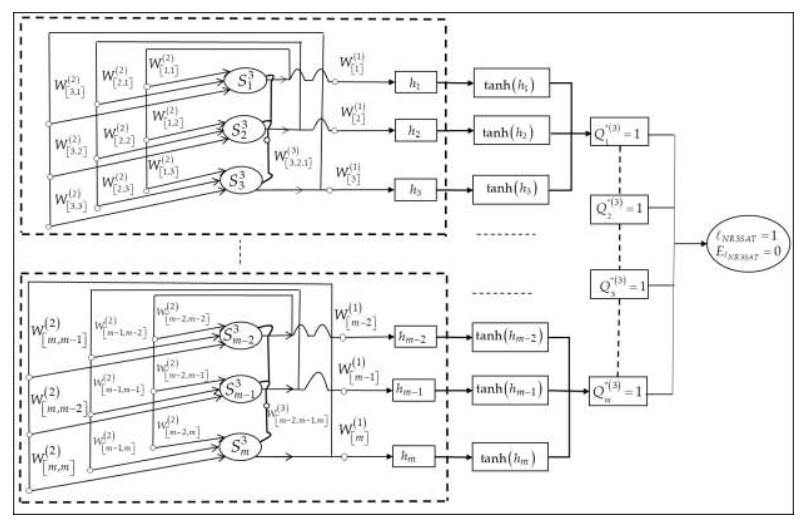
The current systematic logical rules in the Discrete Hopfield Neural Network encounter significant challenges, including repetitive final neuron states that lead to the issue of overfitting. Furthermore, the systematic logical rules neglect the impact on the appearance of negative literals within the logical structure, and most recent efforts have primarily focused on improving the learning capabilities of the network, which could potentially limit its overall efficiency. To tackle the limitation, we introduced a Negative Based Higher Order Systematic Logic to the network, imposing restriction on the appearance of negative literals within the clauses. Additionally, a Hybrid Black Hole Algorithm was proposed in the retrieval phase to optimize the final neuron states. This ensured that the optimized states achieved maximum diversity and reach global minima solutions with the lowest similarity index, thereby enhancing the overall performance of the network. The results illustrated that the proposed model can achieve up to 10,000 diversified and global solutions with an average similarity index of 0.09. The findings indicated that the optimized final neuron states are in optimal configurations. Based on the findings, the development of the new systematic SAT and the implementation of the Hybrid Black Hole algorithm to optimize the retrieval capabilities of DHNN to achieve multi-objective functions result in updated final neuron states with high diversity, high attainment of global minima solutions, and produces states with a low similarity index. Consequently, this proposed model could be extended for logic mining applications to tackle classification tasks. The optimized final neuron states will enhance the retrieval of high-quality induced logic, which is effective for classification and knowledge extraction.
Citation: Nur 'Afifah Rusdi, Nur Ezlin Zamri, Mohd Shareduwan Mohd Kasihmuddin, Nurul Atiqah Romli, Gaeithry Manoharam, Suad Abdeen, Mohd. Asyraf Mansor. Synergizing intelligence and knowledge discovery: Hybrid black hole algorithm for optimizing discrete Hopfield neural network with negative based systematic satisfiability[J]. AIMS Mathematics, 2024, 9(11): 29820-29882. doi: 10.3934/math.20241444
The current systematic logical rules in the Discrete Hopfield Neural Network encounter significant challenges, including repetitive final neuron states that lead to the issue of overfitting. Furthermore, the systematic logical rules neglect the impact on the appearance of negative literals within the logical structure, and most recent efforts have primarily focused on improving the learning capabilities of the network, which could potentially limit its overall efficiency. To tackle the limitation, we introduced a Negative Based Higher Order Systematic Logic to the network, imposing restriction on the appearance of negative literals within the clauses. Additionally, a Hybrid Black Hole Algorithm was proposed in the retrieval phase to optimize the final neuron states. This ensured that the optimized states achieved maximum diversity and reach global minima solutions with the lowest similarity index, thereby enhancing the overall performance of the network. The results illustrated that the proposed model can achieve up to 10,000 diversified and global solutions with an average similarity index of 0.09. The findings indicated that the optimized final neuron states are in optimal configurations. Based on the findings, the development of the new systematic SAT and the implementation of the Hybrid Black Hole algorithm to optimize the retrieval capabilities of DHNN to achieve multi-objective functions result in updated final neuron states with high diversity, high attainment of global minima solutions, and produces states with a low similarity index. Consequently, this proposed model could be extended for logic mining applications to tackle classification tasks. The optimized final neuron states will enhance the retrieval of high-quality induced logic, which is effective for classification and knowledge extraction.

| [1] |
M. Nakıp, E. Çakan, V. Rodoplu, C. Güzeliş, Dynamic automatic forecaster selection via artificial neural network based emulation to enable massive access for the Internet of Things, J. Netw. Comput. Appl., 201 (2022), 103360. https://doi.org/10.1016/j.jnca.2022.103360 doi: 10.1016/j.jnca.2022.103360

|
| [2] |
H. Azgomi, F. R. Haredasht, M. R. S. Motlagh, Diagnosis of some apple fruit diseases by using image processing and artificial neural network, Food Control, 145 (2023), 109484. https://doi.org/10.1016/j.foodcont.2022.109484 doi: 10.1016/j.foodcont.2022.109484
|
| [3] |
G. Dede, M. H. Sazlı, Speech recognition with artificial neural networks, Digit. Signal Prog., 20 (2010), 763–768. https://doi.org/10.1016/j.dsp.2009.10.004 doi: 10.1016/j.dsp.2009.10.004
|
| [4] |
O. Surakhi, M. A. Zaidan, P. L. Fung, N. H. Motlagh, S. Serhan, M. AlKhanafseh, et al., Time-lag selection for time-series forecasting using neural network and heuristic algorithm, Electronics, 10 (2021), 2518. https://doi.org/10.3390/electronics10202518 doi: 10.3390/electronics10202518
|
| [5] |
G. D'Angelo, F. Palmieri, Network traffic classification using deep convolutional recurrent autoencoder neural networks for spatial–temporal features extraction, J. Netw. Comput. Appl., 173 (2021), 102890. https://doi.org/10.1016/j.jnca.2020.102890 doi: 10.1016/j.jnca.2020.102890
|
| [6] |
N. Ahad, J. Qadir, N. Ahsan, Neural networks in wireless networks: Techniques, applications and guidelines, J. Netw. Comput. Appl., 68 (2016), 1–27. https://doi.org/10.1016/j.jnca.2016.04.006 doi: 10.1016/j.jnca.2016.04.006
|
| [7] |
J. J. Hopfield, D. W. Tank, "Neural" computation of decisions in optimization problems, Biol. Cybern., 52 (1985), 141–152. https://doi.org/10.1007/BF00339943 doi: 10.1007/BF00339943
|
| [8] |
Y. Guo, M. S. M. Kasihmuddin, Y. Gao, M. A. Mansor, H. A. Wahab, N. E. Zamri, et al., YRAN2SAT: A novel flexible random satisfiability logical rule in discrete hopfield neural network, Adv. Eng. Softw., 171 (2022), 103169. https://doi.org/10.1016/j.advengsoft.2022.103169 doi: 10.1016/j.advengsoft.2022.103169
|
| [9] |
C. Hu, Y. Ma, T. Chen, Application on online process learning evaluation based on optimal discrete hopfield neural network and entropy weight TOPSIS method, Complexity, 2021 (2021), 2857244. https://doi.org/10.1155/2021/2857244 doi: 10.1155/2021/2857244
|
| [10] |
L. Hu, F. Sun, H. Xu, H. Liu, X. Zhang, Mutation Hopfield neural network and its applications, Inf. Sci., 181 (2011), 92–105. https://doi.org/10.1016/j.ins.2010.08.007 doi: 10.1016/j.ins.2010.08.007
|
| [11] |
W. A. T. W. Abdullah, Logic programming on a neural network, Int. J. Intell. Syst., 7 (1992), 513–519. https://doi.org/10.1002/int.4550070604 doi: 10.1002/int.4550070604
|
| [12] |
M. S. M. Kasihmuddin, M. A. Mansor, S. Sathasivam, Hybrid genetic algorithm in the hopfield network for logic satisfiability problem, Pertanika J. Sci. Technol., 25 (2017). https://doi.org/10.1063/1.4995911 doi: 10.1063/1.4995911
|
| [13] |
S. Sathasivam, M. A. Mansor, A. I. M. Ismail, S. Z. M. Jamaludin, M. S. M. Kasihmuddin, M. Mamat, Novel random k satisfiability for k ≤ 2 in hopfield neural network, Sains Malays., 49 (2020), 2847–2857. https://doi.org/10.17576/jsm-2020-4911-23 doi: 10.17576/jsm-2020-4911-23
|
| [14] |
S. A. Karim, N. E. Zamri, A. Alway, M. S. M. Kasihmuddin, A. I. M. Ismail, M. A. Mansor, et al., Random satisfiability: A higher-order logical approach in discrete hopfield neural network, IEEE Access, 9 (2021), 50831–50845. https://doi.org/10.1109/ACCESS.2021.3068998 doi: 10.1109/ACCESS.2021.3068998
|
| [15] |
A. Alway, N. E. Zamri, S. A. Karim, M. A. Mansor, M. S. M. Kasihmuddin, M. M. Bazuhair, Major 2 satisfiability logic in discrete hopfield neural network, Int. J. Comput. Math., 99 (2022), 924–948. https://doi.org/10.1080/00207160.2021.1939870 doi: 10.1080/00207160.2021.1939870
|
| [16] |
N. E. Zamri, S. A. Azhar, M. A. Mansor, A. Alway, M. S. M. Kasihmuddin, Weighted random k satisfiability for k = 1, 2 (r2SAT) in discrete hopfield neural network, Appl. Soft Comput., 126 (2022), 109312. https://doi.org/10.1016/j.asoc.2022.109312 doi: 10.1016/j.asoc.2022.109312
|
| [17] |
M. A. Mansor, M. S. M. Kasihmuddin, S. Sathasivam, Artificial immune system paradigm in the hopfield network for 3-satisfiability problem, Pertanika J. Sci. Technol., 25 (2017). https://doi.org/10.9781/ijimai.2017.448 doi: 10.9781/ijimai.2017.448
|
| [18] |
L. C. Kho, M. S. M. Kasihmuddin, M. A. Mansor, S. Sathasivam, Propositional Satisfiability Logic via Ant Colony Optimization in Hopfield Neural Network, Malays. J. Math. Sci, 16 (2022), 37–53. https://doi.org/10.47836/mjms.16.1.04 doi: 10.47836/mjms.16.1.04
|
| [19] |
M. S. M. Kasihmuddin, M. A. Mansor, S. Sathasivam, Robust artificial bee colony in the hopfield network for 2-satisfiability problem, Pertanika J. Sci. Technol., 25 (2017). https://doi.org/10.1063/1.4995911 doi: 10.1063/1.4995911
|
| [20] |
M. A. Mansor, M. S. M. Kasihmuddin, S. Sathasivam, Grey wolf optimization algorithm with discrete hopfield neural network for 3 Satisfiability analysis, J. Phys. Conf. Ser., 1821 (2021), 012038. https://doi.org/10.1088/1742-6596/1821/1/012038 doi: 10.1088/1742-6596/1821/1/012038
|
| [21] |
M. S. M. Kasihmuddin, M. A. Mansor, M. F. M. Basir, S. Sathasivam, Discrete mutation Hopfield neural network in propositional satisfiability, Mathematics, 7 (2019), 1133. https://doi.org/10.3390/math7111133 doi: 10.3390/math7111133
|
| [22] |
A. Hatamlou, Black hole: A new heuristic optimization approach for data clustering, Inf. Sci., 222 (2013), 175–184. https://doi.org/10.1016/j.ins.2012.08.023 doi: 10.1016/j.ins.2012.08.023
|
| [23] |
W. Xie, J. S. Wang, C. Xing, S. S. Guo, M. W. Guo, L. F. Zhu, Extreme learning machine soft-sensor model with different activation functions on grinding process optimized by improved black hole algorithm, IEEE Access, 8 (2020), 25084–25110. https://doi.org/10.1109/ACCESS.2020.2970429 doi: 10.1109/ACCESS.2020.2970429
|
| [24] |
W. Gao, X. Wang, S. Dai, D. Chen, Study on stability of high embankment slope based on black hole algorithm, Environ. Earth Sci., 75 (2016), 1–13. https://doi.org/10.1007/s12665-016-6208-y doi: 10.1007/s12665-016-6208-y
|
| [25] |
M. K. Smail, H. R. E. H. Bouchekara, L. Pichon, H. Boudjefdjouf, A. Amloune, Z. Lacheheb, Non-destructive diagnosis of wiring networks using time domain reflectometry and an improved black hole algorithm, Nondestruct. Test. Eval., 32 (2017), 286–300. https://doi.org/10.1080/10589759.2016.1200576 doi: 10.1080/10589759.2016.1200576
|
| [26] |
E. Pashaei, N. Aydin, Binary black hole algorithm for feature selection and classification on biological data, Appl. Soft. Comput., 56 (2017), 94–106. https://doi.org/10.1016/j.asoc.2017.03.002 doi: 10.1016/j.asoc.2017.03.002
|
| [27] |
J. L. Johnson, A neural network approach to the 3-satisfiability problem, J. Parallel Distrib. Comput., 6 (1989), 435–449. https://doi.org/10.1016/0743-7315(89)90068-3 doi: 10.1016/0743-7315(89)90068-3
|
| [28] |
M. A. F. Roslan, N. E. Zamri, M. A. Mansor, M. S. M. Kasihmuddin, Major 3 Satisfiability logic in Discrete Hopfield Neural Network integrated with multi-objective Election Algorithm, AIMS Math., 8 (2023), 22447–22482. https://doi.org/10.3934/math.20231145 doi: 10.3934/math.20231145
|
| [29] |
A. Alway, N. E. Zamri, M. A. Mansor, M. S. M. Kasihmuddin, S. Z. M. Jamaludin, M. F. Marsani, A novel hybrid exhaustive search and data preparation technique with multi-objective discrete hopfield neural network, Decis. Anal., 9 (2023), 100354. https://doi.org/10.1016/j.dajour.2023.100354 doi: 10.1016/j.dajour.2023.100354
|
| [30] |
F. S. Gharehchopogh, H. Shayanfar, H. Gholizadeh, A comprehensive survey on symbiotic organisms search algorithms, Artif. Intell. Rev., 53 (2020), 2265–2312. https://doi.org/10.1007/s10462-019-09733-4 doi: 10.1007/s10462-019-09733-4
|
| [31] |
D. Karaboga, B. Akay, A comparative study of artificial bee colony algorithm, Appl. Math. Comput., 214 (2009), 108–132. https://doi.org/10.1016/j.amc.2009.03.090 doi: 10.1016/j.amc.2009.03.090
|
| [32] |
F. L. Azizan, S. Sathasivam, M. K. M. Ali, N. Roslan, C. Feng, Hybridised Network of Fuzzy Logic and a Genetic Algorithm in Solving 3-Satisfiability Hopfield Neural Networks, Axioms, 12 (2023), 250. https://doi.org/10.3390/axioms12030250 doi: 10.3390/axioms12030250
|
| [33] |
V. Someetheram, M. F. Marsani, M. S. M. Kasihmuddin, N. E. Zamri, S. S. M. Sidik, S. Z. M. Jamaludin, et al., Random maximum 2 satisfiability logic in discrete hopfield neural network incorporating improved election algorithm, Mathematics, 10 (2022), 4734. https://doi.org/10.3390/math10244734 doi: 10.3390/math10244734
|
| [34] |
S. Sathasivam, M. A. Mansor, M. S. M. Kasihmuddin, H. Abubakar, Election algorithm for random k satisfiability in the hopfield neural network, Processes, 8 (2020), 568. https://doi.org/10.3390/PR8050568 doi: 10.3390/PR8050568
|
| [35] |
S. S. M. Sidik, N. E. Zamri, M. S. M. Kasihmuddin, H. A. Wahab, Y. Guo, M. A. Mansor, Non-systematic weighted satisfiability in discrete hopfield neural network using binary artificial bee colony optimization, Mathematics, 10 (2022), 1129. https://doi.org/10.3390/math10071129 doi: 10.3390/math10071129
|
| [36] |
S. Abdeen, M. S. M. Kasihmuddin, N. E. Zamri, G. Manoharam, M. A. Mansor, N. Alshehri, S-type random k satisfiability logic in discrete hopfield neural network using probability distribution: Performance optimization and analysis, Mathematics, 11 (2023), 984. https://doi.org/10.3390/math11040984 doi: 10.3390/math11040984
|
| [37] |
J. Chen, M. S. M. Kasihmuddin, Y. Gao, Y. Guo, M. A. Mansor, N. A. Romli, et al., PRO2SAT: Systematic probabilistic satisfiability logic in discrete hopfield neural network, Adv. Eng. Softw., 175 (2023), 103355. https://doi.org/10.1016/j.advengsoft.2022.103355 doi: 10.1016/j.advengsoft.2022.103355
|
| [38] | S. Sathasivam, Upgrading logic programming in Hopfield network, Sains Malays., 39 (2010), 115–118. |
| [39] |
H. Abubakar, M. L. Danrimi, Hopfield type of artificial neural network via election algorithm as heuristic search method for random boolean ksatisfiability, Int. J. comput. Digit. Syst., 10 (2021), 659–673. https://doi.org/10.12785/ijcds/100163 doi: 10.12785/ijcds/100163
|
| [40] |
S. Mirjalili, A. Lewis, S-shaped versus Ⅴ-shaped transfer functions for binary particle swarm optimization, Swarm Evol. Comput., 9 (2013), 1–14. https://doi.org/10.1016/j.swevo.2012.09.002 doi: 10.1016/j.swevo.2012.09.002
|
| [41] |
Y. Gao, Y. Guo, N. A. Romli, M. S. M. Kasihmuddin, W. Chen, M. A. Mansor, et al., GRAN3SAT: Creating flexible higher-order logic satisfiability in the discrete hopfield neural network, Mathematics, 10 (2022), 1899. https://doi.org/10.3390/math10111899 doi: 10.3390/math10111899
|
| [42] |
N. Roslan, S. Sathasivam, F. L. Azizan, Conditional random k satisfiability modeling for k = 1, 2 (CRAN2SAT) with non-monotonic Smish activation function in discrete Hopfield neural network, AIMS Math., 9 (2024), 3911–3956. https://doi.org/10.3934/math.2024193 doi: 10.3934/math.2024193
|
| [43] |
M. M. Bazuhair, S. Z. M. Jamaludin, N. E. Zamri, M. S. M. Kasihmuddin, M. A. Mansor, A. Alway, et al., Novel Hopfield neural network model with election algorithm for random 3 satisfiability, Processes, 9 (2021), 1292. https://doi.org/10.3390/pr9081292 doi: 10.3390/pr9081292
|
| [44] |
S. Taghian, M. H. Nadimi-Shahraki, Binary Sine Cosine Algorithms for Feature Selection from Medical Data, Adv. Comput. Int. J., 10 (2019). https://doi.org/10.5121/acij.2019.10501 doi: 10.5121/acij.2019.10501
|
| [45] |
S. Chakraborty, A. K. Saha, S. Sharma, S. Mirjalili, R. Chakraborty, A novel enhanced whale optimization algorithm for global optimization, Comput. Ind. Eng., 153 (2021), 107086. https://doi.org/10.1016/j.cie.2020.107086 doi: 10.1016/j.cie.2020.107086
|
| [46] |
A. G. Hussien, A. E. Hassanien, E. H. Houssein, M. Amin, A. T. Azar, New binary whale optimization algorithm for discrete optimization problems, Eng. Optimiz., 52 (2020), 945–959. https://doi.org/10.1080/0305215X.2019.1624740 doi: 10.1080/0305215X.2019.1624740
|
| [47] |
N. E. Zamri, M. A. Mansor, M. S. M. Kasihmuddin, A. Alway, S. Z. M. Jamaludin, S. A. Alzaeemi, Amazon employees resources access data extraction via clonal selection algorithm and logic mining approach, Entropy, 22 (2020), 596. https://doi.org/10.3390/E22060596 doi: 10.3390/E22060596
|
| [48] |
L. Wang, X. Fu, Y. Mao, M. I. Menhas, M. Fei, A novel modified binary differential evolution algorithm and its applications, Neurocomputing, 98 (2012), 55–75. https://doi.org/10.1016/j.neucom.2011.11.033 doi: 10.1016/j.neucom.2011.11.033
|
| [49] |
D. Jia, X. Duan, M. K. Khan, Binary Artificial Bee Colony optimization using bitwise operation, Comput. Ind. Eng., 76 (2014), 360–365. https://doi.org/10.1016/j.cie.2014.08.016 doi: 10.1016/j.cie.2014.08.016
|
| [50] |
A. G. Hussien, D. Oliva, E. H. Houssein, A. A. Juan, X. Yu, Binary whale optimization algorithm for dimensionality reduction, Mathematics, 8 (2020), 1821. https://doi.org/10.3390/math8101821 doi: 10.3390/math8101821
|
| [51] |
S. A. Karim, M. S. M. Kasihmuddin, S. Sathasivam, M. A. Mansor, S. Z. M. Jamaludin, M. R. Amin, A novel multi-objective hybrid election algorithm for higher-order random satisfiability in discrete hopfield neural network, Mathematics, 10 (2022), 1963. https://doi.org/10.3390/math10121963 doi: 10.3390/math10121963
|
| [52] |
N. A. Rusdi, M. S. M. Kasihmuddin, N. A. Romli, G. Manoharam, M. A. Mansor, Multi-unit discrete hopfield neural network for higher order supervised learning through logic mining: Optimal performance design and attribute selection, J. King Saud Univ.–Com., 35 (2023), 101554. https://doi.org/10.1016/j.jksuci.2023.101554 doi: 10.1016/j.jksuci.2023.101554
|
| [53] |
M. S. M. Kasihmuddin, S. Z. M. Jamaludin, M. A. Mansor, H. A. Wahab, S. M. S. Ghadzi, Supervised learning perspective in logic mining, Mathematics, 10 (2022), 915. https://doi.org/10.3390/math10060915 doi: 10.3390/math10060915
|
| [54] |
C. Wang, H. Zhang, D. Wen, M. Shen, L. Li, Z. Zhang, Novel passivity and dissipativity criteria for discrete-time fractional generalized delayed Cohen–Grossberg neural networks, Commun. Nonlinear Sci. Numer. Simul., 133 (2024), 107960. https://doi.org/10.1016/j.cnsns.2024.107960 doi: 10.1016/j.cnsns.2024.107960
|
| [55] |
X. Wang, H. R. Karimi, M. Shen, D. Liu, L. W. Li, J. Shi, Neural network-based event-triggered data-driven control of disturbed nonlinear systems with quantized input, Neural Netw., 156 (2022), 152–159. https://doi.org/10.1016/j.neunet.2022.09.021 doi: 10.1016/j.neunet.2022.09.021
|















Figures(16) / Tables(29)

Nur 'Afifah Rusdi, Nur Ezlin Zamri, Mohd Shareduwan Mohd Kasihmuddin, Nurul Atiqah Romli, Gaeithry Manoharam, Suad Abdeen, Mohd. Asyraf Mansor. Synergizing intelligence and knowledge discovery: Hybrid black hole algorithm for optimizing discrete Hopfield neural network with negative based systematic satisfiability[J]. AIMS Mathematics, 2024, 9(11): 29820-29882. doi: 10.3934/math.20241444







 DownLoad:
DownLoad: