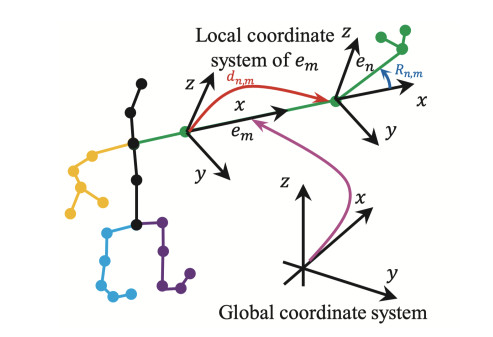
Lately, as a subset of human-centric studies, vision-oriented human action recognition has emerged as a pivotal research area, given its broad applicability in fields like healthcare, video surveillance, autonomous driving, sports, and education. This brief applies Lie algebra and standard bone length data to represent human skeleton data. A multi-layer long short-term memory (LSTM) recurrent neural network and convolutional neural network (CNN) are applied for human motion recognition. Finally, the trained network weights are converted into the crossbar-based memristor circuit, which can accelerate the network inference, reduce energy consumption, and obtain an excellent computing performance.
Citation: Zhencheng Fan, Zheng Yan, Yuting Cao, Yin Yang, Shiping Wen. Enhancing skeleton-based human motion recognition with Lie algebra and memristor-augmented LSTM and CNN[J]. AIMS Mathematics, 2024, 9(7): 17901-17916. doi: 10.3934/math.2024871
Lately, as a subset of human-centric studies, vision-oriented human action recognition has emerged as a pivotal research area, given its broad applicability in fields like healthcare, video surveillance, autonomous driving, sports, and education. This brief applies Lie algebra and standard bone length data to represent human skeleton data. A multi-layer long short-term memory (LSTM) recurrent neural network and convolutional neural network (CNN) are applied for human motion recognition. Finally, the trained network weights are converted into the crossbar-based memristor circuit, which can accelerate the network inference, reduce energy consumption, and obtain an excellent computing performance.

| [1] |
J. Rafferty, C. D. Nugent, J. Liu, L. Chen, From activity recognition to intention recognition for assisted living within smart homes, IEEE Trans. Human Machine Syst., 47 (2017), 368–379. https://doi.org/10.1109/THMS.2016.2641388 doi: 10.1109/THMS.2016.2641388

|
| [2] |
Y. Sun, Z. Zhang, I Kakkos, G. K. Matsopoulos, J. J. Yuan, J. Suckling, Inferring the individual psychopathologic deficits with structural connectivity in a longitudinal cohort of Schizophrenia, IEEE J. Biomed. Health Informa., 26 (2022), 2536–2546. https://doi.org/10.1109/JBHI.2021.3139701 doi: 10.1109/JBHI.2021.3139701
|
| [3] |
Z. Guo, L. Zhao, J. Yuan, H. Yu, MSANet: Multiscale aggregation network integrating spatial and channel information for Lung nodule detection, IEEE J. Biomed. Health Inform., 26 (2022), 2547–2558. https://doi.org/10.1109/JBHI.2021.3131671 doi: 10.1109/JBHI.2021.3131671
|
| [4] |
J. W. Li, S. Barma, P. Un Mak, F. Chen, C. Li, M. T. Li, et al., Single-channel selection for EEG-based emotion recognition using brain rhythm sequencing, IEEE J. Biomed. Health Inform., 26 (2022), 2493–2503. https://doi.org/10.1109/JBHI.2022.3148109 doi: 10.1109/JBHI.2022.3148109
|
| [5] | C. Finn, I. Goodfellow, S. Levine, Unsupervised learning for physical interaction through video prediction, arXiv: 1605.07157, 2016. https://doi.org/10.48550/arXiv.1605.07157 |
| [6] | L. Liu, L. Cheng, Y. Liu, Y. Jia, D. S. Rosenblum, Recognizing complex activities by a probabilistic interval-based model, In: Proceedings of the thirtieth AAAI conference on artificial intelligence (AAAI'16), AAAI Press, 2016, 1266–1272. https://doi.org/10.5555/3015812.3015999 |
| [7] | Z. Cao, T. Simon, S. E. Wei, Y. Sheikh, Realtime multi-person 2D pose estimation using part affinity fields, arXiv: 1611.08050, 2016. https://doi.org/10.48550/arXiv.1611.08050 |
| [8] | R. Vemulapalli, F. Arrate, R. Chellappa, Human action recognition by representing 3D skeletons as points in a Lie group, In: 2014 IEEE Conference on computer vision and pattern recognition, 2014,588–595. https://doi.org/10.1109/CVPR.2014.82 |
| [9] | K. Fragkiadaki, S. Levine, P. Felsen, J. Malik, Recurrent network models for human dynamics, In: IEEE International conference on computer vision (ICCV), 2015, 4346–4354. https://doi.org/10.1109/ICCV.2015.494 |
| [10] | A. Jain, A. R. Zamir, S. Savarese, A. Saxena, Structural-RNN: Deep learning on spatio-temporal graphs, In: 2016 IEEE Conference on computer vision and pattern recognition (CVPR), 2016, 5308–5317. https://doi.org/10.1109/CVPR.2016.573 |
| [11] | J. Redmon, A. Farhadi, YOLOv3: An incremental improvement, arXiv: 1804.02767, 2018. https://doi.org/10.48550/arXiv.1804.02767 |
| [12] |
K. Smagulova, A. P. James, A survey on LSTM memristive neural network architectures and applications, Eur. Phys. J. Spec. Top., 228 (2019), 2313–2324. https://doi.org/10.1140/epjst/e2019-900046-x doi: 10.1140/epjst/e2019-900046-x
|
| [13] | J. Hu, Z. Fan, J. Liao, L. Liu, Predicting long-term skeletal motions by a spatio-temporal hierarchical recurrent network, arXiv: 1911.02404, 2019. https://doi.org/10.48550/arXiv.1911.02404 |
| [14] | C. Li, P. Wang, S. Wang, Y. Hou, W. Li, Skeleton-based action recognition using LSTM and CNN, In: 2017 IEEE International conference on multimedia & expo workshops (ICMEW), 2017,585–590. https://doi.org/10.1109/ICMEW.2017.8026287 |
| [15] |
Q. Huang, L. Jia, G. Ren, X. Wang, C. Liu, Extraction of vascular wall in carotid ultrasound via a novel boundary-delineation network, Eng. Appl. Artif. Intell., 121 (2023), 106069. https://doi.org/10.1016/j.engappai.2023.106069 doi: 10.1016/j.engappai.2023.106069
|
| [16] |
J. Liu, Y. Wang, Y. Liu, S. Xiang, C. Pan, 3D PostureNet: A unified framework for skeleton-based posture recognition, Pattern Recognition Lett., 140 (2020), 143–149. https://doi.org/10.1016/j.patrec.2020.09.029 doi: 10.1016/j.patrec.2020.09.029
|
| [17] |
P. Wang, J. Wen, C. Si, Y. Qian, L. Wang, Contrast-reconstruction representation learning for self-supervised skeleton-based action recognition, IEEE Trans. Image Process., 31 (2022), 6224–6238. https://doi.org/10.1109/TIP.2022.3207577 doi: 10.1109/TIP.2022.3207577
|
| [18] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84–90. https://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [19] | T. M. Taha, R. Hasan, C. Yakopcic, M. R. McLean, Exploring the design space of specialized multicore neural processors, In: 2013 International joint conference on neural networks (IJCNN), 2013, 1–8. https://doi.org/10.1109/IJCNN.2013.6707074 |
| [20] |
L. Chua, Memristor-The missing circuit element, IEEE Trans. Circuit Theory, 18 (1971), 507–519. https://doi.org/10.1109/TCT.1971.1083337 doi: 10.1109/TCT.1971.1083337
|
| [21] |
S. Wen, R. Hu, Y. Yang, T. Huang, Z. Zeng, Y. D. Song, Memristor-based echo state network with online least mean square, IEEE Trans. Syst. Man Cybernet., 49 (2019), 1787–1796. https://doi.org/10.1109/TSMC.2018.2825021 doi: 10.1109/TSMC.2018.2825021
|
| [22] |
S. H. Jo, K. H. Kim, W. Lu, High-density crossbar arrays based on a Si memristive system, Nano Lett., 9 (2009), 870–874. https://doi.org/10.1021/nl8037689 doi: 10.1021/nl8037689
|
| [23] |
R. Hasan, T. M. Taha, C. Yakopcic, On-chip training of memristor crossbar based multi-layer neural networks, Microelectronics J., 66 (2017), 31–40. https://doi.org/10.1016/j.mejo.2017.05.005 doi: 10.1016/j.mejo.2017.05.005
|
| [24] |
S. Wen, H. Wei, Y. Yang, Z. Guo, Z. Zeng, T. Huang, et al., Memristive LSTM network for sentiment analysis, IEEE Trans. Syst. Man Cybernet., 51 (2019), 1794–1804. https://doi.org/10.1109/TSMC.2019.2906098 doi: 10.1109/TSMC.2019.2906098
|
| [25] | X. Liu, Z. Zeng, D. C. Wunsch, Memristor-based LSTM network with in situ training and its applications, Neural Netw. 131 (2020), 300–311. https://doi.org/10.1016/j.neunet.2020.07.035 |
| [26] | C. Yakopcic, M. Z. Alom, T. M. Taha, Memristor crossbar deep network implementation based on a convolutional neural network, In: 2016 International joint conferenceon neural networks (IJCNN), IEEE, 2016,963–970. https://doi.org/10.1109/IJCNN.2016.7727302 |
| [27] | C. Yakopcic, M. Z. Alom, T. M. Taha, Extremely parallel memristor crossbar architecture for convolutional neural network implementation, In: 2017 International joint conference on neural networks (IJCNN), IEEE, 2017, 1696–1703. https://doi.org/10.1109/IJCNN.2017.7966055 |
| [28] |
S. Wen, J. Chen, Y. Wu, Z. Yan, Y. Cao, Y. Yang, CKFO: Convolution kemel first operated algorithm with applications in memristor-based convolutional neural network, IEEE Trans. Comput. Design Integr. Circuits Syst., 40 (2020), 1640–1647. https://doi.org/10.1109/TCAD.2020.3019993 doi: 10.1109/TCAD.2020.3019993
|
| [29] |
P. Yao, H. Wu, B. Gao, J. Tang, Q. Zhang, W. Zhang, et al., Fully hardware-implemented memristor convolutional neural network, Nature, 577 (2020), 641–646. https://doi.org/10.1038/s41586-020-1942-4 doi: 10.1038/s41586-020-1942-4
|
| [30] |
C. Ionescu, D. Papava, V. Olaru, C. Sminchisescu, Human3.6M: Large scale datasets and predictive methods for 3d human sensing in natural environments, IEEE Trans. Pattern Anal. Machine Intell., 36 (2013), 1325–1339. https://doi.org/10.1109/TPAMI.2013.248 doi: 10.1109/TPAMI.2013.248
|
| [31] | A. Shahroudy, J. Liu, T. T. Ng, G. Wang, NTU RGB+D: A large scale dataset for 3D human activity analysis, In: 2016 IEEE Conference on computer vision and pattern recognition (CVPR), IEEE, 2016, 1010–1019. https://doi.org/10.1109/CVPR.2016.115 |
| [32] | Y. Du, W. Wang, L. Wang, Hierarchical recurrent neural network for skeleton based action recognition, In: 2015 IEEE Conference on computer vision and pattern recognition (CVPR), IEEE, 2015, 1110–1118. https://doi.org/10.1109/CVPR.2015.7298714 |
| [33] |
C. Li, Y. Hou, P. Wang, W. Li, Joint distance maps based action recognition with convolutional neural networks, IEEE Signal Process. Lett., 24 (2017), 624–628. https://doi.org/10.1109/LSP.2017.2678539 doi: 10.1109/LSP.2017.2678539
|
| [34] |
P. Wang, W. Li, C. Li, Y. Hou, Action recognition based on joint trajectory maps with convolutional neurall networks, Knowledge Based Syst., 158 (2018), 43–53. https://doi.org/10.1016/j.knosys.2018.05.029 doi: 10.1016/j.knosys.2018.05.029
|
| [35] | A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, et al., PyTorch: An imperative style, high-performance deep learning library, In: Proceedings of the 33rd international conference on neural information processing systems, 2019, 8026–8037. |
| [36] |
C. Lammie, W. Xiang, B. Linares-Barranco, M. R. Azghadi, MemTorch: An open-source simulation framework for memristive deep learning systems, Neurocomputing, 485 (2022), 124–133. https://doi.org/10.1016/j.neucom.2022.02.043 doi: 10.1016/j.neucom.2022.02.043
|
| [37] |
Hadiyawarman, F. Budiman, D. G. O. Hernowo, R. R. Pandey, H. Tanaka, Recent progress on fabrication of memristor and transistor-based neuromorphic devices for high signal processing speed with low power consumption, Jpn. J. Appl. Phys., 57 (2018), 03EA06. https://doi.org/10.7567/JJAP.57.03EA06 doi: 10.7567/JJAP.57.03EA06
|
| [38] |
S. S. Sarwar, S. A. N. Saqueb, F. Quaiyum, A. B. M. H. U. Rashid, Memristor-based nonvolatile random access memory: Hybrid architecture for low power compact memory design, IEEE Access, 1 (2013), 29–34. https://doi.org/10.1109/ACCESS.2013.2259891 doi: 10.1109/ACCESS.2013.2259891
|





Figures(6) / Tables(1)

Zhencheng Fan, Zheng Yan, Yuting Cao, Yin Yang, Shiping Wen. Enhancing skeleton-based human motion recognition with Lie algebra and memristor-augmented LSTM and CNN[J]. AIMS Mathematics, 2024, 9(7): 17901-17916. doi: 10.3934/math.2024871







 DownLoad:
DownLoad: