Citation: Dailin Wang, Yunlei Lv, Danting Ren, Linhui Li. Research on massive information query and intelligent analysis method in a complex large-scale system[J]. Mathematical Biosciences and Engineering, 2019, 16(4): 2906-2926. doi: 10.3934/mbe.2019143

| [1] | B. Li, Y. Chen and S. Yu, Review of information extraction research, Comput. Eng. Appl., 10 (2003), 1–5+66. (in Chinese) |
| [2] | Y. Liu, R. Jin and J. Y. Chai, et al., A Maximum coherence model for dictionary-based cross-language information retrieval. Proceedings of the 28th Annual International ACMSIGIR Conference; 2005 August 15–19; Salvador, Brazil. New York: ACM; 536–543. |
| [3] | A. L. Berger, V. J. D. Pietra and S. A. D. Pietra, A maximum entropy approach to natural language processing, Comput. Linguist., 22 (1996), 39–71. |
| [4] | W. Huang and Y. Sun, Chinese short text sentiment analysis based on maximum entropy, Comput. Eng. Des., 38 (2017), 138–143. (in Chinese) |
| [5] | Y. Lin, Y. Liu and S. Zhou, Text information extraction based on maximum entropy of hidden Markov model, Acta Electronica Sinic, 33 (2005), 236–240. (in Chinese) |
| [6] | K. Seymore, A. Mccallum and R. Rosenfeld, Learning hidden Markov model structure for information extraction, In Aaai'99 Workshop Machine Learning for Information Extraction, (1999), 37–42. |
| [7] | C. Chi and Y. Zhang, Information extraction from chinese papers based on hidden Markov model, Adv. Mater. Res., 846 (2014), 1291–1294. |
| [8] | Y. Liu, Y. Lin and Z. Chen, Text information extraction based on hidden Markov model, J. Syst. Simulat., 16 (2004), 507–510. (in Chinese) |
| [9] | S. Zhe, Research and application of hidden Markov model in web page information extraction, Ph.D thesis, East China Normal University, 2016. (in Chinese) |
| [10] | S. Zhou, Y. Lin and Y. Wang, et al., Text information extraction based on clustered hidden Markov model, J. Syst. Simulat., 19 (2007), 4926–4931. |
| [11] | Q. Du, H. Wang and Z. Shao, et al., Research on the extraction method of literature metadata based on hybrid HMM, Comput. and Digit. Eng., 45 (2017), 101–106. (in Chinese) |
| [12] | F. Ciravegna and A. Lavelli, Learning Pinocchio: adaptive information extraction for real world applications, J. Nat. Lang. Eng., 10 (2004), 145–165. |
| [13] | W. Yu, G. Guan and M. Zhou, et al., CV information extraction based on two-level cascade text classification, J. Chinese Inform. Process. 20 (2006), 59–66. |
| [14] | K. Yu, G. Guan and M. Zhou, Resume information extraction with Cascaded Hybrid Model. Proceddings of the 43th Annual Meeting of the ACL; 2005 June; Ann Arbor, Michigan. Association for Computational Linguistics; 499–506. (in Chinese) |
| [15] | Q. Wang and F. Li, Wikipedia-based resume extraction of personal name information, Comput. Appl. Softw., 28 (2011), 170–174. (in Chinese) |
| [16] | N. Ren, Research on the extraction of character title information in large-scale real texts, Ph.D thesis, Beijing Language and Culture University, 2008. |
| [17] | N. Gu, W. Feng and X. Sun, et al., Chinese resume automatic analysis and recommendation algorithm, Comput. Eng. Appl., 53 (2017), 141–148+270. (in Chinese) |
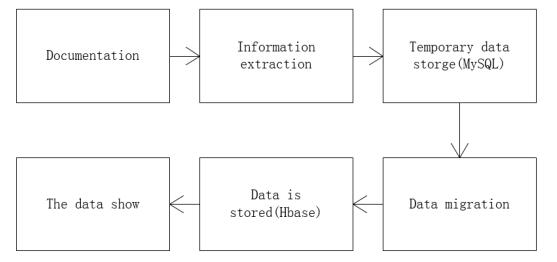
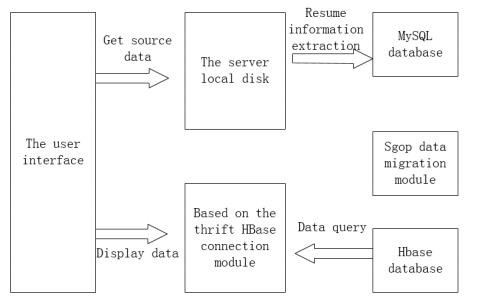
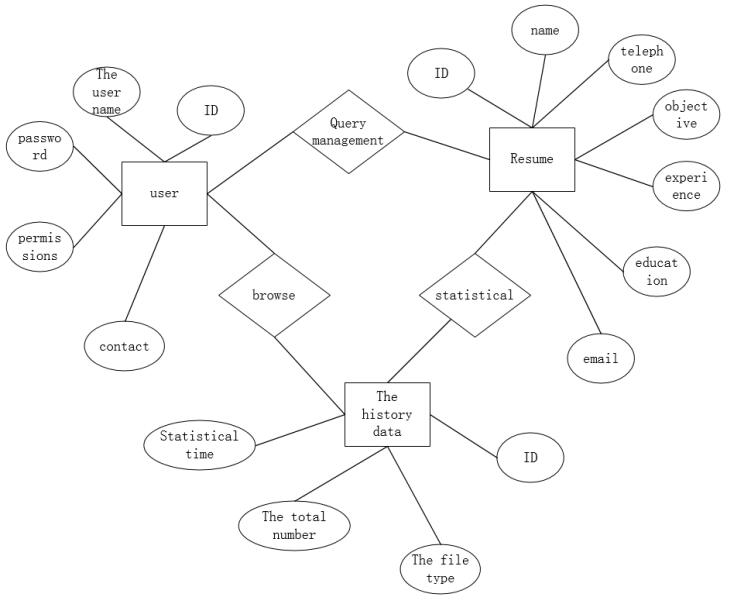
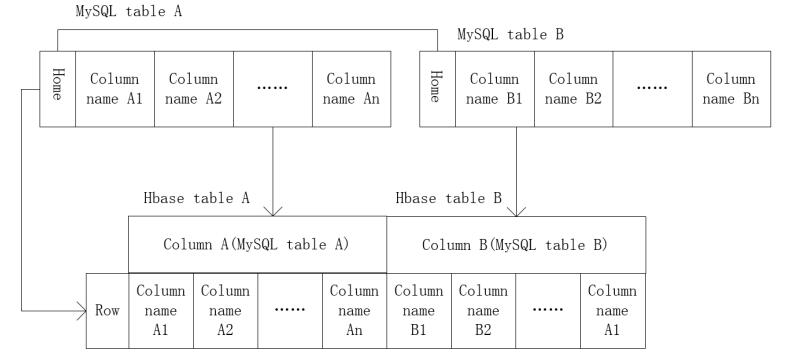
Figures(11) / Tables(4)

Dailin Wang, Yunlei Lv, Danting Ren, Linhui Li. Research on massive information query and intelligent analysis method in a complex large-scale system[J]. Mathematical Biosciences and Engineering, 2019, 16(4): 2906-2926. doi: 10.3934/mbe.2019143







 DownLoad:
DownLoad: