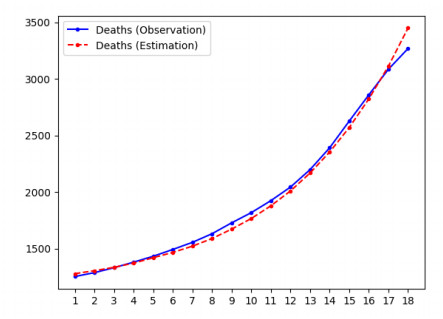
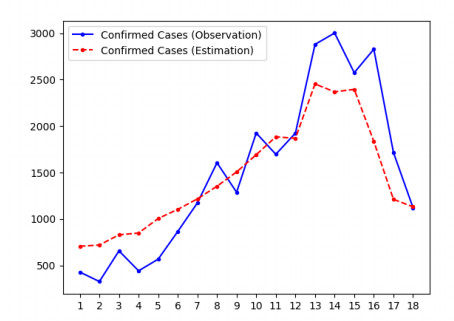
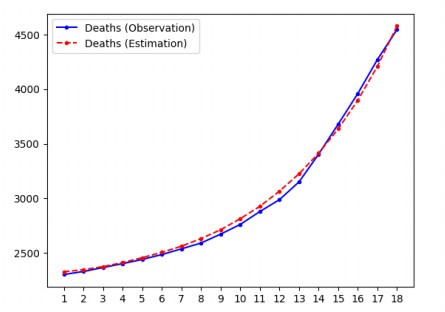
Mathematical models are widely recognized as an important tool for analyzing and understanding the dynamics of infectious disease outbreaks, predict their future trends, and evaluate public health intervention measures for disease control and elimination. We propose a novel stochastic metapopulation state-space model for COVID-19 transmission, which is based on a discrete-time spatio-temporal susceptible, exposed, infected, recovered, and deceased (SEIRD) model. The proposed framework allows the hidden SEIRD states and unknown transmission parameters to be estimated from noisy, incomplete time series of reported epidemiological data, by application of unscented Kalman filtering (UKF), maximum-likelihood adaptive filtering, and metaheuristic optimization. Experiments using both synthetic data and real data from the Fall 2020 COVID-19 wave in the state of Texas demonstrate the effectiveness of the proposed model.
Citation: Yukun Tan, Durward Cator III, Martial Ndeffo-Mbah, Ulisses Braga-Neto. A stochastic metapopulation state-space approach to modeling and estimating COVID-19 spread[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 7685-7710. doi: 10.3934/mbe.2021381
Mathematical models are widely recognized as an important tool for analyzing and understanding the dynamics of infectious disease outbreaks, predict their future trends, and evaluate public health intervention measures for disease control and elimination. We propose a novel stochastic metapopulation state-space model for COVID-19 transmission, which is based on a discrete-time spatio-temporal susceptible, exposed, infected, recovered, and deceased (SEIRD) model. The proposed framework allows the hidden SEIRD states and unknown transmission parameters to be estimated from noisy, incomplete time series of reported epidemiological data, by application of unscented Kalman filtering (UKF), maximum-likelihood adaptive filtering, and metaheuristic optimization. Experiments using both synthetic data and real data from the Fall 2020 COVID-19 wave in the state of Texas demonstrate the effectiveness of the proposed model.

| [1] |
M. L. C. Degli Atti, S. Merler, C. Rizzo, M. Ajelli, M. Massari, P. Manfredi, et al., Mitigation measures for pandemic influenza in italy: an individual based model considering different scenarios, PloS one, 3 (2008), e1790. doi: 10.1371/journal.pone.0001790

|
| [2] |
L. Perez, S. Dragicevic, An agent-based approach for modeling dynamics of contagious disease spread, Int. J. Health Geogr., 8 (2009), 1–17. doi: 10.1186/1476-072X-8-1
|
| [3] |
E. Hunter, B. Mac Namee, J. Kelleher, An open-data-driven agent-based model to simulate infectious disease outbreaks, PloS One, 13 (2018), e0208775. doi: 10.1371/journal.pone.0208775
|
| [4] |
S. L. Chang, N. Harding, C. Zachreson, O. M. Cliff, M. Prokopenko, Modelling transmission and control of the COVID-19 pandemic in australia, Nat. Commun., 11 (2020), 1–13. doi: 10.5455/njcm.20200319050247
|
| [5] | D. L. Chao, A. P. Oron, D. Srikrishna, M. Famulare, Modeling layered non-pharmaceutical interventions against sars-cov-2 in the united states with corvid, medRxiv, 2020. |
| [6] |
J. R. Koo, A. R. Cook, M. Park, Y. Sun, H. Sun, J. T. Lim, et al., Interventions to mitigate early spread of sars-cov-2 in singapore: a modelling study, Lancet Infect. Dis., 20 (2020), 678–688. doi: 10.1016/S1473-3099(20)30162-6
|
| [7] | M. Kretzschmar, G. Rozhnova, M. van Boven, Isolation and contact tracing can tip the scale to containment of covid-19 in populations with social distancing, Available at SSRN 3562458, 2020. |
| [8] | C. C. Kerr, R. M. Stuart, D. Mistry, R. G. Abeysuriya, G. Hart, K. Rosenfeld, et al., Covasim: an agent-based model of COVID-19 dynamics and interventions, medRxiv, 2020. |
| [9] |
D. Balcan, B. Goncontcalves, H. Hu, J. J. Ramasco, V. Colizza, A. Vespignani, Modeling the spatial spread of infectious diseases: The global epidemic and mobility computational model, J. Comput. Sci, 1 (2010), 132–145. doi: 10.1016/j.jocs.2010.07.002
|
| [10] | V. Dukic, H. F. Lopes, N. G. Polson, Tracking epidemics with state-space seir and google flu trends, Unpublished manuscript, 2012. |
| [11] | D. Osthus, K. S. Hickmann, P. C. Caragea, D. Higdon, S. Y. Del Valle, Forecasting seasonal influenza with a state-space sir model, Ann. Appl. Stat., 11 (2017), 202. |
| [12] | E. Sebastian, P. Victor, A state space approach for sir epidemic model, Int. J. Differ. Equ., 12 (2017), 79–87. |
| [13] | M. J. Keeling, T. D. Hollingsworth, J. M. Read, Efficacy of contact tracing for the containment of the 2019 novel coronavirus (COVID-19), J. Epidemiol. Community Health, 74 (2020), 861–866. |
| [14] | R. Sameni, Mathematical modeling of epidemic diseases; a case study of the COVID-19 coronavirus, arXiv preprint arXiv: 2003.11371, 2020. |
| [15] |
A. Godio, F. Pace, A. Vergnano, Seir modeling of the italian epidemic of sars-cov-2 using computational swarm intelligence, Int. J. Environ. Res. Publ. Health., 17 (2020), 3535. doi: 10.3390/ijerph17103535
|
| [16] | G. Kobayashi, S. Sugasawa, H. Tamae, T. Ozu, Predicting intervention effect for COVID-19 in japan: state space modeling approach, BioScience Trends, 2020. |
| [17] | W. O. Kermack, A. G. McKendrick, A contribution to the mathematical theory of epidemics, Proc. Math. Phys. Eng. Sci., 115 (1927), 700–721. |
| [18] |
G. Hooker, S. P. Ellner, L. D. V. Roditi, D. J. Earn, Parameterizing state–space models for infectious disease dynamics by generalized profiling: measles in ontario, J. R. Soc. Interface, 8 (2011), 961–974. doi: 10.1098/rsif.2010.0412
|
| [19] |
S. Zhong, Q. Huang, D. Song, Simulation of the spread of infectious diseases in a geographical environment, Sci. China Earth Sci., 52 (2009), 550–561. doi: 10.1007/s11430-009-0044-9
|
| [20] |
G. Albi, L. Pareschi, M. Zanella, Control with uncertain data of socially structured compartmental epidemic models, J. Math. Biol., 82 (2021), 1–41. doi: 10.1007/s00285-021-01560-y
|
| [21] | G. Bertaglia, L. Pareschi, Hyperbolic compartmental models for epidemic spread on networks with uncertain data: application to the emergence of COVID-19 in italy, arXiv preprint arXiv: 2105.14258, 2021. |
| [22] | G. Bertaglia, W. Boscheri, G. Dimarco, L. Pareschi, Spatial spread of COVID-19 outbreak in italy using multiscale kinetic transport equations with uncertainty, arXiv preprint arXiv: 2106.07262, 2021. |
| [23] | W. Boscheri, G. Dimarco, L. Pareschi, Modeling and simulating the spatial spread of an epidemic through multiscale kinetic transport equations, Math. Mod. Methods Appl. Sci., (2021), 1–39. |
| [24] | T. Rapolu, B. Nutakki, T. S. Rani, S. D. Bhavani, A time-dependent seird model for forecasting the COVID-19 transmission dynamics, medRxiv, 2020. |
| [25] |
E. Loli Piccolomini, F. Zama, Monitoring italian COVID-19 spread by a forced seird model, PloS One, 15 (2020), e0237417. doi: 10.1371/journal.pone.0237417
|
| [26] |
I. Korolev, Identification and estimation of the seird epidemic model for COVID-19, J. Econom., 220 (2021), 63–85. doi: 10.1016/j.jeconom.2020.07.038
|
| [27] | V. Tiwari, N. Bisht, N. Deyal, Mathematical modelling based study and prediction of COVID-19 epidemic dissemination under the impact of lockdown in india, medRxiv, 2020. |
| [28] |
G. K. Zipf, The p 1 p 2/d hypothesis: on the intercity movement of persons, Am. sociol. Rev., 11 (1946), 677–686. doi: 10.2307/2087063
|
| [29] |
J. Truscott, N. M. Ferguson, Evaluating the adequacy of gravity models as a description of human mobility for epidemic modelling, PLoS Comput. Biol., 8 (2012), e1002699. doi: 10.1371/journal.pcbi.1002699
|
| [30] |
Q. Chen, J. Yan, H. Huang, X. Zhang, Correlation of the epidemic spread of COVID-19 and urban population migration in the major cities of hubei province, china, Transp. Safety Environ., 3 (2021), 21–35. doi: 10.1093/tse/tdaa033
|
| [31] |
W. E. Allen, H. Altae-Tran, J. Briggs, X. Jin, G. McGee, A. Shi, et al., Population-scale longitudinal mapping of COVID-19 symptoms, behaviour and testing, Nat. Hum. Behav., 4 (2020), 972–982. doi: 10.1038/s41562-020-00944-2
|
| [32] |
D. Buitrago-Garcia, D. Egli-Gany, M. J. Counotte, S. Hossmann, H. Imeri, A. M. Ipekci, et al., Occurrence and transmission potential of asymptomatic and presymptomatic sars-cov-2 infections: A living systematic review and meta-analysis, PLoS Med., 17 (2020), e1003346. doi: 10.1371/journal.pmed.1003346
|
| [33] | E. A. Wan, R. Van Der Merwe, The unscented kalman filter for nonlinear estimation, in Proc. IEEE 2000 Adaptive Syst. Signal Process., Commun. Control Symposium (Cat. No. 00EX373), Ieee, 2000,153–158. |
| [34] | C. J. Bastos Filho, F. B. de Lima Neto, A. J. Lins, A. I. Nascimento, M. P. Lima, A novel search algorithm based on fish school behavior, in Systems, Man and Cybernetics, 2008. SMC 2008. IEEE International Conference on, IEEE, 2008, 2646–2651. |
| [35] | C. Bastos-Filho, D. Nascimento, An enhanced fish school search algorithm, in Computational Intelligence and 11th Brazilian Congress on Computational Intelligence (BRICS-CCI & CBIC), 2013 BRICS Congress on, IEEE, 2013,152–157. |
| [36] | Y. Tan, F. L. Neto, U. Braga-Neto, Pallas: Penalized maximum likelihood and particle swarms for inference of gene regulatory networks from time series data, IEEE/ACM Transactions on Computational Biology and Bioinformatics, 2020. |
| [37] | D. Simon, Optimal state estimation: Kalman, H infinity, and nonlinear approaches, John Wiley & Sons, 2006. |
| [38] | S. Särkkä, Bayesian filtering and smoothing, Number 3, Cambridge University Press, 2013. |
| [39] |
K. Ito, K. Xiong, Gaussian filters for nonlinear filtering problems, IEEE Trans. Automat. Contr., 45 (2000), 910–927. doi: 10.1109/9.855552
|
| [40] |
Y. Wu, D. Hu, M. Wu, X. Hu, A numerical-integration perspective on gaussian filters, IEEE Trans. Signal Process., 54 (2006), 2910–2921. doi: 10.1109/TSP.2006.875389
|
| [41] | J. Kokkala, A. Solin, S. Särkkä, Sigma-point filtering and smoothing based parameter estimation in nonlinear dynamic systems, arXiv preprint arXiv: 1504.06173, 2015. |
| [42] |
A. R. Yıldız, A novel particle swarm optimization approach for product design and manufacturing, Int. J. Adv. Manuf. Technol., 40 (2009), 617–628. doi: 10.1007/s00170-008-1453-1
|
| [43] |
I. Mukherjee, P. K. Ray, A review of optimization techniques in metal cutting processes, Comput. Ind. Eng., 50 (2006), 15–34. doi: 10.1016/j.cie.2005.10.001
|
| [44] | M. Madić, D. Marković, M. Radovanović, Comparison of meta-heuristic algorithms for solving machining optimization problems, Facta universitatis-series: Mech. Eng., 11 (2013), 29–44. |
| [45] | T. Asai, COVID-19: accurate interpretation of diagnostic tests–-a statistical point of view, 2020. |
| [46] | Centers for Disease Control and Prevention, Interim clinical guidance for management of patients with confirmed coronavirus disease (COVID-19), https://www.cdc.gov/coronavirus/2019-ncov/hcp/clinical-guidance-management-patients.html, 2021, (accessed 22-July-2021). |
| [47] | Centers for Disease Control and Prevention, Interim guidance on ending isolation and precautions for adults with COVID-19, https://www.cdc.gov/coronavirus/2019-ncov/hcp/duration-isolation.html, 2021, (accessed 22-July-2021). |
| [48] | World Health Organization. Estimating mortality from COVID-19, https://www.who.int/news-room/commentaries/detail/estimating-mortality-from-covid-19, 2020, (accessed 22-July-2021). |
| [49] |
C. Fraser, S. Riley, R. M. Anderson, N. M. Ferguson, Factors that make an infectious disease outbreak controllable, Proc. Natl. Acad. Sci. U.S.A., 101 (2004), 6146–6151. doi: 10.1073/pnas.0307506101
|
| [50] |
J. Hellewell, S. Abbott, A. Gimma, N. I. Bosse, C. I. Jarvis, T. W. Russell, et al., Feasibility of controlling COVID-19 outbreaks by isolation of cases and contacts, Lancet Glob. Health, 8 (2020), e488–e496. doi: 10.1016/S2214-109X(20)30074-7
|
| [51] |
M. U. Kraemer, C.-H. Yang, B. Gutierrez, C.-H. Wu, B. Klein, D. M. Pigott, et al., The effect of human mobility and control measures on the COVID-19 epidemic in china, Science, 368 (2020), 493–497. doi: 10.1126/science.abb4218
|
| [52] |
E. Dong, H. Du, L. Gardner, An interactive web-based dashboard to track COVID-19 in real time, Lancet Infect. Dis., 20 (2020), 533–534. doi: 10.1016/S1473-3099(20)30120-1
|
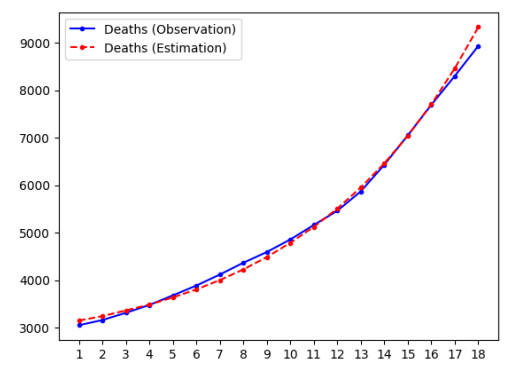
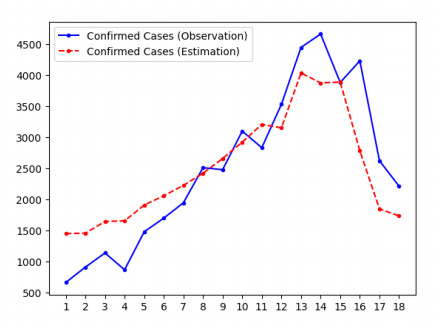
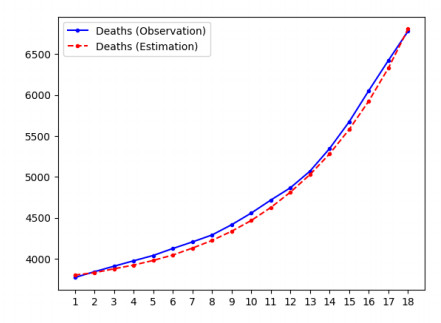
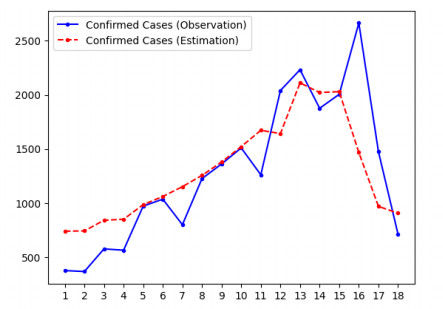
Figures(11) / Tables(5)

Yukun Tan, Durward Cator III, Martial Ndeffo-Mbah, Ulisses Braga-Neto. A stochastic metapopulation state-space approach to modeling and estimating COVID-19 spread[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 7685-7710. doi: 10.3934/mbe.2021381







 DownLoad:
DownLoad: