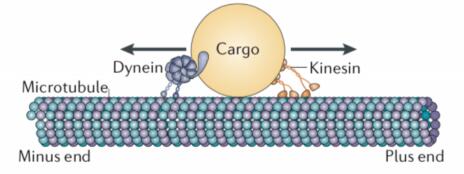
Intracellular transport by microtubule-based molecular motors is marked by qualitatively different behaviors. It is a long-standing and still-open challenge to accurately quantify the various individual-cargo behaviors and how they are affected by the presence or absence of particular motor families. In this work we introduce a protocol for analyzing change points in cargo trajectories that can be faithfully projected along the length of a (mostly) straight microtubule. Our protocol consists of automated identification of velocity change points, estimation of velocities during the behavior segments, and extrapolation to motor-specific velocity distributions. Using simulated data we show that our method compares favorably with existing methods. We then apply the technique to data sets in which quantum dots are transported by Kinesin-1, by Dynein-Dynactin-BicD2 (DDB), and by Kinesin-1/DDB pairs. In the end, we identify pausing behavior that is consistent with some tug-of-war model predictions, but also demonstrate that the simultaneous presence of antagonistic motors can lead to long processive runs that could contribute favorably to population-wide transport.
Citation: Melanie A. Jensen, Qingzhou Feng, William O. Hancock, Scott A. McKinley. A change point analysis protocol for comparing intracellular transport by different molecular motor combinations[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 8962-8996. doi: 10.3934/mbe.2021442
Intracellular transport by microtubule-based molecular motors is marked by qualitatively different behaviors. It is a long-standing and still-open challenge to accurately quantify the various individual-cargo behaviors and how they are affected by the presence or absence of particular motor families. In this work we introduce a protocol for analyzing change points in cargo trajectories that can be faithfully projected along the length of a (mostly) straight microtubule. Our protocol consists of automated identification of velocity change points, estimation of velocities during the behavior segments, and extrapolation to motor-specific velocity distributions. Using simulated data we show that our method compares favorably with existing methods. We then apply the technique to data sets in which quantum dots are transported by Kinesin-1, by Dynein-Dynactin-BicD2 (DDB), and by Kinesin-1/DDB pairs. In the end, we identify pausing behavior that is consistent with some tug-of-war model predictions, but also demonstrate that the simultaneous presence of antagonistic motors can lead to long processive runs that could contribute favorably to population-wide transport.

| [1] |
S. Klumpp, R. Lipowsky, Cooperative cargo transport by several molecular motors, Proc. Natl. Acad. Sci. U. S. A., 102 (2005), 17284–17289. doi: 10.1073/pnas.0507363102

|
| [2] |
M. J. Müller, S. Klumpp, R. Lipowsky, Bidirectional transport by molecular motors: Enhanced processivity and response to external forces, Biophys. J., 98 (2010), 2610–2618. doi: 10.1016/j.bpj.2010.02.037
|
| [3] |
A. Kunwar, A. Mogilner, Robust transport by multiple motors with nonlinear force–velocity relations and stochastic load sharing, Phys. Biol., 7 (2010), 016012. doi: 10.1088/1478-3975/7/1/016012
|
| [4] |
J. J. Klobusicky, J. Fricks, P. R. Kramer, Effective behavior of cooperative and nonidentical molecular motors, Res. Math. Sci., 7 (2020), 1–49. doi: 10.1007/s40687-019-0200-6
|
| [5] |
F. Berger, C. Keller, S. Klumpp, R. Lipowsky, Distinct transport regimes for two elastically coupled molecular motors, Phys. Rev. Lett., 108 (2012), 208101. doi: 10.1103/PhysRevLett.108.208101
|
| [6] |
S. A. McKinley, A. Athreya, J. Fricks, P. R. Kramer, Asymptotic analysis of microtubule-based transport by multiple identical molecular motors, J. Theor. Biol., 305 (2012), 54–69. doi: 10.1016/j.jtbi.2012.03.035
|
| [7] |
J. D. Smith, S. A. McKinley, Assessing the impact of electrostatic drag on processive molecular motor transport, Bull. Math. Biol, 80 (2018), 2088–2123. doi: 10.1007/s11538-018-0448-9
|
| [8] |
G. Arpağ, S. R. Norris, S. I. Mousavi, V. Soppina, K. J. Verhey, W. O. Hancock, et al., Motor dynamics underlying cargo transport by pairs of kinesin-1 and kinesin-3 motors, Biophys. J., 116 (2019), 1115–1126. doi: 10.1016/j.bpj.2019.01.036
|
| [9] |
S. E. Encalada, L. Szpankowski, C.-h. Xia, L. S. Goldstein, Stable kinesin and dynein assemblies drive the axonal transport of mammalian prion protein vesicles, Cell, 144 (2011), 551–565. doi: 10.1016/j.cell.2011.01.021
|
| [10] | W. O. Hancock, Bidirectional cargo transport: Moving beyond tug of war, Nat. Rev. Mol. Cell Biol., 15 (2014), 615. |
| [11] |
M. J. Müller, S. Klumpp, R. Lipowsky, Tug-of-war as a cooperative mechanism for bidirectional cargo transport by molecular motors, Proc. Natl. Acad. Sci. U. S. A., 105 (2008), 4609–4614. doi: 10.1073/pnas.0706825105
|
| [12] |
K. M. Trybus, Intracellular transport: The causes for pauses, Curr. Biol., 23 (2013), R623–R625. doi: 10.1016/j.cub.2013.06.005
|
| [13] |
A. Kunwar, S. K. Tripathy, J. Xu, M. K. Mattson, P. Anand, R. Sigua, et al., Mechanical stochastic tug-of-war models cannot explain bidirectional lipid-droplet transport, Proc. Natl. Acad. Sci. U. S. A., 108 (2011), 18960–18965. doi: 10.1073/pnas.1107841108
|
| [14] |
K. G. Ohashi, L. Han, B. Mentley, J. Wang, J. Fricks, W. O. Hancock, Load-dependent detachment kinetics plays a key role in bidirectional cargo transport by kinesin and dynein, Traffic, 20 (2019), 284–294. doi: 10.1111/tra.12639
|
| [15] |
S. M. Block, L. S. Goldstein, B. J. Schnapp, Bead movement by single kinesin molecules studied with optical tweezers, Nature, 348 (1990), 348. doi: 10.1038/348348a0
|
| [16] |
M. A. Welte, S. P. Gross, M. Postner, S. M. Block, E. F. Wieschaus, Developmental regulation of vesicle transport in drosophila embryos: forces and kinetics, Cell, 92 (1998), 547–557. doi: 10.1016/S0092-8674(00)80947-2
|
| [17] |
T. L. Fallesen, J. C. Macosko, G. Holzwarth, Force–velocity relationship for multiple kinesin motors pulling a magnetic bead, Eur. Biophys. J., 40 (2011), 1071–1079. doi: 10.1007/s00249-011-0724-1
|
| [18] |
N. D. Derr, B. S. Goodman, R. Jungmann, A. E. Leschziner, W. M. Shih, S. L. Reck-Peterson, Tug-of-war in motor protein ensembles revealed with a programmable dna origami scaffold, Science, 338 (2012), 662–665. doi: 10.1126/science.1226734
|
| [19] |
V. Belyy, M. A. Schlager, H. Foster, A. E. Reimer, A. P. Carter, A. Yildiz, The mammalian dynein–dynactin complex is a strong opponent to kinesin in a tug-of-war competition, Nat. Cell Biol., 18 (2016), 1018. doi: 10.1038/ncb3393
|
| [20] |
Q. Feng, K. J. Mickolajczyk, G.-Y. Chen, W. O. Hancock, Motor reattachment kinetics play a dominant role in multimotor-driven cargo transport, Biophys. J., 114 (2018), 400–409. doi: 10.1016/j.bpj.2017.11.016
|
| [21] |
Q. Feng, A. M. Gicking, W. O. Hancock, Dynactin p150 promotes processive motility of ddb complexes by minimizing diffusional behavior of dynein, Mol. Biol. Cell, 31 (2020), 782–792. doi: 10.1091/mbc.E19-09-0495
|
| [22] |
S. Neumann, R. Chassefeyre, G. E. Campbell, S. E. Encalada, Kymoanalyzer: A software tool for the quantitative analysis of intracellular transport in neurons, Traffic, 18 (2017), 71–88. doi: 10.1111/tra.12456
|
| [23] |
E. S. Page, Continuous inspection schemes, Biometrika, 41 (1954), 100–115. doi: 10.1093/biomet/41.1-2.100
|
| [24] |
E. S. Page, A test for a change in a parameter occurring at an unknown point, Biometrika, 42 (1955), 523–527. doi: 10.1093/biomet/42.3-4.523
|
| [25] |
E. S. Page, On problems in which a change in a parameter occurs at an unknown point, Biometrika, 44 (1957), 248–252. doi: 10.1093/biomet/44.1-2.248
|
| [26] |
H. Chernoff, S. Zacks, Estimating the current mean of a normal distribution which is subjected to changes in time, Ann. Math. Stat., 35 (1964), 999–1018. doi: 10.1214/aoms/1177700517
|
| [27] | J. Bai, P. Perron, Estimating and testing linear models with multiple structural changes, Econometrica, 47–78. |
| [28] |
J. Bai, P. Perron, Computation and analysis of multiple structural change models, J. Appl. Econ., 18 (2003), 1–22. doi: 10.1002/jae.659
|
| [29] | D. Barry, J. A. Hartigan, Product partition models for change point problems, Ann. Stat., 260–279. |
| [30] | D. Barry, J. A. Hartigan, A bayesian analysis for change point problems, J. Am. Stat. Assoc., 88 (1993), 309–319. |
| [31] | C. Erdman, J. W. Emerson, bcp: An R package for performing a Bayesian analysis of change point problems, J. Stat. Softw., 23. |
| [32] |
S. Yin, N. Song, H. Yang, Detection of velocity and diffusion coefficient change points in single-particle trajectories, Biophys. J., 115 (2018), 217–229. doi: 10.1016/j.bpj.2017.11.008
|
| [33] | M. Csorgo, L. Horváth, Limit theorems in change-point analysis, John Wiley & Sons Chichester, 1997. |
| [34] |
W. Hua, E. C. Young, M. L. Fleming, J. Gelles, Coupling of kinesin steps to ATP hydrolysis, Nature, 388 (1997), 390. doi: 10.1038/41118
|
| [35] |
M. J. Schnitzer, S. M. Block, Kinesin hydrolyses one ATP per 8-nm step, Nature, 388 (1997), 386. doi: 10.1038/41111
|
| [36] |
K. Visscher, M. J. Schnitzer, S. M. Block, Single kinesin molecules studied with a molecular force clamp, Nature, 400 (1999), 184. doi: 10.1038/22146
|
| [37] |
K. Svoboda, C. F. Schmidt, B. J. Schnapp, S. M. Block, Direct observation of kinesin stepping by optical trapping interferometry, Nature, 365 (1993), 721. doi: 10.1038/365721a0
|
| [38] | J. O. L. Andreasson, Single-molecule biophysics of kinesin family motor proteins, PhD thesis, Stanford University, 2013. |
| [39] |
R. J. McKenney, W. Huynh, M. E. Tanenbaum, G. Bhabha, R. D. Vale, Activation of cytoplasmic dynein motility by dynactin-cargo adapter complexes, Science, 345 (2014), 337–341. doi: 10.1126/science.1254198
|
| [40] | T. G. Kurtz, Approximation of Population Processes, SIAM, 1981. |
| [41] |
M. Lavielle, Optimal segmentation of random processes, IEEE Trans. Signal Process., 46 (1998), 1365–1373. doi: 10.1109/78.668798
|
| [42] | R. E. Kass, B. P. Carlin, A. Gelman, R. M. Neal, Markov chain Monte Carlo in practice: A roundtable discussion, Am. Stat., 52 (1998), 93–100. |
| [43] |
M. Lavielle, E. Lebarbier, An application of MCMC methods for the multiple change-points problem, Signal Processing, 81 (2001), 39–53. doi: 10.1016/S0165-1684(00)00189-4
|
| [44] |
P. J. Green, Reversible jump Markov chain Monte Carlo computation and Bayesian model determination, Biometrika, 82 (1995), 711–732. doi: 10.1093/biomet/82.4.711
|
| [45] | B. P. Carlin, A. E. Gelfand, A. F. Smith, Hierarchical Bayesian analysis of changepoint problems, Appl. Stat., 389–405. |
| [46] | D. Stephens, Bayesian retrospective multiple-changepoint identification, Appl. Stat., 159–178. |
| [47] | A. Gelman, H. S. Stern, J. B. Carlin, D. B. Dunson, A. Vehtari, D. B. Rubin, Bayesian Data Analysis, Chapman and Hall/CRC, 2013. |
| [48] |
R. E. Kass, A. E. Raftery, Bayes factors, J. Am. Stat. Assoc., 90 (1995), 773–795. doi: 10.1080/01621459.1995.10476572
|
| [49] | Y.-C. Yao, Estimation of a noisy discrete-time step function: Bayes and empirical Bayes approaches, Ann. Stat., 1434–1447. |
 mbe-18-06-442 supplementary.zip mbe-18-06-442 supplementary.zip |
 |







Figures(8) / Tables(6)

Melanie A. Jensen, Qingzhou Feng, William O. Hancock, Scott A. McKinley. A change point analysis protocol for comparing intracellular transport by different molecular motor combinations[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 8962-8996. doi: 10.3934/mbe.2021442







 DownLoad:
DownLoad: