Citation: Haoyu Lu, Daofu Gong, Fenlin Liu, Hui Liu, Jinghua Qu. A batch copyright scheme for digital image based on deep neural network[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 6121-6133. doi: 10.3934/mbe.2019306

| [1] | G. L. Friedman, The trustworthy digital camera: Restoring credibility to the photographic image, IEEE T. Consum. Elec., 39 (1993), 905–910. |
| [2] | S. Bhattacharjee and M. Kutter, Compression tolerant image authentication, International Conference on Image Processing, (1998), 435–439. |
| [3] | J. Dittmann, A. Steinmetz and R. Steinmetz, Content-based digital signature for motion pictures authentication and content-fragile watermarking, IEEE International Conference on Multimedia Computing and Systems, (1999), 209–213. |
| [4] | C. Lin and S. Chang, Robust image authentication method surviving jpeg lossy compression, Storage and Retrieval for Image and Video Databases VI. International Society for Optics and Photonics, 3312 (1997), 296–308. |
| [5] | C. S. Lu and H. Liao, Structural digital signature for image authentication: an incidental distortion resistant scheme, IEEE T. Multimedia, 5 (2003), 161–173. |
| [6] | D. Gong, F. Liu and X. Luo, An image edge based robust watermarking algorithm, Sci. Sin. Inform., 43 (2013), 1410–1430. |
| [7] | H. Qi, D. Zheng and J. Zhao, Human visual system based adaptive digital image watermarking, Sig. Proc., 88 (2008), 174–188. |
| [8] | J. Seo and C. Yoo, Image watermarking based on invariant regions of scale-space representation, IEEE T. Sig. Proc., 54 (2006), 1537–1549. |
| [9] | Y. Wang, R. Ni, Y. Zhao, et al., Watermark embedding for direct binary searched halftone images by adopting visual cryptography, Comput. Mater. Continua, 55 (2018), 255–265. |
| [10] | J. Tsai, W. Huang, C. Chen, et al., A feature-based digital image watermarking for copyright protection and content authentication, IEEE International Conference on Image Processing, 5 (2007), V–469. |
| [11] | Y. Zhang, D. Ye, J. Gan, et al., An image steganography algorithm based on quantization index modulation resisting scaling attacks and statistical detection, Comput. Mater. Continua, 56 (2018), 151–167. |
| [12] | Y. Lin, C. Huang and G. Lee, Rotation, scaling, and translation resilient watermarking for images, IET Image Proc., 5 (2011), 328–340. |
| [13] | J. Tsai, W. Huang, Y. Kuo, et al., On the selection of optimal feature region set for robust digital image watermarking, IEEE T. Image Proc., 20 (2011), 735–743. |
| [14] | M. Kutter, F. Jordan, F. Bossen, et al., Digital watermarking of color images using amplitude modulation, J. Elec. Imaging, 7 (1998), 326–333. |
| [15] | D. Gong, Y. Chen, H. Lu, et al., Self-embedding image watermarking based on combined decision using pre-offset and post-offset blocks, Comput. Mater. Continua, 57 (2018), 243–260. |
| [16] | T. Sridevi, T. Ramya, Y. Ramadevi, et al., A robust watermarking algorithm based on image normalization, in 2010 Second Vaagdevi International Conference on Information Technology for Real World Problems (VCON), (2010), 70–75. |
| [17] | K. Liu, Wavelet-based watermarking for color images through visual masking, AEU-Int. J. Electron. C., 64 (2010), 112–124. |
| [18] | N. Kalantari, S. M. Ahadi and M. Vafadust, A robust image watermarking in the ridgelet domain using universally optimum decoder, IEEE T. Circ. Syst. Vid., 20 (2010), 396–406. |
| [19] | C. Lin, M. Wu, J. Bloom, et al., Rotation, scale, and translation resilient watermarking for images, IEEE T. Image Proc., 10 (2001), 767–782. |
| [20] | X. Kang, J. Huang, Jiwu, Y. Shi, et al., A dwt-dft composite watermarking scheme robust to both affine transform and jpeg compression, IEEE T. Circ. Syst. Vid., 13 (2003), 776–786. |
| [21] | X. Kang, J. Huang and W. Zeng, Efficient general print-scanning resilient data hiding based on uniform log-polar mapping, IEEE T. Inf. Foren. Sec., 5 (2010), 1–12. |
| [22] | D. Rosiyadi, S. Horng, P. Fan, et al., Copyright protection for e-government document images, IEEE MultiMedia, 19 (2012), 62–73. |
| [23] | I. Cox, M. Miller, J. Bloom, et al., in Digital watermarking and steganography, Morgan kaufmann, (2007). |
| [24] | H. Al-Otum and A. Al-Taba'a, Adaptive color image watermarking based on a modified improved pixel-wise masking technique, Comput. Electr. Eng., 35 (2009), 673–695. |
| [25] | H. Song, S. Yu, X. Yang, et al., Contourlet-based image adaptive watermarking, Sig. Proc. Image Comm., 23 (2008), 162–178. |
| [26] | L. Ma, D. Yu, G. Wei, et al., Adaptive spread-transform dither modulation using a new perceptual model for color image watermarking, IEICE T. Inf. Sys., 93 (2010), 843–857. |
| [27] | C. Song, S. Sudirman and M. Merabti, Robust digital image watermarking using region adaptive embedding technique, 2010 IEEE International Conference on Progress in Informatics and Computing (PIC), 1 (2010), 378–382. |
| [28] | L. Wu, Y. Wang, J. Gao, et al., Deep adaptive feature embedding with local sample distributions for person re-identification, Pat. Recog., 73 (2018), 275–288. |
| [29] | L. Wu, Y. Wang, X. Li, et al., What-and-where to match: deep spatially multiplicative integration networks for person re-identification, Pat. Recog., 76 (2018), 727–738. |
| [30] | L. Wu, Y. Wang, J. Gao, et al., Where-and-when to look: Deep siamese attention networks for video-based person re-identification, IEEE T. Multimedia, 21 (2019), 1412–1424. |
| [31] | G. Cybenko, Approximation by superpositions of a sigmoidal function, Math. Control Signal., 2 (1989), 303–314. |
| [32] | K. Hornik, M. Stinchcombe and H. White, Multilayer feedforward networks are universal approximators, Neural Networks, 2 (1989), 359–366. |
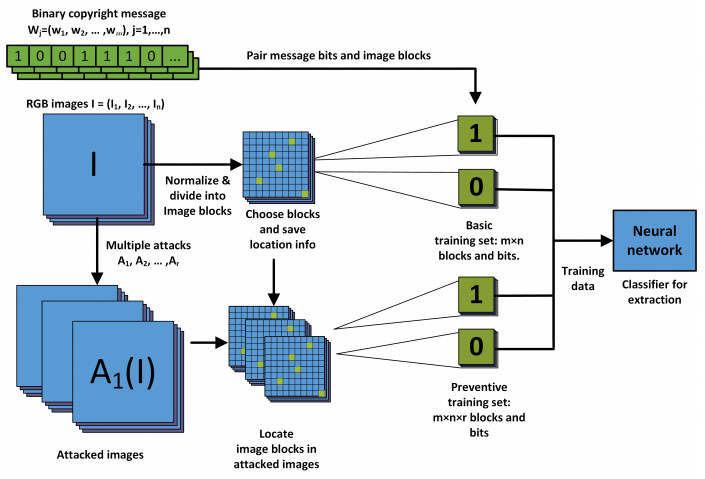
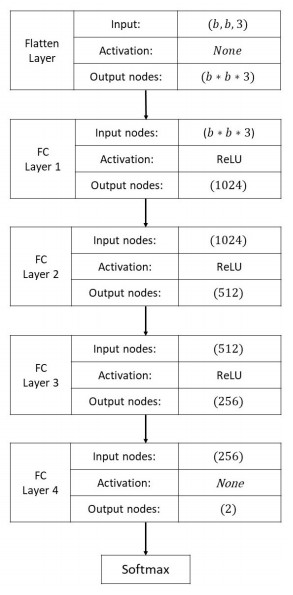
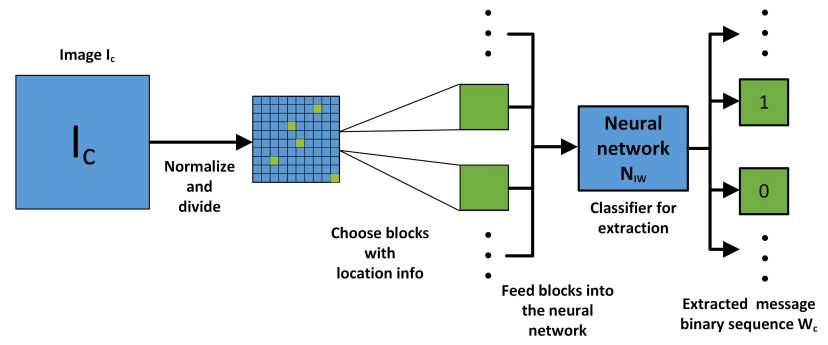


Figures(5) / Tables(5)

Haoyu Lu, Daofu Gong, Fenlin Liu, Hui Liu, Jinghua Qu. A batch copyright scheme for digital image based on deep neural network[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 6121-6133. doi: 10.3934/mbe.2019306







 DownLoad:
DownLoad: