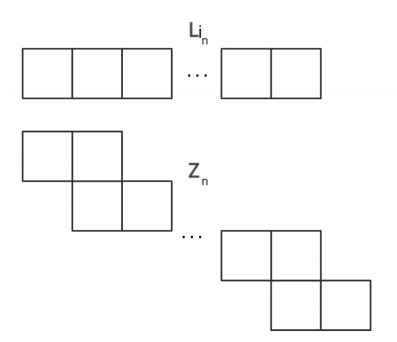
In this article, we study the degree-based topological indices in a random polyomino chain. The key purpose of this manuscript is to obtain the asymptotic distribution, expected value and variance for the degree-based topological indices in a random polyomino chain by using a martingale approach. Consequently, we compute the degree-based topological indices in a polyomino chain, hence some known results from the existing literature about polyomino chains are obtained as corollaries. Also, in order to apply the results, we obtain the expected value of several degree-based topological indices such as Sombor, Forgotten, Zagreb, atom-bond-connectivity, Randić and geometric-arithmetic index of a random polyomino chain.
Citation: Saylé C. Sigarreta, Saylí M. Sigarreta, Hugo Cruz-Suárez. On degree–based topological indices of random polyomino chains[J]. Mathematical Biosciences and Engineering, 2022, 19(9): 8760-8773. doi: 10.3934/mbe.2022406
In this article, we study the degree-based topological indices in a random polyomino chain. The key purpose of this manuscript is to obtain the asymptotic distribution, expected value and variance for the degree-based topological indices in a random polyomino chain by using a martingale approach. Consequently, we compute the degree-based topological indices in a polyomino chain, hence some known results from the existing literature about polyomino chains are obtained as corollaries. Also, in order to apply the results, we obtain the expected value of several degree-based topological indices such as Sombor, Forgotten, Zagreb, atom-bond-connectivity, Randić and geometric-arithmetic index of a random polyomino chain.

| [1] |
Z. Shao, A. Jahanbani, S. M. Sheikholeslami, Multiplicative topological indices of molecular structure in anticancer drugs, Polycycl. Aromat. Comp., 42 (2020), 475–488. https://doi.org/10.1080/10406638.2020.1743329 doi: 10.1080/10406638.2020.1743329

|
| [2] |
C. P. Li, C. Zhonglin, M. Munir, K. Yasmin, J. B. Liu, M-polynomials and topological indices of linear chains of benzene, napthalene and anthracene, Math. Biosci. Eng., 17 (2020), 2384–2398. https://10.3934/mbe.2020127 doi: 10.3934/mbe.2020127
|
| [3] |
A. Mehler, A. Lücking, P. Weiß, A network model of interpersonal alignment in dialog, Entropy, 12 (2010), 1440–1483. https://doi.org/10.3390/e12061440 doi: 10.3390/e12061440
|
| [4] |
J. J. Pineda-Pineda, C. T. Martínez-Martínez, J. A. Méndez-Bermúdez, J. Muñoz-Rojas, J. M. Sigarreta, Application of bipartite networks to the study of water quality, Sustainability, 12 (2020). https://doi.org/10.3390/su12125143 doi: 10.3390/su12125143
|
| [5] |
I. Gutman, Degree-based topological indices, Croat. Chem. Acta, 86 (2013), 351–361. http://dx.doi.org/10.5562/cca2294 doi: 10.5562/cca2294
|
| [6] |
B. Furtula, I. Gutman, A forgotten topological index, J. Math. Chem., 53 (2015), 1184–1190. https://doi.org/10.1007/s10910-015-0480-z doi: 10.1007/s10910-015-0480-z
|
| [7] |
W. Gao, W. Wang, M. K. Jamil, M. R. Farahani, Electron energy studying of molecular structures via forgotten topological index computation, J. Chem-NY, 2016 (2016), 1–7. https://doi.org/10.1155/2016/1053183 doi: 10.1155/2016/1053183
|
| [8] |
D. Vukičević, B. Furtula, Topological index based on the ratios of geometrical and arithmetical means of end-vertex degrees of edges, J. Math. Chem., 46 (2009), 1369–1376. https://doi.org/10.1007/s10910-009-9520-x doi: 10.1007/s10910-009-9520-x
|
| [9] | E. Estrada, L. Torres, L. Rodriguez, I. Gutman, An atom-bond connectivity index: modelling the enthalpy of formation of alkanes, Indian J. Chem. 37A (1998), 849–855. http://nopr.niscpr.res.in/handle/123456789/40308 |
| [10] | S. W. Golomb, Polyominoes, 2$^nd$ edition, Princeton University Press, 1994. http://doi.org/10.1515/9780691215051 |
| [11] | X. Zhou, H. Zhang, A minimax result for perfect matchings of a polyomino graph, Discret. Appl. Math., 06 (2016), 165–171. https://doi.org/10.1016/j.dam.2016.01.033 |
| [12] |
Y. Lin, F. Zhang, A linear algorithm for a perfect matching in polyomino graphs, Theor. Comput. Sci., 675 (2017), 82–88. https://doi.org/10.1016/j.tcs.2017.02.028 doi: 10.1016/j.tcs.2017.02.028
|
| [13] | A. Pegu, B. Deka, I. J. Gogoi, A. Bharali, Two generalized topological indices of some graph structures, J. Math. Comput. Sci., 11 (2021), 5549–5564. |
| [14] |
N. Iqbal, A. A. Bhatti, A. Ali, A. M. Alanazi, On bond incident connection indices of polyomino and benzenoid chains, Polycycl. Aromat. Comp., (2022), 1–8. https://doi.org/10.1080/10406638.2022.2035414 doi: 10.1080/10406638.2022.2035414
|
| [15] |
M. Cancan, M. Imran, S. Akhter, M. K. Siddiqui, M. F. Hanif, Computing forgotten topological index of extremal cactus chains, AMNS, 6 (2021), 439–446. https://doi.org/10.2478/amns.2020.2.00075 doi: 10.2478/amns.2020.2.00075
|
| [16] |
M. K. Jamil, S. Ahmed, M. I. Qureshi, A. Fahad, Zagreb connection index of drugs related chemical structures, Biointerface Res. Appl. Chem, 11 (2020), 11920–11930. https://doi.org/10.33263/briac114.1192011930 doi: 10.33263/briac114.1192011930
|
| [17] | A. Ali, B. Furtula, I. Gutman, D. Vukicevic, Augmented Zagreb index: extremal results and bounds, MATCH Commun. Math. Comput. Chem., 85 (2021), 211–244. |
| [18] | Z. Yarahmadi, Finding extremal total irregularity of polyomino chain by transformation method, J. New Res. Math., 7 (2021), 141–150. |
| [19] |
A. Ali, K. C. Das, D. Dimitrov, B. Furtula, Atom–bond connectivity index of graphs: a review over extremal results and bounds, Discrete Math. Lett., 5(2021), 68–93. https://doi.org/10.47443/dml.2020.0069 doi: 10.47443/dml.2020.0069
|
| [20] |
R. Cruz, J. Rada, Extremal polyomino chains of VDB topological indices, Appl. Math. Sci, 9 (2015), 5371–5388. http://dx.doi.org/10.12988/ams.2015.54368 doi: 10.12988/ams.2015.54368
|
| [21] |
J. Rada, The linear chain as an extremal value of VDB topological indices of polyomino chains, Appl. Math. Sci, 8 (2014), 5133–5143. http://dx.doi.org/10.12988/ams.2014.46507 doi: 10.12988/ams.2014.46507
|
| [22] | J. Rada, The zig-zag chain as an extremal value of VDB topological indices of polyomino chains, J. Combin. Math. Combin. Comput., 96 (2016), 103–111. |
| [23] |
T. Wu, H. Lü, X. Zhang, Extremal matching energy of random polyomino chains, Entropy, 19 (2017), 684. https://doi.org/10.3390/e19120684 doi: 10.3390/e19120684
|
| [24] |
S. Wei, W. C. Shiu, Enumeration of Wiener indices in random polygonal chains, J. Math. Anal. Appl., 469 (2019), 537–548. https://doi.org/10.1016/j.jmaa.2018.09.027 doi: 10.1016/j.jmaa.2018.09.027
|
| [25] |
C. Xiao, H. Chen, Dimer coverings on random polyomino chains, Z. Naturforsch. A, 70 (2015), 465–470. https://doi.org/10.1515/zna-2015-0121 doi: 10.1515/zna-2015-0121
|
| [26] |
S. Wei, X. Ke, F. Lin, Perfect matchings in random polyomino chain graphs, J. Math. Chem., 54 (2016), 690–697. https://doi.org/10.1007/s10910-015-0580-9 doi: 10.1007/s10910-015-0580-9
|
| [27] |
J. Li, W. Wang, The (degree-) Kirchhoff indices in random polygonal chains, Discret. Appl. Math., 304 (2021), 63–75. https://doi.org/10.1016/j.dam.2021.06.020 doi: 10.1016/j.dam.2021.06.020
|
| [28] |
T. Došlić, T. Réti, D. Vukičević, On the vertex degree indices of connected graphs, Chem. Phys. Lett., 512 (2011), 283–286. https://doi.org/10.1016/j.cplett.2011.07.040 doi: 10.1016/j.cplett.2011.07.040
|
| [29] | P. Hall, C. C. Heyde, Martingale limit theory and its Application, Academic press, New York, 2014. |
| [30] |
A. Ali, Z. Raza, A. A. Bhatti, Bond incident degree (BID) indices of polyomino chains: A unified approach, Appl. Math. Comput., 287 (2016), 28–37. https://doi.org/10.1016/j.amc.2016.04.012 doi: 10.1016/j.amc.2016.04.012
|
| [31] |
J. Buragohain, B. Deka, A. Bharali, A generalized ISI index of some chemical structures, J. Mol. Struct., 1208 (2020), 28–37. https://doi.org/10.1016/j.molstruc.2020.127843 doi: 10.1016/j.molstruc.2020.127843
|
| [32] |
Y. C. Kwun, A. Farooq, W. Nazeer, Z. Zahid, S. Noreen, S. M. Kang, Computations of the M-polynomials and degree-based topological indices for dendrimers and Polyomino Chains, Int. J. Anal. Chem., 2018 (2018). https://doi.org/10.1155/2018/1709073 doi: 10.1155/2018/1709073
|
| [33] |
A. Farooq, M. Habib, A. Mahboob, W. Nazeer, S. M. Kang, Zagreb polynomials and redefined Zagreb indices of dendrimers and Polyomino Chains, Open Chem., 17 (2019), 1374–1381. https://doi.org/10.1515/chem-2019-0144 doi: 10.1515/chem-2019-0144
|
| [34] | J. Yang, F. Xia, S. Chen, On sum-connectivity index of polyomino chains, Appl. Math. Sci, 5 (2011), 267–271. |
| [35] | J. Yang, F. Xia, S. Chen, On the Randić index of polyomino chains, Appl. Math. Sci, 5 (2011), 255–260. |
| [36] | W. Gao, L. Yan, L. Shi, Generalized Zagreb index of polyomino chains and nanotubes, Optoelectron. Adv. Mater. Rapid Commun., 11 (2017), 119–124. |
| [37] | S. Hayat, S. Ahmad, H. M. Umair, W. Shaohui, Distance property of chemical graphs, Hacettepe J. Math. Stat., 47 (2018), 1071–1093. |




Figures(5) / Tables(1)

Saylé C. Sigarreta, Saylí M. Sigarreta, Hugo Cruz-Suárez. On degree–based topological indices of random polyomino chains[J]. Mathematical Biosciences and Engineering, 2022, 19(9): 8760-8773. doi: 10.3934/mbe.2022406







 DownLoad:
DownLoad: