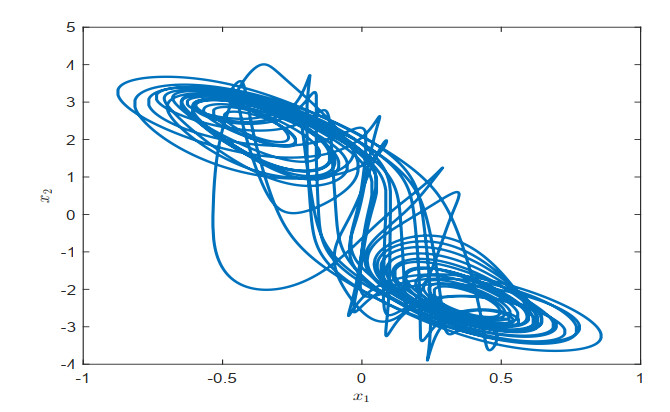
This paper is devoted to event-triggered non-fragile cost-guaranteed synchronization control for time-delay neural networks. The switched event-triggered mechanism, which combines periodic sampling and continuous event triggering, is used in the feedback channel. A piecewise functional is first applied to fully utilize the information of the state and activation function. By employing the functional, various integral inequalities, and the free-weight matrix technique, a sufficient condition is established for exponential synchronization and cost-related performance. Then, a joint design of the needed non-fragile feedback gain and trigger matrix is derived by decoupling several nonlinear coupling terms. On the foundation of the joint design, an optimization scheme is given to acquire the minimum cost value while ensuring exponential stability of the synchronization-error system. Finally, a numerical example is used to illustrate the applicability of the present design scheme.
Citation: Wenjing Wang, Jingjing Dong, Dong Xu, Zhilian Yan, Jianping Zhou. Synchronization control of time-delay neural networks via event-triggered non-fragile cost-guaranteed control[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 52-75. doi: 10.3934/mbe.2023004
This paper is devoted to event-triggered non-fragile cost-guaranteed synchronization control for time-delay neural networks. The switched event-triggered mechanism, which combines periodic sampling and continuous event triggering, is used in the feedback channel. A piecewise functional is first applied to fully utilize the information of the state and activation function. By employing the functional, various integral inequalities, and the free-weight matrix technique, a sufficient condition is established for exponential synchronization and cost-related performance. Then, a joint design of the needed non-fragile feedback gain and trigger matrix is derived by decoupling several nonlinear coupling terms. On the foundation of the joint design, an optimization scheme is given to acquire the minimum cost value while ensuring exponential stability of the synchronization-error system. Finally, a numerical example is used to illustrate the applicability of the present design scheme.

| [1] |
W. Ren, R. W. Beard, Speech synthesis from neural decoding of spoken sentences, Nature, 568 (2019), 493–498. https://doi.org/10.1038/s41586-019-1119-1 doi: 10.1038/s41586-019-1119-1

|
| [2] | F. A. Gers, E. Schmidhuber, LSTM recurrent networks learn simple context-free and context-sensitive languages, {IEEE Trans. Neural Netw., 12 (2001), 1333–1340. https://doi.org/10.1109/72.963769 |
| [3] |
R. K. Brouwer, Growing of a fuzzy recurrent artificial neural network (FRANN) for pattern classification, Int. J. Neural Syst., 9 (1999), 335–350. https://doi.org/10.1142/S0129065799000320 doi: 10.1142/S0129065799000320
|
| [4] |
H. Hewamalage, C. Bergmeir, K. Bandara, Recurrent neural networks for time series forecasting: Current status and future directions, Int. J. Forecasting, 37 (2021), 388–427. https://doi.org/10.1016/j.ijforecast.2020.06.008 doi: 10.1016/j.ijforecast.2020.06.008
|
| [5] |
Y. Cao, R. Sriraman, N. Shyamsundarraj, R. Samidurai, Robust stability of uncertain stochastic complex-valued neural networks with additive time-varying delays, Math. Comput. Simul., 171 (2020), 207–220. https://doi.org/10.1016/j.matcom.2019.05.011 doi: 10.1016/j.matcom.2019.05.011
|
| [6] |
T. H. Lee, H. M. Trinh, J. H. Park, Stability analysis of neural networks with time-varying delay by constructing novel Lyapunov functionals, IEEE Trans. Neural Netw. Learn. Syst., 29 (2018), 4238–4247. https://doi.org/10.1109/TNNLS.2017.2760979 doi: 10.1109/TNNLS.2017.2760979
|
| [7] | S. Arik, New criteria for stability of neutral-type neural networks with multiple time delays, IEEE Trans. Neural Netw. Learn. Syst., 31 (2020), 1504–1513. https://doi.org/10.1109/TNNLS.2019.2920672 |
| [8] |
N. M. Thoiyab, P. Muruganantham, Q. Zhu, N. Gunasekaran, Novel results on global stability analysis for multiple time-delayed BAM neural networks under parameter uncertainties, Chaos Solitons Fractals, 152 (2021), 111441. https://doi.org/10.1016/j.chaos.2021.111441 doi: 10.1016/j.chaos.2021.111441
|
| [9] |
L. Fan, Q. Zhu, Mean square exponential stability of discrete-time Markov switched stochastic neural networks with partially unstable subsystems and mixed delays, Inf. Sci., 580 (2021), 243–259. https://doi.org/10.1016/j.ins.2021.08.068 doi: 10.1016/j.ins.2021.08.068
|
| [10] |
Q. Wu, Z. Yao, Z. Yin, H. Zhang, Fin-TS and Fix-TS on fractional quaternion delayed neural networks with uncertainty via establishing a new Caputo derivative inequality approach, Math. Biosci. Eng., 19 (2022), 9220–9243. https://doi.org/10.3934/mbe.2022428 doi: 10.3934/mbe.2022428
|
| [11] |
W. Tai, D. Zuo, Z. Xuan, J. Zhou, Z. Wang, Non-fragile $L_2-L_\infty$ filtering for a class of switched neural networks, Math. Comput. Simul., 185 (2021), 629–645. https://doi.org/10.1016/j.matcom.2021.01.014 doi: 10.1016/j.matcom.2021.01.014
|
| [12] | J. Cheng, L. Liang, H. Yan, J. Cao, S. Tang, K. Shi, Proportional-integral observer-based state estimation for Markov memristive neural networks with sensor saturations, IEEE Trans. Neural Netw. Learn. Syst., 2022. https://doi.org/10.1109/TNNLS.2022.3174880 |
| [13] |
N. Gunasekaran, M. S. Ali, Design of stochastic passivity and passification for delayed BAM neural networks with Markov jump parameters via non-uniform sampled-data control, Neural Process. Lett., 53 (2021), 391–404. https://doi.org/10.1007/s11063-020-10394-6 doi: 10.1007/s11063-020-10394-6
|
| [14] |
A. Abdurahman, H. Jiang, C. Hu, Z. Teng, Parameter identification based on finite-time synchronization for Cohen–Grossberg neural networks with time-varying delays, Nonlinear Anal., Model. Control, 20 (2015), 348–366. https://doi.org/10.15388/NA.2015.3.3 doi: 10.15388/NA.2015.3.3
|
| [15] |
M. Kalpana, K. Ratnavelu, P. Balasubramaniam, M. Z. M. Kamali, Synchronization of chaotic-type delayed neural networks and its application, Nonlinear Dyn., 93 (2018), 543–555. https://doi.org/10.1007/s11071-018-4208-z doi: 10.1007/s11071-018-4208-z
|
| [16] |
A. M. Alimi, C. Aouiti, E. A. Assali, M. Z. M. Kamali, Finite-time and fixed-time synchronization of a class of inertial neural networks with multi-proportional delays and its application to secure communication, Neurocomputing, 332 (2019), 29–43. https://doi.org/10.1016/j.neucom.2018.11.020 doi: 10.1016/j.neucom.2018.11.020
|
| [17] |
T. H. Lee, J. H. Park, Improved criteria for sampled-data synchronization of chaotic {Lur'e} systems using two new approaches, Nonlin. Anal. Hybrid Syst., 24 (2017), 132–145. https://doi.org/10.1016/j.nahs.2016.11.006 doi: 10.1016/j.nahs.2016.11.006
|
| [18] | L. Wang, Y. Shen, G. Zhang, Synchronization of a class of switched neural networks with time-varying delays via nonlinear feedback control, IEEE Trans. Cybern., 46 (2016), 2300–2310. https://doi.org/10.1109/TCYB.2015.2475277 |
| [19] |
Y. Zhao, X. Li, P. Duan, Observer-based sliding mode control for synchronization of delayed chaotic neural networks with unknown disturbance, Neural Networks, 117 (2019), 268–273. https://doi.org/10.1016/j.neunet.2019.05.013 doi: 10.1016/j.neunet.2019.05.013
|
| [20] |
D. Tong, L. Zhang, W. Zhou, J. Zhou, Y. Xu, Asymptotical synchronization for delayed stochastic neural networks with uncertainty via adaptive control, Int. J. Control Autom. Syst., 14 (2016), 706–712. https://doi.org/10.1007/s12555-015-0077-0 doi: 10.1007/s12555-015-0077-0
|
| [21] |
H. Li, C. Li, D. Ouyang, S. K. Nguang, Impulsive synchronization of unbounded delayed inertial neural networks with actuator saturation and sampled-data control and its application to image encryption, IEEE Trans. Neural Networks Learn. Syst., 32 (2021), 1460–1473. https://doi.org/10.1109/TNNLS.2020.2984770 doi: 10.1109/TNNLS.2020.2984770
|
| [22] |
G. Chen, J. Xia, J. H. Park, H. Shen, G. Zhuang, Sampled-data synchronization of stochastic Markovian jump neural networks with time-varying delay, IEEE Trans. Neural Networks Learn. Syst., 33 (2022), 3829–3841. https://doi.org/10.1109/TNNLS.2021.3054615 doi: 10.1109/TNNLS.2021.3054615
|
| [23] |
M. Dlala and S. O. Alrashidi, Rapid exponential stabilization of Lotka-McKendrick's equation via event-triggered impulsive control, Math. Biosci. Eng., 18 (2021), 9121–9131. https://doi.org/10.3934/mbe.2021449 doi: 10.3934/mbe.2021449
|
| [24] |
Z. Gu, S. Yan, J. H. Park, X. Xie, Event-triggered synchronization of chaotic Lur'e systems via memory-based triggering approach, IEEE Trans. Circuits Syst. II Express Briefs, 69 (2022), 1427–1431. https://doi.org/10.1109/TCSII.2021.3113955 doi: 10.1109/TCSII.2021.3113955
|
| [25] |
J. Wu, S. Qiu, M. Liu, H. Li, Y. Liu, Finite-time velocity-free relative position coordinated control of spacecraft formation with dynamic event triggered transmission, Math. Biosci. Eng., 19 (2022), 6883–6906. https://doi.org/10.3934/mbe.2022324 doi: 10.3934/mbe.2022324
|
| [26] | J. Cheng, J. H. Park, Z. Wu, Observer-based asynchronous control of nonlinear systems with dynamic event-based try-once-discard protocol, IEEE Trans. Cybern., 2021. https://doi.org/10.1109/TCYB.2021.3104806 |
| [27] |
J. Lunze, D. Lehmann, A state-feedback approach to event-based control, Automatica, 46 (2010), 211–215. https://doi.org/10.1016/j.automatica.2009.10.035 doi: 10.1016/j.automatica.2009.10.035
|
| [28] | D. Yue, E. Tian, Q. Han, A delay system method for designing event-triggered controllers of networked control systems, IEEE Trans. Autom. Control, 58 (2012), 475–481. https://doi.org/10.1109/TAC.2012.2206694 |
| [29] |
M. Xing, F. Deng, X. Zhao, Synchronization of stochastic complex dynamical networks under self-triggered control, Int. J. Robust Nonlinear Control, 27 (2017), 2861–2878. https://doi.org/10.1002/rnc.3716 doi: 10.1002/rnc.3716
|
| [30] |
J. Zhang, E. Fridman, Dynamic event-triggered control of networked stochastic systems with scheduling protocols, IEEE Trans. Autom. Control, 66 (2021), 6139–6147. https://doi.org/10.1109/TAC.2021.3061668 doi: 10.1109/TAC.2021.3061668
|
| [31] |
A. Selivanov, E. Fridman, Event-triggered $H_{\infty}$ control: A switching approach, IEEE Trans. Autom. Control, 61 (2015), 3221–3226. https://doi.org/10.1109/TAC.2015.2508286 doi: 10.1109/TAC.2015.2508286
|
| [32] |
Z. Yan, X. Huang, J. Cao, Variable-sampling-period dependent global stabilization of delayed memristive neural networks based on refined switching event-triggered control, Sci. China Inf. Sci., 63 (2020), 212201. https://doi.org/10.1007/s11432-019-2664-7 doi: 10.1007/s11432-019-2664-7
|
| [33] |
S. Ding, X. Xie, Y. Liu, Event-triggered static/dynamic feedback control for discrete-time linear systems, Inf. Sci., 524 (2020), 33–45. https://doi.org/10.1016/j.ins.2020.03.044 doi: 10.1016/j.ins.2020.03.044
|
| [34] |
W. Wu, L. He, J. Zhou, Z. Xuan, S. Arik, Disturbance-term-based switching event-triggered synchronization control of chaotic Lurie systems subject to a joint performance guarantee, Commun. Nonlinear Sci. Numer. Simul., 115 (2022), 106774. https://doi.org/10.1016/j.cnsns.2022.106774 doi: 10.1016/j.cnsns.2022.106774
|
| [35] | W. Wang, D. Xu, J. Zhou, Z. Yan, Cost-guaranteed exponential stabilization of Lurie systems via switched event-triggered control, Discrete Cont. Dyn. B, 2022. https://doi.org/10.3934/dcdsb.2022194 |
| [36] |
Y. Zhou, H. Zhang, Z. Zeng, Quasisynchronization of memristive neural networks with communication delays via event-triggered impulsive control, IEEE Trans. Cybern., 52 (2022), 7682–7693. https://doi.org/10.1109/TCYB.2020.3035358 doi: 10.1109/TCYB.2020.3035358
|
| [37] |
Z. Yan, X. Huang, Y. Fan, J. Xia, H. Shen, Threshold-function-dependent quasi-synchronization of delayed memristive neural networks via hybrid event-triggered control, IEEE Trans. Syst., Man, Cybern., 51 (2021), 6712–6722. https://doi.org/10.1109/TSMC.2020.2964605 doi: 10.1109/TSMC.2020.2964605
|
| [38] |
S. Yan, S. K. Nguang, Z. Gu, $H_\infty$ weighted integral event-triggered synchronization of neural networks with mixed delays, IEEE Trans. Ind. Informat., 17 (2021), 2365–2375. https://doi.org/10.1109/TII.2020.3004461 doi: 10.1109/TII.2020.3004461
|
| [39] |
X. Chang, Y. Liu, M. Shen, Resilient control design for lateral motion regulation of intelligent vehicle, IEEE ASME Trans. Mechatronics, 24 (2019), 2488–2497. https://doi.org/10.1109/TMECH.2019.2946895 doi: 10.1109/TMECH.2019.2946895
|
| [40] |
J. Zhou, Y. Liu, J. Xia, Z. Wang, S. Arik, Resilient fault-tolerant anti-synchronization for stochastic delayed reaction–diffusion neural networks with semi-Markov jump parameters, Neural Networks, 125 (2020), 194–204. https://doi.org/10.1016/j.neunet.2020.02.015 doi: 10.1016/j.neunet.2020.02.015
|
| [41] |
R. Sakthivel, C. Wang, S. Santra, B. Kaviarasan, Non-fragile reliable sampled-data controller for nonlinear switched time-varying systems, Nonlin. Anal. Hybrid Syst., 27 (2018), 62–76. https://doi.org/10.1016/j.nahs.2017.08.005 doi: 10.1016/j.nahs.2017.08.005
|
| [42] | J. H. Park, H. Shen, X. Chang, T. H. Lee, Fuzzy resilient energy-to-peak filter design for continuous-time nonlinear systems, in Recent Advances in Control and Filtering of Dynamic Systems with Constrained Signals, Cham: Springer, (2019), 119–139. https://doi.org/10.1007/978-3-319-96202-3 |
| [43] | X. Chang, Takagi-Sugeno Fuzzy Systems Non-fragile H-infinity Filtering, Berlin: Springer-Verlag, 2012. https://doi.org/10.1007/978-3-642-28632-2 |
| [44] |
L. Chen, Y. Chen, N. Zhang, Synchronization control for chaotic neural networks with mixed delays under input saturations, Neural Process. Lett., 53 (2021), 3735–3755. https://doi.org/10.1007/s11063-021-10577-9 doi: 10.1007/s11063-021-10577-9
|
| [45] | L. He, W. Wu, Q. Zhu, G. Yao, J. Zhou, Input-to-state stabilization of delayed semi-Markovian jump neural networks via sampled-data control, Neural Process. Lett., 2022. https://doi.org/10.1007/s11063-022-11008-z |
| [46] |
H. Lu, Chaotic attractors in delayed neural networks, Phys. Lett. A, 298 (2002), 109–116. https://doi.org/10.1016/S0375-9601(02)00538-8 doi: 10.1016/S0375-9601(02)00538-8
|
| [47] | S. Santra, R. Sakthivel, K. Mathiyalagan, A. S. Marshal, Exponential passivity results for singular networked cascade control systems via sampled-data control, J. Dyn. Syst., Means. Control, 139 (2017). https://doi.org/10.1115/1.4034781 |
| [48] |
M. S. Ali, N. Gunasekaran, J. Cao, Sampled-data state estimation for neural networks with additive time-varying delays, Acta Math. Sci., 39 (2019), 195–213. https://doi.org/10.1007/s10473-019-0116-7 doi: 10.1007/s10473-019-0116-7
|
| [49] |
N. Gunasekaran, G. Zhai, Q. Yu, Sampled-data synchronization of delayed multi-agent networks and its application to coupled circuit, Neurocomputing, 413 (2020), 499–511. https://doi.org/10.1016/j.neucom.2020.05.060 doi: 10.1016/j.neucom.2020.05.060
|
| [50] |
S. Santra, M. Joby, M. Sathishkumar, S. M. Anthoni, LMI approach-based sampled-data control for uncertain systems with actuator saturation: application to multi-machine power system, Nonlinear Dyn., 107 (2022), 967–982. https://doi.org/10.1007/s11071-021-06995-y doi: 10.1007/s11071-021-06995-y
|
| [51] |
N. Gunasekaran, M. S. Ali, S. Arik, H. A. Ghaffar, A. A. Z. Diab, Finite-time and sampled-data synchronization of complex dynamical networks subject to average dwell-time switching signal, Neural Networks, 149 (2022), 137–145. https://doi.org/10.1016/j.neunet.2022.02.013 doi: 10.1016/j.neunet.2022.02.013
|
| [52] | K. Gu, J. Chen, V. L. Kharitonov, Stability of Time-Delay Systems, Boston, MA: Birkhauser, 2003. https://doi.org/10.1007/978-1-4612-0039-0 |
| [53] |
K. Zhou and P. P. Khargonekar, Robust stabilization of linear systems with norm-bounded time-varying uncertainty, Syst. Contr. Lett., 10 (1988), 17–20. https://doi.org/10.1016/0167-6911(88)90034-5 doi: 10.1016/0167-6911(88)90034-5
|
| [54] | S. Boyd, L. E. Ghaoui, E. Feron, V. Balakrishnan, Linear Matrix Inequalities in System and Control Theory, Philadelphia, PA: SIAM, 1994. https://doi.org/10.1137/1.9781611970777 |




Figures(5) / Tables(1)

Wenjing Wang, Jingjing Dong, Dong Xu, Zhilian Yan, Jianping Zhou. Synchronization control of time-delay neural networks via event-triggered non-fragile cost-guaranteed control[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 52-75. doi: 10.3934/mbe.2023004







 DownLoad:
DownLoad: