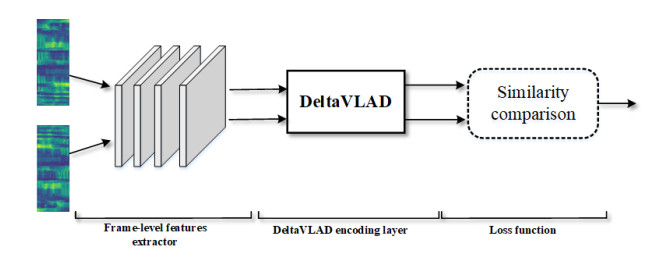
Text-independent speaker verification aims to determine whether two given utterances in open-set task originate from the same speaker or not. In this paper, some ways are explored to enhance the discrimination of embeddings in speaker verification. Firstly, difference is used in the coding layer to process speaker features to form the DeltaVLAD layer. The frame-level speaker representation is extracted by the deep neural network with differential operations to calculate the dynamic changes between frames, which is more conducive to capturing insignificant changes in the voiceprint. Meanwhile, NeXtVLAD is adopted to split the frame-level features into multiple word spaces before aggregating, and subsequently perform VLAD operations in each subspace, which can significantly reduce the number of parameters and improve performance. Secondly, the margin-based softmax loss function and the few-shot learning-based loss function are proposed to be combined for more discriminative speaker embeddings. Finally, for a fair comparison, the experimental results are performed on Voxceleb-1 showing superior performance of speaker verification system and can obtain new state-of-the-art results.
Citation: Xin Guo, Chengfang Luo, Aiwen Deng, Feiqi Deng. DeltaVLAD: An efficient optimization algorithm to discriminate speaker embedding for text-independent speaker verification[J]. AIMS Mathematics, 2022, 7(4): 6381-6395. doi: 10.3934/math.2022355
Text-independent speaker verification aims to determine whether two given utterances in open-set task originate from the same speaker or not. In this paper, some ways are explored to enhance the discrimination of embeddings in speaker verification. Firstly, difference is used in the coding layer to process speaker features to form the DeltaVLAD layer. The frame-level speaker representation is extracted by the deep neural network with differential operations to calculate the dynamic changes between frames, which is more conducive to capturing insignificant changes in the voiceprint. Meanwhile, NeXtVLAD is adopted to split the frame-level features into multiple word spaces before aggregating, and subsequently perform VLAD operations in each subspace, which can significantly reduce the number of parameters and improve performance. Secondly, the margin-based softmax loss function and the few-shot learning-based loss function are proposed to be combined for more discriminative speaker embeddings. Finally, for a fair comparison, the experimental results are performed on Voxceleb-1 showing superior performance of speaker verification system and can obtain new state-of-the-art results.

| [1] |
A. Nagrani, J. S. Chung, A. Zisserman, Voxceleb: A large-scale speaker identification dataset, Proc. Interspeech, 2017, 2616-2620. https://doi.org/10.21437/Interspeech.2017-950 doi: 10.21437/Interspeech.2017-950

|
| [2] |
J. S. Chung, A. Nagrani, A. Zisserman, Voxceleb2: Deep speaker recognition, Proc. Interspeech, 2018, 1086-1090. https://doi.org/10.21437/Interspeech.2018-1929 doi: 10.21437/Interspeech.2018-1929
|
| [3] |
D. A. Reynolds, R. Rose, Robust text-independent speaker identification using gaussian mixture speaker models, IEEE T. Speech Audio Processing, 3 (1995), 72-83. https://doi.org/10.1109/89.365379 doi: 10.1109/89.365379
|
| [4] | T. F. Zheng, L. T. Li, Robustness-related issues in speaker recognition, Singapore: Springer, 2017. https://doi.org/10.1007/978-981-10-3238-7 |
| [5] |
D. A. Reynolds, T. F. Quatieri, R. B. Dunn, Speaker verification using adapted gaussian mixture models, Digit. Signal Process., 10 (2000), 19-41. https://doi.org/10.1006/dspr.1999.0361 doi: 10.1006/dspr.1999.0361
|
| [6] |
F. Richardson, D. Reynolds, N. Dehak, Deep neural network approaches to speaker and language recognition, IEEE Signal Proc. Let., 22 (2015), 1671-1675. https://doi.org/10.1109/LSP.2015.2420092 doi: 10.1109/LSP.2015.2420092
|
| [7] |
D. Snyder, D. Garcia-Romero, D. Povey, S. Khudanpur, Deep neural network embeddings for text-independent speaker verification, Proc. Interspeech, 2017,999-1003. https://doi.org/10.21437/Interspeech.2017-620 doi: 10.21437/Interspeech.2017-620
|
| [8] | J. Jung, H. S. Heo, J. Kim, H. Shim, H. J. Yu, RawNet: Advanced end-to-end deep neural network using raw waveforms for text-independent speaker verification, arXiv, 2019. Available from: https://arXiv.org/abs/1904.08104. |
| [9] | T. Ko, Y. Chen, Q. Li, Prototypical networks for small footprint text-independent speaker verification, In: 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, 6804-6808. https://doi.org/10.1109/ICASSP40776.2020.9054471 |
| [10] |
Y. Liu, L. He, J. Liu, Large margin softmax loss for speaker verification, Proc. Interspeech, 2019. 2873-2877. https://doi.org/10.21437/Interspeech.2019-2357 doi: 10.21437/Interspeech.2019-2357
|
| [11] |
Y. F. Wu, C. Guo, H. Gao, X. Hou, J. Xu, Vector-based attentive pooling for text-independent speaker verification, Proc. Interspeech, 2020,936-940. https://doi.org/10.21437/Interspeech.2020-1422 doi: 10.21437/Interspeech.2020-1422
|
| [12] |
S. B. Kim, J. W. Jung, H. J. Shim, J. H. Kim, H. J. Yu, Segment aggregation for short utterances speaker verification using raw waveforms, Proc. Interspeech, 2020, 1521-1525. https://doi.org/10.21437/Interspeech.2020-1564 doi: 10.21437/Interspeech.2020-1564
|
| [13] | C. F. Luo, X. Guo, A. W. Deng, W. Xu, J. H. Zhao, W. X. Kang, Learning discriminative speaker embedding by improving aggregation strategy and loss function for speaker verification, In: 2021 IEEE International Joint Conference on Biometrics (IJCB), 2021, 1-8. https://doi.org/10.1109/IJCB52358.2021.9484331 |
| [14] | E. Variani, X. Lei, E. McDermott, I. L. Moreno, J. Gonzalez-Dominguez, Deep neural networks for small footprint text-dependent speaker verification, In: 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014, 4052-4056. https://doi.org/10.1109/ICASSP.2014.6854363 |
| [15] |
B. Desplanques, J. Thienpondt, K. Demuynck, ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification, Proc. Interspeech, 2020, 3830-3834. https://doi.org/10.21437/Interspeech.2020-2650 doi: 10.21437/Interspeech.2020-2650
|
| [16] | A. Senior, H. Sak, I. Shafran, Context dependent phone models for LSTM RNN acoustic modelling, In: 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, 4585-4589. https://doi.org/10.1109/ICASSP.2015.7178839 |
| [17] | W. C. Cai, J. K. Chen, M. Li, Exploring the encoding layer and loss function in end-to-end speaker and language recognition system, arXiv, 2018. Available from: https://arXiv.org/abs/1804.05160. |
| [18] | K. Okabe, T. Koshinaka, K. Shinoda, Attentive statistics pooling for deep speaker embedding, arXiv, 2018. Available from: https://arXiv.org/abs/1803.10963. |
| [19] | Y. Zhong, R. Arandjelović, A. Zisserman, GhostVLAD for set-based face recognition, In: Asian conference on computer vision, Springer, Cham, 2018, 35-50. https://doi.org/10.1007/978-3-030-20890-5_3 |
| [20] | W. Xie, A. Nagrani, J. S. Chung, A. Zisserman, Utterance-level aggregation for speaker recognition in the wild, In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, 5791-5795. https://doi.org/10.1109/ICASSP.2019.8683120 |
| [21] | R. Lin, J. Xiao, J. Fan, NEXTVLAD: An efficient neural network to aggregate frame-level features for large-scale video classification, In: Proceedings of the European Conference on Computer Vision (ECCV) Workshops, 2018. |
| [22] | C. Zhang, Y. X. Zou, G. Chen, L. Gan, PAN: Towards fast action recognition via learning persistence of appearance. arXiv, 2020. Available from: https://arXiv.org/abs/2008.03462. |
| [23] | Y. Liu, L. He, J. Liu, Large margin softmax loss for speaker verification, arXiv, 2019. Available from: https://arXiv.org/abs/1904.03479. |
| [24] | P. Anand, A. K. Singh, S. Srivastava, B. Lall, Few shot speaker recognition using deep neural networks, arXiv, 2019. Available from: https://arXiv.org/abs/1904.08775. |
| [25] | L. Wan, Q. Wang, A. Papir, I. L. Moreno, Generalized end-to-end loss for speaker verification, In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, 4879-4883. https://doi.org/10.1109/ICASSP.2018.8462665 |
| [26] | S. M. Kye, Y. Jung, H. B. Lee, S. J. Hwang, H. Kim, Meta-learning for short utterance speaker recognition with imbalance length pairs, arXiv, 2020. Available from: https://arXiv.org/abs/2004.02863. |
| [27] | S. M. Kye, Y. Kwon, J. S. Chung, Cross attentive pooling for speaker verification, In: 2021 IEEE Spoken Language Technology Workshop (SLT), 2021,294-300. https://doi.org/10.1109/SLT48900.2021.9383565 |
| [28] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, 7132-7141. |
| [29] | J. S. Chung, J. Huh, S. Mun, M. Lee, H. S. Heo, S. Choe, et al., In defence of metric learning for speaker recognition, arXiv, 2020. Available from: https://arXiv.org/abs/2003.11982. |
| [30] |
F. Wang, J. Cheng, W. Liu, H. Liu, Additive margin softmax for face verification, IEEE Signal Proc. Let., 25 (2018), 926-930. https://doi.org/10.1109/LSP.2018.2822810 doi: 10.1109/LSP.2018.2822810
|
| [31] | J. Deng, J. Guo, N. Xue, S. Zafeiriou, Arcface: Additive angular margin loss for deep face recognition, In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, 4690-4699. |
| [32] | J. Snell, K. Swersky, R. S. Zemel, Prototypical networks for few-shot learning, arXiv, 2017. Available from: https://arXiv.org/abs/1703.05175. |
| [33] | Y. Jung, S. M. Kye, Y. Choi, M. Jung, H. Kim, Improving multi-scale aggregation using feature pyramid module for robust speaker verification of variable-duration utterances, arXiv, 2004. Available from: https://arXiv.org/abs/2004.03194. |
| [34] | S. M. Kye, J. S. Chung, H. Kim, Supervised attention for speaker recognition, In: 2021 IEEE Spoken Language Technology Workshop (SLT), 2021,286-293. https://doi.org/10.1109/SLT48900.2021.9383579 |
| [35] |
M. Rybicka, K. Kowalczyk, On parameter adaptation in softmax-based cross-entropy loss for improved convergence speed and accuracy in DNN-based speaker eecognition, Proc. Interspeech, 2020, 3805-3809. https://doi.org/10.21437/Interspeech.2020-2264 doi: 10.21437/Interspeech.2020-2264
|




Figures(5) / Tables(5)

Xin Guo, Chengfang Luo, Aiwen Deng, Feiqi Deng. DeltaVLAD: An efficient optimization algorithm to discriminate speaker embedding for text-independent speaker verification[J]. AIMS Mathematics, 2022, 7(4): 6381-6395. doi: 10.3934/math.2022355







 DownLoad:
DownLoad: