Citation: Narges Montazeri Shahtori, Tanvir Ferdousi, Caterina Scoglio, Faryad Darabi Sahneh. Quantifying the impact of early-stage contact tracing on controlling Ebola diffusion[J]. Mathematical Biosciences and Engineering, 2018, 15(5): 1165-1180. doi: 10.3934/mbe.2018053

| [1] | [ C. Browne,H. Gulbudak,G. Webb, Modeling contact tracing in outbreaks with application to Ebola, Journal of Theoretical Biology, 384 (2015): 33-49. |
| [2] | [ G. Chowell,C. Viboud, Is it growing exponentially fast?-Impact of assuming exponential growth for characterizing and forecasting epidemics with initial near-exponential growth dynamics, Infectious Disease Modelling, 1 (2016): 71-78. |
| [3] | [ O. Diekmann,J. A. P. Heesterbeek,J. A. J. Metz, On the definition and the computation of the basic reproduction ratio $R_{0}$ in models for infectious diseases in heterogeneous populations, Journal of Mathematical Biology, 28 (1990): 365-382. |
| [4] | [ M. G. Dixon,I. J. Schafer, Ebola Viral Disease Outbreak - West Africa, 2014, MMWR Morb Mortal Wkly Rep, 63 (2014): 548-551. |
| [5] | [ K. T. Eames,M. J. Keeling, Contact tracing and disease control, Proceedings of the Royal Society of London B: Biological Sciences, 270 (2003): 2565-2571. |
| [6] | [ F. O. Fasina, A. Shittu, D. Lazarus, O. Tomori, L. Simonsen, C. Viboud and G. Chowell, Transmission dynamics and control of Ebola virus disease outbreak in Nigeria, July to September 2014, Eurosurveillance, 19 (2014), 20920. |
| [7] | [ M. Greiner,D. Pfeiffer,R. D. Smith, Principles and practical application of the receiver-operating characteristic analysis for diagnostic tests, Preventive Veterinary Medicine, 45 (2000): 23-41. |
| [8] | [ J. M. Heffernan,R. J. Smith,L. M. Wahl, Perspectives on the basic reproductive ratio, Journal of the Royal Society Interface, 2 (2005): 281-293. |
| [9] | [ M. J. Keeling and P. Rohani, Modeling Infectious Diseases in Humans and Animals, Princeton University Press, Princeton, NJ, 2008. |
| [10] | [ I. Z. Kiss,D. M. Green,R. R. Kao, Disease contact tracing in random and clustered networks, Proceedings of the Royal Society of London B: Biological Sciences, 272 (2005): 1407-1414. |
| [11] | [ D. Klinkenberg,C. Fraser,H. Heesterbeek, The effectiveness of contact tracing in emerging epidemics, PloS One, 1 (2006): e12. |
| [12] | [ S. Liu,N. Perra,M. Karsai,A. Vespignani, Controlling contagion processes in activity driven networks, Physical review letters, 112 (2014): 118702. |
| [13] | [ A. S. da Mata and R. Pastor-Satorras, Slow relaxation dynamics and aging in random walks on activity driven temporal networks, The European Physical Journal B, 88 (2015), Art. 38, 8 pp. |
| [14] | [ N. Perra, B. Gonçalves, R. Pastor-Satorras and A. Vespignani, Activity Driven Modeling of Time Varying Networks, Scientific Reports, 2012. |
| [15] | [ N. Perra,A. Baronchelli,D. Mocanu,B. Gonc'calves,R. Pastor-Satorras,A. Vespignani, Random walks and search in time-varying networks, Physical review letters, 109 (2012): 238701. |
| [16] | [ A. Rizzo,B. Pedalino,M. Porfiri, A network model for Ebola spreading, Journal of theoretical biology, 394 (2016): 212-222. |
| [17] | [ A. Rizzo,M. Frasca,M. Porfiri, Effect of individual behavior on epidemic spreading in activity-driven networks, Physical Review E, 90 (2014): 042801. |
| [18] | [ A. Rizzo and M. Porfiri, Toward a realistic modeling of epidemic spreading with activity driven networks, in Temporal Network Epidemiology (N. Masuda and P. Holme), Springer, (2017), 317-319. |
| [19] | [ N. M. Shahtori,C. Scoglio,A. Pourhabib,F. D. Sahneh, Sequential Monte Carlo filtering estimation of Ebola progression in West Africa, American Control Conference(ACC), null (2016): 1277-1282. |
| [20] | [ M. D. Shirley,S. P. Rushton, The impacts of network topology on disease spread, Ecological Complexity, 2 (2005): 287-299. |
| [21] | [ F. Shuaib,R. Gunnala,E. O. Musa,F. J. Mahoney,O. Oguntimehin,P. M. Nguku,S. B. Nyanti,N. Knight,N. S. Gwarzo,O. Idigbe,A. Nasidi,J. F. Vertefeuille, Ebola virus disease outbreak-Nigeria, July-September 2014, MMWR Morb Mortal Wkly Rep, 63 (2014): 867-872. |
| [22] | [ M. Starnini,R. Pastor-Satorras, Temporal percolation in activity-driven networks, Physical Review E, 89 (2014): 032807. |
| [23] | [ M. Starnini,R. Pastor-Satorras, Topological properties of a time-integrated activity-driven network, Physical Review E, 87 (2013): 062807. |
| [24] | [ K. Sun, A. Baronchelli and N. Perra, Contrasting effects of strong ties on SIR and SIS processes in temporal networks, The European Physical Journal B, 88 (2015), Art. 326, 8 pp. |
| [25] | [ L. Zino,A. Rizzo,M. Porfiri, Continuous-Time Discrete-Distribution Theory for Activity-Driven Networks, Physical Review Letters, 117 (2016): 228302. |
| [26] | [ Cases of Ebola Diagnosed in the United States, 2014. Available from: https://www.cdc.gov/vhf/ebola/outbreaks/2014-west-africa/united-states-imported-case.html. |
| [27] | [ Implementation and Management of Contact Tracing for Ebola Virus Disease, Emergency Guideline by the World Health Organization, 2015. Available from: https://www.cdc.gov/vhf/ebola/pdf/contact-tracing-guidelines.pdf. |
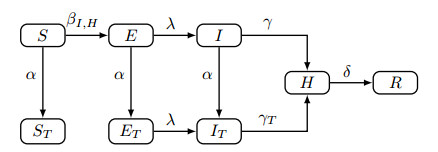
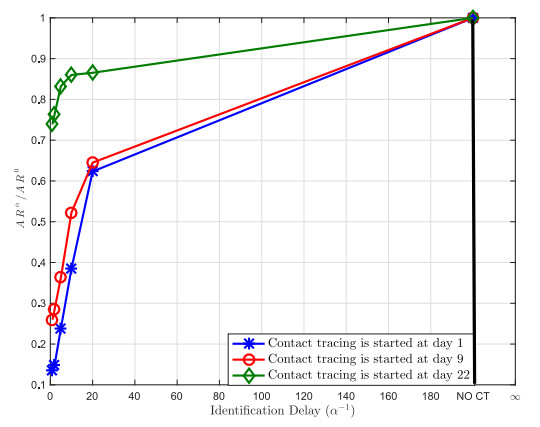
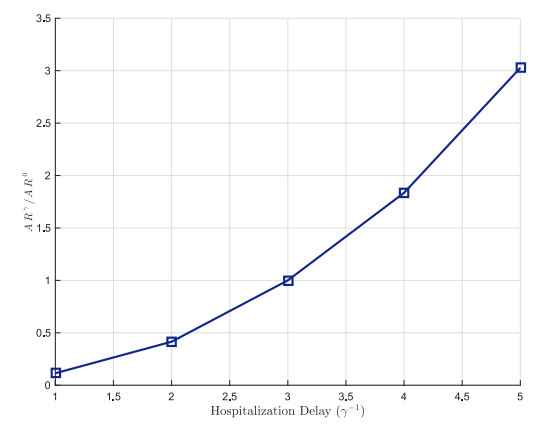
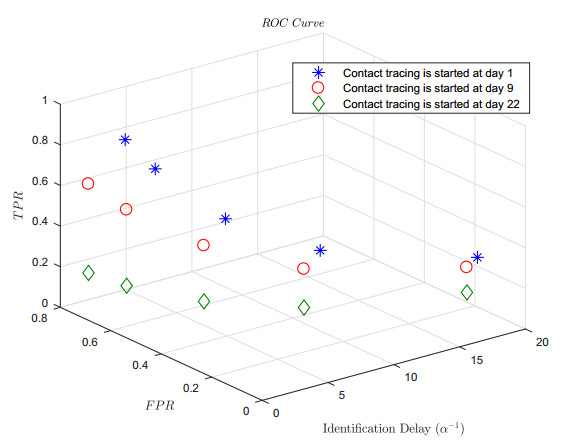
Figures(7) / Tables(2)

Narges Montazeri Shahtori, Tanvir Ferdousi, Caterina Scoglio, Faryad Darabi Sahneh. Quantifying the impact of early-stage contact tracing on controlling Ebola diffusion[J]. Mathematical Biosciences and Engineering, 2018, 15(5): 1165-1180. doi: 10.3934/mbe.2018053







 DownLoad:
DownLoad: