, J. Liu, L. Yang, Knowledge graph-based method for intelligent generation of emergency plans for water conservancy projects, IEEE Access, 11 (2023), 84414–84429. https://doi.org/10.1109/access.2023.3302399 doi: 10.1109/access.2023.3302399
|
| [8] |
E. Iglesias, S. Jozashoori, M. E. Vidal, Scaling up knowledge graph creation to large and heterogeneous data sources, J. Web Semant., 75 (2023), 100755. https://doi.org/10.1016/j.websem.2022.100755 doi: 10.1016/j.websem.2022.100755
|
| [9] |
S. Yang, S. Yoo, O. Jeong, Denert-KG: Named entity and relation extraction model using DQN, knowledge graph, and BERT, Appl. Sci.-Basel, 10 (2020), 6429. https://doi.org/10.3390/app10186429 doi: 10.3390/app10186429
|
| [10] |
T. Al-Moslmi, M. G. Ocana, A. L. Opdahl, C. Veres, Named entity extraction for knowledge graphs: A literature overview, IEEE Access, 8 (2020), 32862–32881. https://doi.org/10.1109/access.2020.2973928 doi: 10.1109/access.2020.2973928
|
| [11] |
Z. Geng, Y. Zhang, Y. Han, Joint entity and relation extraction model based on rich semantics, Neurocomputing, 429 (2021), 132–140. https://doi.org/10.1016/j.neucom.2020.12.037 doi: 10.1016/j.neucom.2020.12.037
|
| [12] |
T. Shen, F. Zhang, J. Cheng, A comprehensive overview of knowledge graph completion, Knowledge-Based Syst., 255 (2022), 109597. https://doi.org/10.1016/j.knosys.2022.109597 doi: 10.1016/j.knosys.2022.109597
|
| [13] | A. Rossi, D. Barbosa, D. Firmani, A. Matinata, P. Merialdo, Knowledge graph embedding for link prediction: A comparative analysis, ACM Trans. Knowl. Discovery Data, 15 (2021). https://doi.org/10.1145/3424672 |
| [14] |
Y. Dai, S. Wang, N. N. Xiong, W. Guo, A survey on knowledge graph embedding: Approaches, applications and benchmarks, Electronics, 9 (2020), 750. https://doi.org/10.3390/electronics9050750 doi: 10.3390/electronics9050750
|
| [15] |
Z. Chen, Y. Wang, B. Zhao, J. Cheng, X. Zhao, Z. Duan, Knowledge graph completion: A review, IEEE Access, 8 (2020), 192435–192456. https://doi.org/10.1109/access.2020.3030076 doi: 10.1109/access.2020.3030076
|
| [16] | A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, O. Yakhnenko, Translating embeddings for modeling multi-relational data, in Advances in Neural Information Processing Systems 26 (NIPS 2013), 26 (2013). |
| [17] | Z. Wang, J. Zhang, J. Feng, Z. Chen, Knowledge graph embedding by translating on hyperplanes, in Proceedings of the AAAI Conference on Artificial Intelligence, 28 (2014). https://doi.org/10.1609/aaai.v28i1.8870 |
| [18] | G. Ji, S. He, L. Xu, K. Liu, J. Zhao, Knowledge graph embedding via dynamic mapping matrix, in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (volume 1: Long papers), (2015), 687–696. https://doi.org/10.3115/v1/P15-1067 |
| [19] | Z. Sun, Z. H. Deng, J. Y. Nie, J. Tang, Rotate: Knowledge graph embedding by relational rotation in complex space, preprint, arXiv: 1902.10197. https://doi.org/10.48550/arXiv.1902.10197 |
| [20] | T. Dettmers, P. Minervini, P. Stenetorp, S. Riedel, Convolutional 2D knowledge graph embeddings, in Proceedings of the AAAI Conference on Artificial Intelligence, 32 (2018). https://doi.org/10.1609/aaai.v32i1.11573 |
| [21] | X. Jiang, Q. Wang, B. Wang, Adaptive convolution for multi-relational learning, in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), (2019), 978–987. https://doi.org/10.18653/v1/N19-1103 |
| [22] | S. Vashishth, S. Sanyal, V. Nitin, N. Agrawal, P. Talukdar, Interacte: Improving convolution-based knowledge graph embeddings by increasing feature interactions, in Proceedings of the AAAI Conference on Artificial Intelligence, (2020), 3009–3016. https://doi.org/10.1609/aaai.v34i03.5694 |
| [23] |
Z. Zhou, C. Wang, Y. Feng, D. Chen, JointE: Jointly utilizing 1D and 2D convolution for knowledge graph embedding, Knowledge-Based Syst., 240 (2022), 108100. https://doi.org/10.1016/j.knosys.2021.108100 doi: 10.1016/j.knosys.2021.108100
|
| [24] | S. Jia, Y. Xiang, X. Chen, K. Wang, Triple trustworthiness measurement for knowledge graph, in the World Wide Web Conference, (2019), 2865–2871. https://doi.org/10.1145/3308558.3313586 |
| [25] |
Z. Zhang, Z. Li, H. Liu, N. N. Xiong, Multi-scale dynamic convolutional network for knowledge graph embedding, IEEE Trans. Knowl. Data Eng., 34 (2020), 2335–2347. https://doi.org/10.1109/TKDE.2020.3005952 doi: 10.1109/TKDE.2020.3005952
|
| [26] | D. Q. Nguyen, T. D. Nguyen, D. Q. Nguyen, D. Phung, A novel embedding model for knowledge base completion based on convolutional neural network, in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), (2017), 327–333. http://dx.doi.org/10.18653/v1/N18-2053 |
| [27] | L. Thanh, L. Nam, L. Bac, Knowledge graph embedding by relational rotation and complex convolution for link prediction, Expert Syst. Appl., 214 (2023). https://doi.org/10.1016/j.eswa.2022.119122 |
| [28] |
M. Nayyeri, G. M. Cil, S. Vahdati, F. Osborne, M. Rahman, S. Angioni, et al., Trans4E: Link prediction on scholarly knowledge graphs, Neurocomputing, 461 (2021), 530–542. https://doi.org/10.1016/j.neucom.2021.02.100 doi: 10.1016/j.neucom.2021.02.100
|
| [29] | I. Balažević, C. Allen, T. M. Hospedales, Hypernetwork knowledge graph embeddings, in Artificial Neural Networks and Machine Learning–ICANN 2019: Workshop and Special Sessions: 28th International Conference on Artificial Neural Networks, Springer, 11731 (2019), 553–565. https://doi.org/10.1007/978-3-030-30493-5_52 |
| [30] |
D. Jiang, R. Wang, L. Xue, J. Yang, Multiview feature augmented neural network for knowledge graph embedding, Knowledge-Based Syst., 255 (2022), 109721. https://doi.org/10.1016/j.knosys.2022.109721 doi: 10.1016/j.knosys.2022.109721
|
| [31] | K. Toutanova, D. Chen, P. Pantel, H. Poon, P. Choudhury, M. Gamon, Representing text for joint embedding of text and knowledge bases, in Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, (2015), 1499–1509. https://doi.org/10.18653/v1/D15-1174 |
| [32] | X. V. Lin, R. Socher, C. Xiong, Multi-hop knowledge graph reasoning with reward shaping, preprint, arXiv: 1808.10568. https://doi.org/10.48550/arXiv.1808.10568 |
| [33] |
A. Bordes, X. Glorot, J. Weston, Y. Bengio, A semantic matching energy function for learning with multi-relational data: Application to word-sense disambiguation, Mach. Learn., 94 (2014), 233–259. https://doi.org/10.1007/s10994-013-5363-6 doi: 10.1007/s10994-013-5363-6
|







Figures(8) / Tables(6)

Yang Liu, Tianran Tao, Xuemei Liu, Jiayun Tian, Zehong Ren, Yize Wang, Xingzhi Wang, Ying Gao. Knowledge graph completion method for hydraulic engineering coupled with spatial transformation and an attention mechanism[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 1394-1412. doi: 10.3934/mbe.2024060







 DownLoad:
DownLoad: