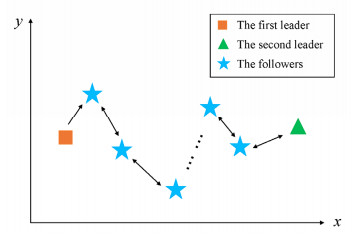
In this paper, the formation control problem of PDE-based multi-agent systems (MASs) is discussed. Firstly, the MASs are developed on a one-dimensional chain topology based on the polar coordinate system, and the dynamics of MASs is simulated using the spatial-varying coefficient wave equation. Secondly, a boundary control scheme is proposed by combining PDE-backstepping technique and the Volterra integral transformation. The well-posedness of kernel function is proved by using the iterative and inductive methods. Then, the stability of the closed-loop system is proved by using Lyapunov direct method. Finally, the PDE model is discretized using the finite difference method, and the distributed cooperative control protocol is obtained, in which the followers only need to know the location information of themselves and their neighbors. With this control protocol, leaders drive the MAS to stabilize in the desired formation. Both theoretical analysis and numerical simulation prove that the proposed control scheme is effective.
Citation: Sai Zhang, Li Tang, Yan-Jun Liu. Formation deployment control of multi-agent systems modeled with PDE[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 13541-13559. doi: 10.3934/mbe.2022632
In this paper, the formation control problem of PDE-based multi-agent systems (MASs) is discussed. Firstly, the MASs are developed on a one-dimensional chain topology based on the polar coordinate system, and the dynamics of MASs is simulated using the spatial-varying coefficient wave equation. Secondly, a boundary control scheme is proposed by combining PDE-backstepping technique and the Volterra integral transformation. The well-posedness of kernel function is proved by using the iterative and inductive methods. Then, the stability of the closed-loop system is proved by using Lyapunov direct method. Finally, the PDE model is discretized using the finite difference method, and the distributed cooperative control protocol is obtained, in which the followers only need to know the location information of themselves and their neighbors. With this control protocol, leaders drive the MAS to stabilize in the desired formation. Both theoretical analysis and numerical simulation prove that the proposed control scheme is effective.

| [1] |
Y. Liu, Y. M. Jia, An iterative learning approach to formation control of multi-agent systems, Syst. Control Lett., 61 (2012), 148-154. https://doi.org/10.1016/j.sysconle.2011.10.011 doi: 10.1016/j.sysconle.2011.10.011

|
| [2] |
R. Himo, M. Ogura, N. Wakamiya, Iterative shepherding control for agents with heterogeneous responsivity, Math. Biosci. Eng., 19 (2022), 3509-3525. https://doi.org/10.3934/mbe.2022162 doi: 10.3934/mbe.2022162
|
| [3] |
C. Wang, J. Li, H. D. Rao, A. W. Chen, J. Jiao, N. F. Zou, et al., Multi-objective grasshopper optimization algorithm based on multi-group and co-evolution, Math. Biosci. Eng., 18 (2021), 2527-2561. https://doi.org/10.3934/mbe.2021129 doi: 10.3934/mbe.2021129
|
| [4] |
Y. N. Chen, Z. Q. Zuo, Y. J. Wang, Bipartite consensus for a network of wave equations with time-varying disturbances, Syst. Control Lett., 136 (2020), 104604. https://doi.org/10.1016/j.sysconle.2019.104604 doi: 10.1016/j.sysconle.2019.104604
|
| [5] |
Y. N. Chen, Z. Q. Zuo, Y. J. Wang, Bipartite consensus for a network of wave PDEs over a signed directed graph, Automatica, 129 (2021), 109640. https://doi.org/10.1016/j.automatica.2021.109640 doi: 10.1016/j.automatica.2021.109640
|
| [6] |
T. Guo, J. Han, C. C. Zhou, J. P. Zhou, Multi-leader-follower group consensus of stochastic time-delay multi-agent systems subject to Markov switching topology, Math. Biosci. Eng., 19 (2022), 7504-7520. https://doi.org/10.3934/mbe.2022353 doi: 10.3934/mbe.2022353
|
| [7] |
S. Q. Zheng, P. Shi, S. Y. Wang, Y. Shi, Adaptive neural control for a class of nonlinear multiagent systems, IEEE Trans. Neural Netw. Learn. Syst., 32 (2020), 763-776. https://doi.org/10.1109/TNNLS.2020.2979266 doi: 10.1109/TNNLS.2020.2979266
|
| [8] |
Y. Wang, Z. S. Cheng, M. Xiao, UAVs' formation keeping control based on Multi-Agent system consensus, IEEE Access, 8 (2020), 49000-49012. https://doi.org/10.1109/ACCESS.2020.2979996 doi: 10.1109/ACCESS.2020.2979996
|
| [9] |
S. Kalantar, U. R. Zimmer, Distributed shape control of homogeneous swarms of autonomous underwater vehicles, Autonomous Robots, 22 (2007), 37-53. https://doi.org/10.1007/s10514-006-9002-y doi: 10.1007/s10514-006-9002-y
|
| [10] |
Z. Y. Lin, L. L. Wang, Z. M. Han, M. Y. Fu, Distributed formation control of multi-agent systems using complex Laplacian, IEEE Trans. Autom. Control, 59 (2014), 1765-1777. https://doi.org/10.1109/TAC.2014.2309031 doi: 10.1109/TAC.2014.2309031
|
| [11] |
L. W. Yang, L. X. Fu, P. Li, J. L. Mao, N. Guo, L. H. Du, LF-ACO: An effective formation path planning for multi-mobile robot, Math. Biosci. Eng., 19 (2022), 225-252. https://doi.org/10.3934/mbe.2022012 doi: 10.3934/mbe.2022012
|
| [12] |
X. W. Dong, G. Q. Hu, Time-varying formation control for general linear multi-agent systems with switching directed topologies, Automatica, 73 (2016), 47-55. https://doi.org/10.1016/j.automatica.2016.06.024 doi: 10.1016/j.automatica.2016.06.024
|
| [13] |
Z. Q. He, L. Yao, Improved successive approximation control for formation flying at libration points of solar-earth system, Math. Biosci. Eng., 18 (2021), 4084-4100. https://doi.org/10.3934/mbe.2021205 doi: 10.3934/mbe.2021205
|
| [14] |
T. Han, Z. H. Guan, M. Chi, B. Hu, T. Li, X. H. Zhang, Multi-formation control of nonlinear leader-following multi-agent systems, ISA Trans., 69 (2017), 140-147. https://doi.org/10.1016/j.isatra.2017.05.003 doi: 10.1016/j.isatra.2017.05.003
|
| [15] | P. Frihauf, M. Krstic, Multi-agent deployment to a family of planar arcs, in The 2010 American Control Conference. IEEE, (2010), 4109-4114. https://doi.org/10.1109/ACC.2010.5530623 |
| [16] | J. Q. Wei, E. Fridman, A. Selivanov, K. H. Johansson, Multi-agent deployment under the leader displacement measurement: a PDE-based approach, in The 18th European Control Conference, IEEE, (2019), 2424-2429. https://doi.org/10.23919/ECC.2019.8796132 |
| [17] |
Y. S. Zhou, N. L. Wu, H. D. Yuan, F. Pan, Z. Y. Shan, C. Wu, PDE formation and iterative docking control of USVs for the straight-line-shaped mission, J. Mar. Sci. Eng., 10 (2022), 478. https://doi.org/10.3390/jmse10040478 doi: 10.3390/jmse10040478
|
| [18] |
J. Kim, K. D. Kim, V. Natarajan, S. D. Kelly, J. Bentsman, PDE-based model reference adaptive control of uncertain heterogeneous multiagent networks, Nonlinear Anal. Hybr. Syst., 2 (2008), 1152-1167. https://doi.org/10.1016/j.nahs.2008.09.008 doi: 10.1016/j.nahs.2008.09.008
|
| [19] |
G. Freudenthaler, F. Göttsch, T. Meurer, Backstepping-based extended Luenberger observer design for a Burgers-type PDE for multi-agent deployment, in The 20th IFAC world congress, 50 (2017), 6780-6785. https://doi.org/10.1016/j.ifacol.2017.08.1196 doi: 10.1016/j.ifacol.2017.08.1196
|
| [20] |
P. Frihauf, M. Krstic, Leader-enabled deployment onto planar curves: A PDE-based approach, IEEE Trans. Autom. Control, 56 (2011), 1791-1806. https://doi.org/10.1109/TAC.2010.2092210 doi: 10.1109/TAC.2010.2092210
|
| [21] |
J. Qi, R. Vazquez, M. Krstic, Multi-agent deployment in 3-D via PDE Control, IEEE Trans. Autom. Control, 60 (2015), 891-906. https://doi.org/10.1109/TAC.2014.2361197 doi: 10.1109/TAC.2014.2361197
|
| [22] |
T. Meurer, M. Krstic, Finite-time multi-agent deployment: A nonlinear PDE motion planning approach, Automatica, 47 (2011), 2534-2542. https://doi.org/10.1016/j.automatica.2011.08.045 doi: 10.1016/j.automatica.2011.08.045
|
| [23] |
Z. J. Ji, Z. D. Wang, H. Lin, Z. Wang, Interconnection topologies for multi-agent coordination under leader-follower framework, Automatica, 45 (2009), 2857-2863. https://doi.org/10.1016/j.automatica.2009.09.002 doi: 10.1016/j.automatica.2009.09.002
|
| [24] |
S. El Ferik, M. T. Nasir, U. Baroudi, A behavioral adaptive fuzzy controller of multi robots in a cluster space, Appl. Soft Comput., 44 (2016), 117-127. https://doi.org/10.1016/j.asoc.2016.03.018 doi: 10.1016/j.asoc.2016.03.018
|
| [25] |
Q. Fu, L. L. Du, G. Z. Xu, J. R. Wu, Consensus control for multi-agent systems with distributed parameter models via iterative learning algorithm, J. Franklin Institute, 355 (2018), 4453-4472. https://doi.org/10.1016/j.jfranklin.2018.04.033 doi: 10.1016/j.jfranklin.2018.04.033
|
| [26] | S. Barawkar, Collaborative Transportation of A Common Payload Using Two UAVs Based on Force Feedback Control, MS thesis, University of Cincinnati, 2017. |
| [27] |
T. Meurer, M. Krstic, Nonlinear PDE-based motion planning for the formation control of mobile agents, IFAC Proc. Vol., 43 (2010), 599-604. https://doi.org/10.3182/20100901-3-IT-2016.00072 doi: 10.3182/20100901-3-IT-2016.00072
|
| [28] |
D. Aeyels, F. De Smet, Cluster formation in a time-varying multi-agent system, Automatica, 47 (2011), 2481-2487. https://doi.org/10.1016/j.automatica.2011.08.036 doi: 10.1016/j.automatica.2011.08.036
|
| [29] |
J. Qi, S. X. Tang, C. Wang, Parabolic PDE-based multi-agent formation control on a cylindrical surface, Int. J. Control, 92 (2017), 1-34. https://doi.org/10.1080/00207179.2017.1308556 doi: 10.1080/00207179.2017.1308556
|
| [30] |
J. Qi, S. S. Wang, J. A. Fang, Control of multi-agent systems with input delay via PDE-based method, Int. J. Control, 106 (2019), 91-100. https://doi.org/10.1016/j.automatica.2019.04.032 doi: 10.1016/j.automatica.2019.04.032
|
| [31] |
J. Qi, J. Zhang, Y. S. Ding, Wave equation-based time-varying formation control of multi-agent systems, IEEE Trans. Control Syst. Tech., 26 (2018), 1578-1591. https://doi.org/10.1109/TCST.2017.2742985 doi: 10.1109/TCST.2017.2742985
|
| [32] |
S. X. Tang, J. Qi, J. Zhang, Formation tracking control for multi-agent systems: A wave-equation based approach, Int. J. Control, Autom. Syst., 15 (2017), 2704-2713. https://doi.org/10.1007/s12555-016-0562-0 doi: 10.1007/s12555-016-0562-0
|
| [33] | G. Freudenthaler, T. Meurer, PDE-based multi-agent formation control using flatness and backstepping: Analysis, design and robot experiments, Automatica, 115 (2020), 108897. https://doi.org/10.1016/j.automatica.2020.108897 |
| [34] | X. D. Feng, Z. F. Zhang, Boundary stabilization of coupled wave system with spatially-varying coefficients and internal anti-damping, in The 39th Chinese Control Conference, (2020), 791-796. https://doi.org/10.23919/CCC50068.2020.9188546 |
| [35] |
A. Smyshlyaev, E. Cerpa, M. Krstic, Boundary stabilization of a 1-D wave equation with in-domain antidamping, SIAM J. Control Optim., 48 (2010), 4014-4031. https://doi.org/10.1137/080742646 doi: 10.1137/080742646
|




Figures(5)

Sai Zhang, Li Tang, Yan-Jun Liu. Formation deployment control of multi-agent systems modeled with PDE[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 13541-13559. doi: 10.3934/mbe.2022632







 DownLoad:
DownLoad: