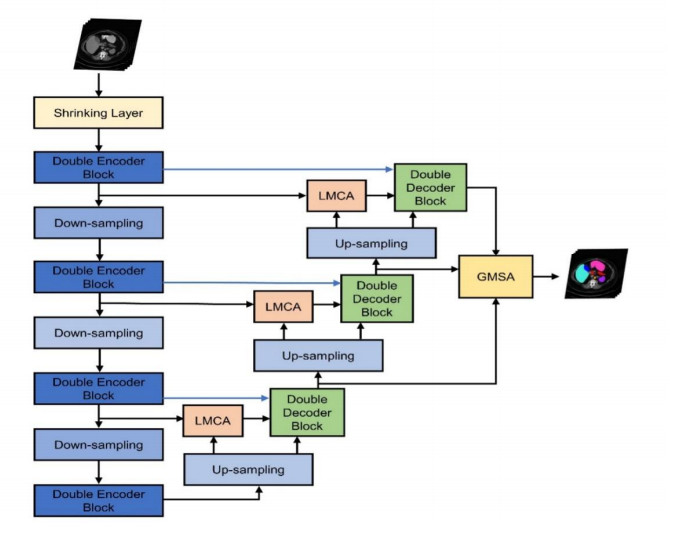
Transformer is widely used in medical image segmentation tasks due to its powerful ability to model global dependencies. However, most of the existing transformer-based methods are two-dimensional networks, which are only suitable for processing two-dimensional slices and ignore the linguistic association between different slices of the original volume image blocks. To solve this problem, we propose a novel segmentation framework by deeply exploring the respective characteristic of convolution, comprehensive attention mechanism, and transformer, and assembling them hierarchically to fully exploit their complementary advantages. Specifically, we first propose a novel volumetric transformer block to help extract features serially in the encoder and restore the feature map resolution to the original level in parallel in the decoder. It can not only obtain the information of the plane, but also make full use of the correlation information between different slices. Then the local multi-channel attention block is proposed to adaptively enhance the effective features of the encoder branch at the channel level, while suppressing the invalid features. Finally, the global multi-scale attention block with deep supervision is introduced to adaptively extract valid information at different scale levels while filtering out useless information. Extensive experiments demonstrate that our proposed method achieves promising performance on multi-organ CT and cardiac MR image segmentation.
Citation: Zhuang Zhang, Wenjie Luo. Hierarchical volumetric transformer with comprehensive attention for medical image segmentation[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 3177-3190. doi: 10.3934/mbe.2023149
Transformer is widely used in medical image segmentation tasks due to its powerful ability to model global dependencies. However, most of the existing transformer-based methods are two-dimensional networks, which are only suitable for processing two-dimensional slices and ignore the linguistic association between different slices of the original volume image blocks. To solve this problem, we propose a novel segmentation framework by deeply exploring the respective characteristic of convolution, comprehensive attention mechanism, and transformer, and assembling them hierarchically to fully exploit their complementary advantages. Specifically, we first propose a novel volumetric transformer block to help extract features serially in the encoder and restore the feature map resolution to the original level in parallel in the decoder. It can not only obtain the information of the plane, but also make full use of the correlation information between different slices. Then the local multi-channel attention block is proposed to adaptively enhance the effective features of the encoder branch at the channel level, while suppressing the invalid features. Finally, the global multi-scale attention block with deep supervision is introduced to adaptively extract valid information at different scale levels while filtering out useless information. Extensive experiments demonstrate that our proposed method achieves promising performance on multi-organ CT and cardiac MR image segmentation.

| [1] |
G. Litjens, T. Kooi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi, M. Ghafoorian, et al., A survey on deep learning in medical image analysis, Med. Image Anal., 42 (2017), 60–88. https://doi.org/10.1016/j.media.2017.07.005 doi: 10.1016/j.media.2017.07.005

|
| [2] |
A. Sáez, C. Serrano, B. Acha, Model-based classification methods of global patterns in dermoscopic images, IEEE Trans. Med. Imaging, 33 (2014), 1137–1147. https://doi.org/10.1109/TMI.2014.2305769 doi: 10.1109/TMI.2014.2305769
|
| [3] |
Y. Zhao, H. Li, S. Wan, A. Sekuboyina, X. Hu, G. Tetteh, et al., Knowledge-aided convolutional neural network for small organ segmentation, IEEE J. Biomed. Health Inf., 23 (2019), 1363–1373. https://doi.org/10.1109/JBHI.2019.2891526 doi: 10.1109/JBHI.2019.2891526
|
| [4] |
X. Fang, P. Yan, Multi-organ segmentation over partially labeled datasets with multi-scale feature abstraction, IEEE Trans. Med. Imaging, 39 (2020), 3619–3629. https://doi.org/10.1109/TMI.2020.3001036 doi: 10.1109/TMI.2020.3001036
|
| [5] | Y. Fang, C. Chen, Y. Yuan, K. Y. Tong, Selective feature aggregation network with area-boundary constraints for polyp segmentation, in International Conference on Medical Image Computing and Computer Assisted Intervention, (2019), 302–310. https://doi.org/10.1007/978-3-030-32239-7_34 |
| [6] | F. Milletari, N. Navab, S. A. Ahmadi, V-net: Fully convolutional neural networks for volumetric medical image segmentation, in 2016 Fourth International Conference on 3D Vision (3DV), (2016), 565–571. https://doi.org/10.1109/3DV.2016.79 |
| [7] |
T. Jin, X. Yang, Monotonicity theorem for the uncertain fractional differential equation and application to uncertain financial market, Math. Comput. Simul., 190 (2021), 203–221. https://doi.org/10.1016/j.matcom.2021.05.018 doi: 10.1016/j.matcom.2021.05.018
|
| [8] |
T. Jin, X. Yang, H. Xia, H. U. I. Ding, Reliability index and option pricing formulas of the first-hitting time model based on the uncertain fractional-order differential equation with Caputo type, Fractals., 29 (2021), 21500122. https://doi.org/10.1142/S0218348X21500122 doi: 10.1142/S0218348X21500122
|
| [9] |
C. Tian, T. Jin, X. Yang, Q. Liu, Reliability analysis of the uncertain heat conduction model, Comput. Math. Appl., 119 (2022), 131–140. https://doi.org/10.1016/j.camwa.2022.05.033.5 doi: 10.1016/j.camwa.2022.05.033.5
|
| [10] | O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional networks for biomedical image segmentation, in International Conference on Medical Image Computing and Computer-assisted Intervention, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [11] | Ö. Çiçek, A. Abdulkadir, S. S. Lienkamp, T. Brox, O. Ronneberger, 3D U-Net: Learning dense volumetric segmentation from sparse annotation, in International Conference on Medical Image Computing and Computer-assisted Intervention, (2016), 424–432. https://doi.org/10.1007/978-3-319-46723-8_49 |
| [12] | S. Zhang, H. Fu, Y. Yan, Y. Zhang, Q. Wu, M. Yang, et al., Attention guided network for retinal image segmentation, in Medical Image Computing and Computer Assisted Intervention, (2019), 797–805. https://doi.org/10.1007/978-3-030-32239-7_88 |
| [13] |
W. Bo, Y. Lei, S. Tian, T. Wang, Y. Liu, P. Patel, et al., Deeply supervised 3D fully convolutional networks with group dilated convolution for automatic MRI prostate segmentation, Med. Phys., 46 (2019), 1707–1718. https://doi.org/10.1002/mp.13416 doi: 10.1002/mp.13416
|
| [14] | J. Chen, X. Wang, Z. Guo, X. Zhang, J. Sun, Dynamic region-aware convolution, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 8064–8073. |
| [15] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, in Advances in Neural Information Processing Systems, (2017), 1–11. |
| [16] | M. Raghu, T. Unterthiner, S. Kornblith, C. Zhang, A. Dosovitskiy, Do vision transformers see like convolutional neural networks, preprint, arXiv: 2108.08810. |
| [17] | X. Zhai, A. Kolesnikov, N. Houlsby, L. Beyer, Scaling vision transformers, preprint, arXiv: 2106.04560. |
| [18] | B. Cheng, A. G. Schwing, A. Kirillov, Per-pixel classification is not all you need for semantic segmentation, preprint, arXiv: 2107.06278. |
| [19] | S. Zheng, J. Lu, H. Zhao, X. Zhu, Z. Luo, Y. Wang, et al., Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 6881–6890. |
| [20] | J. Chen, Y. Lu, Q. Yu, X. Luo, E. Adeli, Y. Wang, et al., TransUNet: Transformers make strong encoders for medical image segmentation, preprint, arXiv: 2102.04306. |
| [21] | H. Cao, Y. Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, et al., Swin-Unet: Unet-like pure transformer for medical image segmentation, preprint, arXiv: 2105.05537. |
| [22] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al., An image is worth 16x16 words: Transformers for image recognition at scale, preprint, arXiv: 2010.11929. |
| [23] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 10012–10022. |
| [24] | J. M. J. Valanarasu, P. Oza, I. Hacihaliloglu, V. M. Patel, Medical transformer: Gated axial-attention for medical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2021), 36–46. https://doi.org/10.1007/978-3-030-87193-2_4 |
| [25] | Y. Zhang, H. Liu, Q. Hu, Transfuse: Fusing transformers and cnns for medical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2021), 14–24. https://doi.org/10.1007/978-3-030-87193-2_2 |
| [26] | W. Wang, C. Chen, M. Ding, H. Yu, S. Zha, J. Li, Transbts: Multimodal brain tumor segmentation using transformer, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2021), 109–119. https://doi.org/10.1007/978-3-030-87193-2_11 |
| [27] | Y. Xie, J. Zhang, C. Shen, Y. Xia, Cotr: Efficiently bridging cnn and transformer for 3d medical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2021), 171–180. https://doi.org/10.1007/978-3-030-87199-4_16 |
| [28] | H. Wang, P. Cao, J. Wang, O. R. Zaiane, UCTransNet: Rethinking the skip connections in U-Net from a channel-wise perspective with transformer, preprint, arXiv: 2109.04335. |
| [29] | H. Y. Zhou, J. Guo, Y. Zhang, L. Yu, L. Wang, Y. Yu, nnformer: Interleaved transformer for volumetric segmentation, preprint, arXiv: 2109.03201. |
| [30] | B. Landman, Z. Xu, J. E. Igelsias, M. Styner, T. Langerak, A. Klein, Miccai multi-atlas labeling beyond the cranial vault–workshop and challenge, In Proc. MICCAI: Multi-Atlas Labeling Beyond Cranial Vault-Workshop Challenge, 5 (2015), 12. |
| [31] |
O. Bernard, A. Lalande, C. Zotti, F. Cervenansky, X. Yang, P. A. Heng, et al., Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: Is the problem solved, IEEE Trans. Med. Imaging, 37 (2018), 2514–2525. https://doi.org/10.1109/TMI.2018.2837502 doi: 10.1109/TMI.2018.2837502
|
| [32] | Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh, J. Liang, Unet++: A nested u-net architecture for medical image segmentation, in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, (2018), 3–11. https://doi.org/10.1007/978-3-030-00889-5_1 |
| [33] | H. Huang, L. Lin, R. Tong, H. Hu, Q. Zhang, Y. Iwamoto, et al., Unet 3+: A full-scale connected unet for medical image segmentation, in IEEE International Conference on Acoustics, Speech and Signal Processing, (2020), 1055–1059. https://doi.org/10.1109/ICASSP40776.2020.9053405 |
| [34] |
Z. Gu, J. Cheng, H. Fu, K. Zhou, H. Hao, Y. Zhao, et al., CE-Net: Context encoder network for 2D medical image segmentation, IEEE Trans. Med. Imaging, 38 (2019), 2281–2292. https://doi.org/10.1109/TMI.2019.2903562 doi: 10.1109/TMI.2019.2903562
|
| [35] |
I. Fabian, P. F. Jaeger, S. A. A. Kohl, J. Petersen, K. H. Maier-Hein, nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation, Nat. Methods, 18 (2021), 203–211. https://doi.org/10.1038/s41592-020-01008-z doi: 10.1038/s41592-020-01008-z
|
| [36] | A. Hatamizadeh, Y. Tang, V. Nath, D. Yang, A. Myronenko, B. Landman, et al., Unetr: Transformers for 3d medical image segmentation, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, (2022), 574–584. |
| [37] | O. Ozan, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, et al., Attention u-net: Learning where to look for the pancreas, preprint, arXiv: 1804.03999. |
| [38] |
R. Gu, G. Wang, T. Song, R. Huang, M. Aertsen, J. Deprest, et al., CA-Net: Comprehensive attention convolutional neural networks for explainable medical image segmentation, IEEE Trans. Med. Imaging, 40 (2020), 699–711. https://doi.org/10.1109/TMI.2020.3035253 doi: 10.1109/TMI.2020.3035253
|
| [39] | S. Woo, J. Park, J. Y. Lee, I. S. Kweon, Cbam: Convolutional block attention module, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 3–19. |
| [40] | Y. Gao, M. Zhou, D. N. Metaxas, UTNet: A hybrid transformer architecture for medical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2021), 61–71. https://doi.org/10.1007/978-3-030-87199-4_6 |






Figures(7) / Tables(4)

Zhuang Zhang, Wenjie Luo. Hierarchical volumetric transformer with comprehensive attention for medical image segmentation[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 3177-3190. doi: 10.3934/mbe.2023149







 DownLoad:
DownLoad: