Citation: Xuguo Yan, Liang Gao. A feature extraction and classification algorithm based on improved sparse auto-encoder for round steel surface defects[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5369-5394. doi: 10.3934/mbe.2020290

| [1] | B. Wu, T. Xue, T. Zhang, S. H. Ye, A novel method for round steel measurement with a multi-line structure light vision sensor, Meas. Sci. Technol., 21 (2010), 283-293. |
| [2] | C. I. Brannan, M. A. Bedell, J. L. Resnick, J. J. Eppig, M. A. Handel, D. E. Williams, et al., Developmental abnormalities in Steel17H mice result from a splicing defect in the steel factory sytoplasmic tail, Gene Dev., 10 (1992), 1832-1842. |
| [3] | Z. Y. Wang, Research on steel plate surface defects detection method based on machine vision, Comput. Modern., 7 (2013), 97-117. |
| [4] | C. Xie, T. Z. Xie, Key technology of detecting hot heavy rail steel surface faults based on machine vision, J. Chongqing. Univ., 36 (2013), 16-21. |
| [5] | Q. W. Luo, Y. G. He, A cost-effective and automatic surface defect inspection system for hot-rolled flat steel, Robot Com-int. Manuf., 38 (2016), 16-30. |
| [6] | F. Meriaudeau, G. Lavallee, E. Fauvet, Machine vision prototype for defect detection on metallic tubes, SPIE- Int. Soc. Opt. Eng., Proc., 4664 (2002), 190-197. |
| [7] | B. Tang, J. Kong, X. Wang, L. Chen, Steel surface defect recognition based on support vector machine and image processing. China Mechan. Eng., 22 (2011), 1402-1405. |
| [8] | J. Iiarinen, K. Heikkinen, J. Rauhanmaa, A defect detection scheme for web surface inspection, Int. J. Pattern Recogn., 14 (2000), 735-755. |
| [9] | J. V. D. Weijer, T. Gevers, A. D. Bagdanov, Boosting color saliency in image feature detection, IEEE T. Pattern Anal., 28 (2005), 150-156. |
| [10] | Z. W. Qiu, T. W. Zhang, New image color feature extraction method, J. Harbin Ins. Tech., 36 (2004), 1699-1701. |
| [11] | Y. G. Wang, J. Yang, Y. Zhou, Y. Z. Wang, Region partition and feature matching based color recognition of tongue image, Pattern Recogn. Lett., 28 (2007), 11-19. |
| [12] | S. S. Patil, A. V. Dusane, Use of color feature extraction technique based on color distribution and relevance feedback for content based image retrieval, Int. J. Comput. Appl., 52 (2012), 9-12. |
| [13] | W. T. Chen, W. H. Liu, M. S. Chen, Adaptive color feature extraction based on image color distributions, IEEE T. Image Process, 19 (2010), 2005-2016. |
| [14] | Z. H. Tang, Y. Y. Sun, W. H. Gui, J. P. Liu, Flotation froth image texture feature extraction based on wavelet transform, Comp. Eng., 37 (2011), 206-208. |
| [15] | C. Y. Pang, J. K. Liu, Improved LFP algorithm on Leukocyte image texture feature extraction and recognition, Acta Photon. Sinica., 42 (2013), 1375-1380. |
| [16] | Q. Liu, X. P. Liu, L. J. Zhang, L. M. Zhao, Image texture feature extraction & recognition of Chinese herbal medicine based on gray level co-occurrence matrix, Adv. Mater. Res., 605-607 (2012), 2240-2244. |
| [17] | V. Yu, D. Ruan, D. Nguyen, T. Kaprealian, K. Sheng, SU-F-R-17: Advancing Glioblastoma Multiforme (GBM) recurrence detection with MRI image texture feature extraction and machine learning, Med. Phys., 43 (2016), 3376-3377. |
| [18] | B. Yuan, B. Xia, D.Zhang, Polarization image texture feature extraction algorithm based on CS-LBP operator, Procedia. Comp. Sci., 131 (2018), 295-301. |
| [19] | D. X. Wei, X. Y. Chen, R. C. Xu, Image shape feature extraction method based on corner point detection, Comp. Eng., 36 (2010), 220-222. |
| [20] | O. Mari, N. Seishi, Plant Shape Discrimination of several taxa without shape feature extraction using neural networks with image input, Breed. Sci., 50 (2000), 189-196. |
| [21] | B. Vijayalakshmi, A new shape feature extraction method for leaf image retrieval, 4th Int. Conf. Signal Image (SIPRO), 221 (2013), 235-245. |
| [22] | T. Meruliya, P. Dhameliya, J. Patel, D. Panchal, P. Kadam, S. Naik, Image processing for fruit shape and texture feature extraction-review, Int. J. Comput. Appl., 129 (2015), 30-33. |
| [23] | C. Li, Q. Cao, Extraction method of shape feature for vegetables based on depth image, Trans. Chin. Soc. Agric. Mach., 43 (2012), 242-245. |
| [24] | L. M. Bruce, C. H. Koger, L. Li, Dimensionality reduction of hyperspectral data using discrete wavelet transform feature extraction, IEEE T. Geosci. Remote, 40 (2002), 2331-2338. |
| [25] | P. Pudil, J. Novovičová, J. Kittler, Floating search methods in feature selection, Pattern Recogn. Lett., 15 (1994), 1119-1125. |
| [26] | E. K. Wang, N. Zhe, Y. Li, Z. D. Liang, Y. Ye, A spare deep learning model for privacy attack on remote sensing images, Math. Biosci. Eng., 16 (2019), 1300-1312. |
| [27] | H. Y. Zhao, C. Che, B. Jin, X. P. Wei, A viral protein identifying framework based on temporal Convolutional network, Math. Biosci. Eng., 16 (2019), 1709-1717. |
| [28] | Z. C. Zhang, Y. Zhang, T. Zhou, Y. L. Pang, Medical assertion classification in Chinese EMRs using attention enhanced neural network, Math. Biosci. Eng., 16 (2019), 1966-1977. |
| [29] | E. K. Wang, L. Xi, R. Sun, F. Wang, L. Pan, A new deep learning model for assisted diagnosis on electrocardiogram, Math. Biosci. Eng., 16 (2019), 2481-2491. |
| [30] | H. J. Deng, L. X. Peng, J. J. Zhang, C. M. Tang, H. L. Fang, H. H. Liu, An intelligent aerator algorithm inspired by deep learning, Math. Biosci. Eng., 16 (2019), 2990-3002. |
| [31] | S. Y. Chen, Y. Zhang, Y. H. Zhang, J. J. Yu, Y. X. Zhu, Embedded system for road damage detection by deep Convolutional neural network, Math. Biosci. Eng., 16 (2019), 7982-7994. |
| [32] | Y. X. Zhang, L. C. Jin, B. Wang, D. H. Hu, L. Q. Wang, P. Li, et al., DL-CNV: A deep learning method for identifying copy number variations based on next generation target sequencing, Math. Biosci. Eng., 17 (2020), 202-215. |
| [33] | Y. Lecun, Y. Bengio, G. Hinton, Deep learning, Nature, 521 (2015), 436. |
| [34] | L. Z. Wang, S. Q. Guan Strip steel surface defect recognition based on deep learning, J. Xi'an Polytech. Univ., 31 (2017), 669-674. |
| [35] | L. Yi, G. Li, M. Jiang, An end-to-end steel strip surface defects recognition system based on convolutional neural networks, Steel Res. Int., 87 (2016), 1-5. |
| [36] | H. H. Hotelling, Analysis of Complex Statistical Variables into Principal Components. Br. J. Educ. Psychol., 24 (1932), 417-520. |
| [37] | M. T. Kluger, H. Owen, Advantages of PCA exaggerated? Anaesth. Intens. Care, 18 (1990), 588-589. |
| [38] | M. Rezghi, O. Askar, Noise-free principal component analysis: An efficient dimension reduction technique for high dimensional molecular data, Expert. Syst. Appl., 41 (2014), 7797-7804. |
| [39] | D. M. Blei, A. Y. Ng, M. I. Jordan, J. Lafferty, Latent dirichlet allocation, J. Mach. Learn. Res., 3 (2003), 993-1022. |
| [40] | W. Chen, J. E. Meng, S. Q. Wu, PCA and LDA in DCT domain, Pattern Recogn. Lett., 26 (2005), 2474-2482. |
| [41] | E. Shchepakina, Black swans and canards in self-ignition problem, Nonlin. Anal-real., 4 (2003), 45-50. |
| [42] | J. N. Wu, J. Wang, L. Liu, Feature extraction via KPCA for classification of gait patterns, Hum. Movem. Sci., 26 (2007), 393-411. |
| [43] | L. J. Cao, K.S. Chua, W. K. Chong, H. P. Lee, Q. M. Gu, A comparison of PCA, KPCA and ICA for dimensionality reduction in support vector machine, Neurocomputing, 55 (2003), 321-336. |
| [44] | L. Liu, K. L. Liu, Z. H. Cong, J. L. Zhao, Y. F. Ji, J. He, Long Length Document Classification by Local Convolutional Feature Aggregation, Algorithm., 11 (2018), 109. |
| [45] | D. Mellado, C. Saavedra, S. Chabert, R. Torres, R. Salas, Self-improving generative artificial neural network for pseudorehearsal incremental class learning, Algorithm, 12 (2019), 206. |
| [46] | F. Aziz, A. S. W. Wong, S. Chalup, Semi-supervised manifold alignment using parallel deep autoencoders, Algorithms, 12 (2019), 186. |
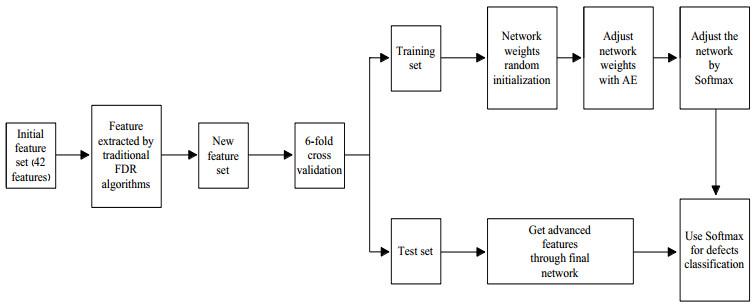
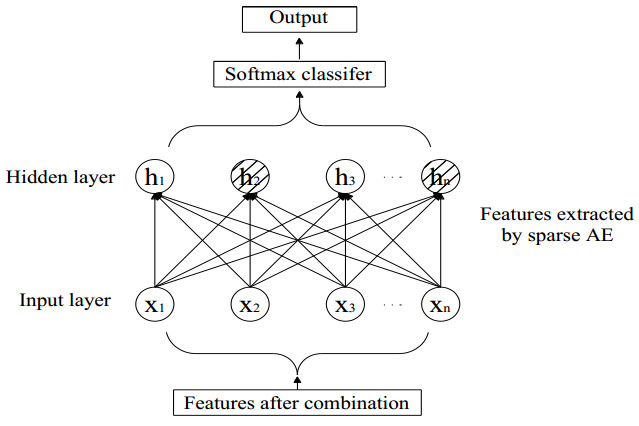
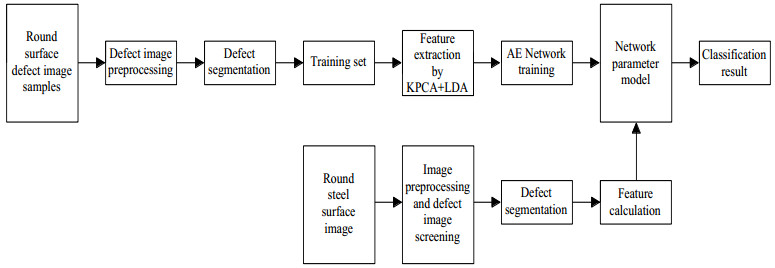
Figures(3) / Tables(8)

Xuguo Yan, Liang Gao. A feature extraction and classification algorithm based on improved sparse auto-encoder for round steel surface defects[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5369-5394. doi: 10.3934/mbe.2020290







 DownLoad:
DownLoad: