Citation: Mark G. Burch, Karly A. Jacobsen, Joseph H. Tien, Grzegorz A. Rempała. Network-based analysis of a small Ebola outbreak[J]. Mathematical Biosciences and Engineering, 2017, 14(1): 67-77. doi: 10.3934/mbe.2017005

| [1] | [ L. J. Allen, An introduction to stochastic epidemic models, Mathematical Epidemiology,Springer, 1945 (2008), 81-130. |
| [2] | [ M. Altmann, The deterministic limit of infectious disease models with dynamic partners, Mathematical Biosciences, 150 (1998): 153-175. |
| [3] | [ H. Andersson and T. Britton, Stochastic Epidemic Models and Their Statistical Analysis vol. 4, Springer New York, 2000. |
| [4] | [ A.D. Barbour,G. Reinert, Approximating the epidemic curve, Electronic Journal of Probability, 18 (2013): 1-30. |
| [5] | [ M. Boguñá,C. Castellano,R. Pastor-Satorras, Nature of the epidemic threshold for the susceptible-infected-susceptible dynamics in networks, Physical Review Letters, 111 (2013): 068701. |
| [6] | [ T. Bohman,M. Picollelli, SIR epidemics on random graphs with a fixed degree sequence, Random Structures & Algorithms, 41 (2012): 179-214. |
| [7] | [ T. Britton,P.D. O'Neill, Bayesian inference for stochastic epidemics in populations with random social structure, Scandinavian Journal of Statistics, 29 (2002): 375-390. |
| [8] | [ B. Choi,G.A. Rempala, Inference for discretely observed stochastic kinetic networks with applications to epidemic modeling, Biostatistics, 13 (2012): 153-165. |
| [9] | [ G. Chowell and H. Nishiura, Transmission dynamics and control of Ebola virus disease (EVD): A review, BMC Medicine, 12 (2014), p196. |
| [10] | [ L. Decreusefond,J.-S. Dhersin,P. Moyal,V.C. Tran, Large graph limit for an SIR process in random network with heterogeneous connectivity, The Annals of Applied Probability, 22 (2012): 541-575. |
| [11] | [ C. Groendyke,D. Welch,D.R. Hunter, Bayesian inference for contact networks given epidemic data, Scandinavian Journal of Statistics, 38 (2011): 600-616. |
| [12] | [ C. Groendyke,D. Welch,D.R. Hunter, A network-based analysis of the 1861 Hagelloch measles data, Biometrics, 68 (2012): 755-765. |
| [13] | [ T. House,M.J. Keeling, Insights from unifying modern approximations to infections on networks, Journal of The Royal Society Interface, 8 (2011): 67-73. |
| [14] | [ S. Janson,M. Luczak,P. Windridge, Law of large numbers for the SIR epidemic on a random graph with given degrees, Random Structures & Algorithms, 45 (2014): 726-763. |
| [15] | [ J. Janssen, null, Semi-Markov Models: Theory and Applications, New York, Plenum Press, 1986. |
| [16] | [ M. Keeling, The implications of network structure for epidemic dynamics, Theoretical Population Biology, 67 (2005): 1-8. |
| [17] | [ M.J. Keeling, The effects of local spatial structure on epidemiological invasions, Proceedings of the Royal Society of London B: Biological Sciences, 266 (1999): 859-867. |
| [18] | [ M. Keeling, Correlation equations for endemic diseases: externally imposed and internally generated heterogeneity, Proceedings of the Royal Society of London B: Biological Sciences, 266 (1999): 953-960. |
| [19] | [ W. O. Kermack and A. G. McKendrick, A contribution to the mathematical theory of epidemics, in Proceedings of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, vol. 115, The Royal Society, 1927,700-721. |
| [20] | [ T.G. Kurtz, Limit theorems for sequences of jump markov processes approximating ordinary differential processes, Journal of Applied Probability, 8 (1971): 344-356. |
| [21] | [ J. Legrand,R. Grais,P. Boelle,A. Valleron,A. Flahault, Understanding the dynamics of Ebola epidemics, Epidemiology and Infection, 135 (2007): 610-621. |
| [22] | [ G.D. Maganga,J. Kapetshi,N. Berthet,B. Kebela Ilunga,F. Kabange,P. Mbala Kingebeni,V. Mondonge,J.-J. T. Muyembe,E. Bertherat,S. Briand, Ebola virus disease in the democratic republic of congo, New England Journal of Medicine, 371 (2014): 2083-2091. |
| [23] | [ S. Meloni,N. Perra,A. Arenas,S. Gómez,Y. Moreno,A. Vespignani, Modeling human mobility responses to the large-scale spreading of infectious diseases, Scientific Reports, 1 (2011): 1-7. |
| [24] | [ J.C. Miller,A.C. Slim,E.M. Volz, Edge-based compartmental modelling for infectious disease spread, Journal of the Royal Society Interface, 9 (2012): 890-906. |
| [25] | [ J.C. Miller,E.M. Volz, Incorporating disease and population structure into models of SIR disease in contact networks, PloS One, 8 (2013): e69162. |
| [26] | [ M. Newman, null, Networks: An Introduction, Oxford University Press, 2010. |
| [27] | [ L. Pellis,F. Ball,S. Bansal,K. Eames,T. House,V. Isham,P. Trapman, Eight challenges for network epidemic models, Epidemics, 10 (2015): 58-62. |
| [28] | [ D. Rand, Correlation equations and pair approximations for spatial ecologies, Advanced Ecological Theory: Principles and Applications, Oxford Blackwell Science, 1999. |
| [29] | [ E. J. Schwartz, B. Choi and G. A. Rempala, Estimating epidemic parameters: Application to H1N1 pandemic data, Math. Biosciences, 270 (2015), 198-203 (e-pub, ahead of print). |
| [30] | [ W.E.R. Team, Ebola virus disease in west africa-the first 9 months of the epidemic and forward projections, N Engl J Med, 371 (2014): 1481-1495. |
| [31] | [ E. Volz, SIR dynamics in random networks with heterogeneous connectivity, Journal of Mathematical Biology, 56 (2008): 293-310. |
| [32] | [ D. Welch,S. Bansal,D.R. Hunter, Statistical inference to advance network models in epidemiology, Epidemics, 3 (2011): 38-45. |
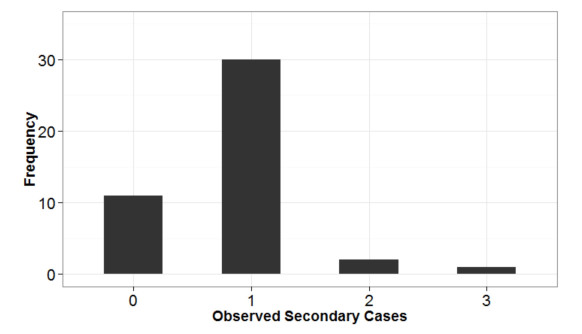
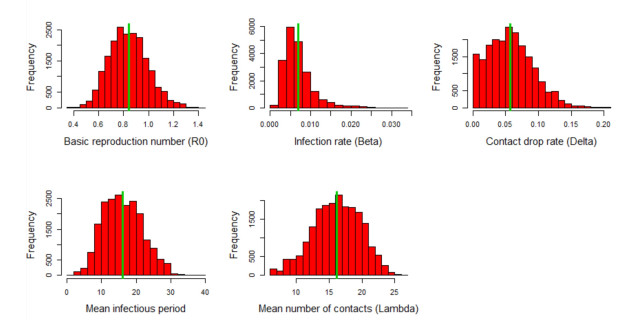
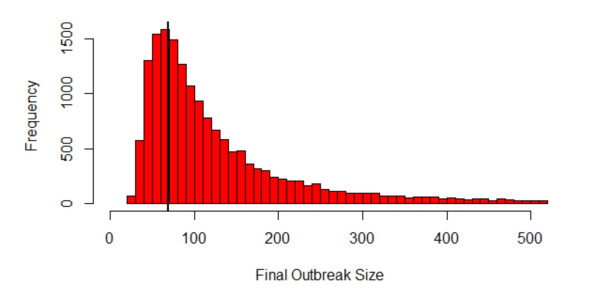
Figures(3)

Mark G. Burch, Karly A. Jacobsen, Joseph H. Tien, Grzegorz A. Rempała. Network-based analysis of a small Ebola outbreak[J]. Mathematical Biosciences and Engineering, 2017, 14(1): 67-77. doi: 10.3934/mbe.2017005







 DownLoad:
DownLoad: