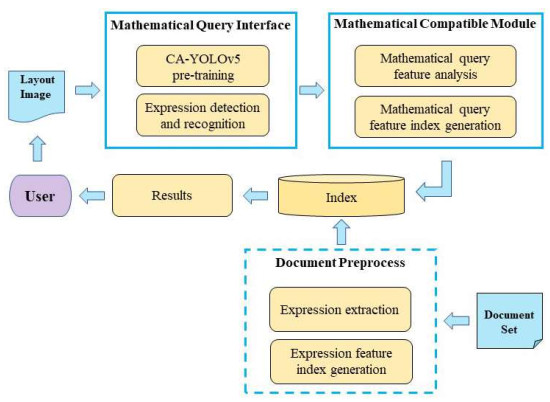
In a retrieval system for mathematical documents based on mathematical expressions, the input and matching of mathematical expressions are key steps that affect the system's usability, accessibility and efficiency because of their special attributes. Therefore, this paper mainly focuses on improving the input efficiency and matching accuracy of mathematical expressions. This paper proposes a method for retrieval and ranking of mathematical documents based on CA-YOLOv5 and HFS (hesitation fuzzy set) by utilizing the advantages of CA (coordinate attention) model and YOLOv5 in target detection and the superiority of HFS in multiattribute decision-making. By embedding the CA model into the YOLOv5 network, the mathematical expressions in layout images are extracted and recognized to form mathematical query expressions. These expressions are then analyzed to obtain similarity evaluation features and matched with the candidate mathematical expressions indexed with the same features in a library of mathematical documents by employing the HFS as the similarity evaluation measure. Experiments were performed based on the TFD-ICDAR2019v2 dataset and the NTCIR dataset. The F1-score of the mathematical expression detection result was 76.54%, the MAP (mean average precision) of the mathematical documents retrieval result was 71.73%, and the average nDCG of mathematical documents ranking was 80.89%.
Citation: Xinpeng Xu, Xuedong Tian, Fang Yang. A retrieval and ranking method of mathematical documents based on CA-YOLOv5 and HFS[J]. Mathematical Biosciences and Engineering, 2022, 19(5): 4976-4990. doi: 10.3934/mbe.2022233
In a retrieval system for mathematical documents based on mathematical expressions, the input and matching of mathematical expressions are key steps that affect the system's usability, accessibility and efficiency because of their special attributes. Therefore, this paper mainly focuses on improving the input efficiency and matching accuracy of mathematical expressions. This paper proposes a method for retrieval and ranking of mathematical documents based on CA-YOLOv5 and HFS (hesitation fuzzy set) by utilizing the advantages of CA (coordinate attention) model and YOLOv5 in target detection and the superiority of HFS in multiattribute decision-making. By embedding the CA model into the YOLOv5 network, the mathematical expressions in layout images are extracted and recognized to form mathematical query expressions. These expressions are then analyzed to obtain similarity evaluation features and matched with the candidate mathematical expressions indexed with the same features in a library of mathematical documents by employing the HFS as the similarity evaluation measure. Experiments were performed based on the TFD-ICDAR2019v2 dataset and the NTCIR dataset. The F1-score of the mathematical expression detection result was 76.54%, the MAP (mean average precision) of the mathematical documents retrieval result was 71.73%, and the average nDCG of mathematical documents ranking was 80.89%.

| [1] | W. Chu, F. Liu, Mathematical formula detection in heterogeneous document images, in 2013 Conference on Technologies and Applications of Artificial Intelligence, (2013), 140–145. https://doi.org/10.1109/TAAI.2013.38 |
| [2] | P. Mali, P. Kukkadapu, M. Mahdavi, R. Zanibbi, ScanSSD: Scanning single shot detector for mathematical formulas in PDF document images, preprint, arXiv: 200308005. |
| [3] |
W. Ohyama, M. Suzuki, S. Uchida, Detecting mathematical expressions in scientific document images using a U-Net trained on a diverse dataset, IEEE Access, 7 (2019), 144030–144042. https://doi.org/10.1109/ACCESS.2019.2945825 doi: 10.1109/ACCESS.2019.2945825

|
| [4] | B. H. Phong, L. T. Dat, N. T. Yen, T. M. Hoang, T. L. Le, A deep learning based system for mathematical expression detection and recognition in document images, in 12th International Conference on Knowledge and Systems Engineering, (2020), 85–90. https://doi.org/10.1109/KSE50997.2020.9287693 |
| [5] | B. H. Phong, T. M. Hoang, T. L. Le, Mathematical variable detection based on convolutional neural network and support vector machine, in 2019 International Conference on Multimedia Analysis and Pattern Recognition, (2019), 1–5. https://doi.org/10.1109/MAPR.2019.8743543 |
| [6] | X. Lin, L. Gao, Z. Tang, X. Lin, X. Hu, Mathematical formula identification in PDF documents, in 2011 International Conference on Document Analysis and Recognition, (2011), 1419–1423. https://doi.org/10.1109/ICDAR.2011.285 |
| [7] | X. Lin, L. Gao, Z. Tang, J. Baker, M. Alkalai, V. Sorge, A text line detection method for mathematical formula recognition, in 2013 12th International Conference on Document Analysis and Recognition, (2013), 339–343. https://doi.org/10.1109/ICDAR.2013.75 |
| [8] |
X. Lin, L. Gao, Z. Tang, J. Baker, V. Sorge, Mathematical formula identification and performance evaluation in PDF documents, Int. J. Doc. Anal. Recog., 17 (2013), 239–255. https://doi.org/10.1007/s10032-013-0216-1 doi: 10.1007/s10032-013-0216-1
|
| [9] | L. Gao, X. Yi, Y. Liao, Z. Jiang, Z. Yan, Z. Tang, A deep learning-based formula detection method for PDF documents, in 2017 14th IAPR International Conference on Document Analysis and Recognition, (2017), 553–558. https://doi.org/10.1109/ICDAR.2017.96 |
| [10] |
B. H. Phong, T. M. Hoang, T. L. Le, A. Aizawa, Mathematical variable detection in PDF scientific documents, Intell. Inform. Database Syst., 11432 (2019), 694–706. https://doi.org/10.1007/978-3-030-14802-7_60 doi: 10.1007/978-3-030-14802-7_60
|
| [11] |
B. H. Phong, T. M. Hoang, T. L. Le, A hybrid method for mathematical expression detection in scientific document images, IEEE Access, 8 (2020), 83663–83684. https://doi.org/10.1109/ACCESS.2020.2992067 doi: 10.1109/ACCESS.2020.2992067
|
| [12] |
R. Deveaud, J. Mothe, M. Z. Ullah, J. Y. Nie, Learning to adaptively rank document retrieval system configurations, ACM Trans. Inform. Syst., 37 (2019), 1–41. https://doi.org/10.1145/3231937 doi: 10.1145/3231937
|
| [13] | K. Yamada, H. Murakami, Mathematical expression retrieval in PDFs from the Web using mathematical term queries, in International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, 12144 (2020), 155–161. https://doi.org/10.1007/978-3-030-55789-8_14 |
| [14] | P. Sojka, M. Růžička, V. Novotný, MIaS: math-aware retrieval in digital mathematical libraries, in Proceedings of the 27th ACM International Conference on Information and Knowledge Management, (2018), 1923–1926. https://doi.org/10.1145/3269206.3269233 |
| [15] |
M. Schubotz, N. Meuschke, T. Hepp, H. S. Cohl, B. Gipp, VMEXT: a visualization tool for mathematical expression trees, Intell. Comput. Math., 10383 (2017), 340–355. https://doi.org/10.1007/978-3-319-62075-6 doi: 10.1007/978-3-319-62075-6
|
| [16] | M. Líška, P. Sojka, M. Růžička, Combining text and formula queries in math information retrieval, in Proceedings of the First International Workshop on Novel Web Search Interfaces and Systems, (2015), 7–9. https://doi.org/10.1145/2810355.2810359 |
| [17] |
W. Zhong, S. Rohatgi, J. Wu, C. L. Giles, R. Zanibbi, Accelerating substructure similarity search for formula retrieval, Adv. Inform. Retrieval, 12035 (2020), 714–727. https://doi.org/10.1007/978-3-030-45439-5 doi: 10.1007/978-3-030-45439-5
|
| [18] |
D. Stalnaker, R. Zanibbi, Math expression retrieval using an inverted index over symbol pairs, Int. Soc. Opt. Photonics, 9402 (2015), 940207. https://doi.org/10.1117/12.2074084 doi: 10.1117/12.2074084
|
| [19] |
X. Tian, J. Wang, Retrieval of scientific documents based on HFS and BERT, IEEE Access, 9 (2021), 8708–8717. https://doi.org/10.1109/ACCESS.2021.3049391 doi: 10.1109/ACCESS.2021.3049391
|
| [20] | S. Hussain, S. Khoja, Retrieval of mathematical information with syntactic and semantic structure over Web, J. Inform. Sci. Engineering, 36 (2020), 75–89. |
| [21] |
J. Xu, C. Xu, Computing similarity of Sci-Tech documents based on texts and formulas, Data Anal. Knowl. Discov., 2 (2018), 103–109. https://doi.org/10.11925/infotech.2096-3467.2018.0211 doi: 10.11925/infotech.2096-3467.2018.0211
|
| [22] |
A. Pathak, P. Pakray, R. Das, Context guided retrieval of math formulae from scientific documents, J. Inform. Optimization Sci., 40 (2019), 1559–1574. https://doi.org/10.1080/02522667.2019.1703255 doi: 10.1080/02522667.2019.1703255
|
| [23] | P. Scharpf, M. Schubotz, A. Youssef, F. Hamborg, N. Meuschke, B. Gipp, Classification and clustering of arXiv documents, sections, and abstracts, comparing encodings of natural and mathematical language, in Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020, (2020), 137–146. https://doi.org/10.1145/3383583.3398529 |
| [24] |
M. Schubotz, P. Scharpf, O. Teschke, A. Kühnemund, C. Breitinger, B. Gipp, AutoMSC: Automatic Assignment of Mathematics Subject Classification Labels, Int. Conf. Intell. Comput. Math., (2020), 237–250. https://doi.org/10.1007/978-3-030-53518-6_15 doi: 10.1007/978-3-030-53518-6_15
|
| [25] |
V. Torra, Hesitant fuzzy sets, Int. J. Intell. Syst., 25 (2010), 529–539. https://doi.org/10.1002/int.20418 doi: 10.1002/int.20418
|
| [26] | G. Jocher, K. Nishimura, T. Mineeva, R. Vilariño: YOLOv5, 2020. Available from: https://github.com/ultralytics/yolov5 |
| [27] | Q. Hou, D. Zhou, J. Feng, Coordinate attention for efficient mobile network design, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 13713–13722. https://doi.org/10.1109/CVPR46437.2021.01350 |
| [28] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 779–788. https://doi.org/10.1109/CVPR.2016.91 |
| [29] | X. Tian, A mathematical indexing method based on the hierarchical features of operators in formulae, Adv. Eng. Res., 119 (2017), 49–52. |
| [30] | M. Mahdavi, R. Zanibbi, H. Mouchere, C. Viard-Gaudin, U. Garain, ICDAR 2019 CROHME+ TFD: Competition on recognition of handwritten mathematical expressions and typeset formula detection, in 2019 International Conference on Document Analysis and Recognition, (2019), 1533–1538. https://doi.org/10.1109/ICDAR.2019.00247 |
| [31] |
C. Wang, Y. Yang, F. Deng, H. Lai, A review of text similarity approaches, Inform. Sci., 37 (2019), 1007–7634. https://doi.org/10.13833/j.issn.1007-7634.2019.03.026 doi: 10.13833/j.issn.1007-7634.2019.03.026
|








Figures(9) / Tables(3)

Xinpeng Xu, Xuedong Tian, Fang Yang. A retrieval and ranking method of mathematical documents based on CA-YOLOv5 and HFS[J]. Mathematical Biosciences and Engineering, 2022, 19(5): 4976-4990. doi: 10.3934/mbe.2022233







 DownLoad:
DownLoad: