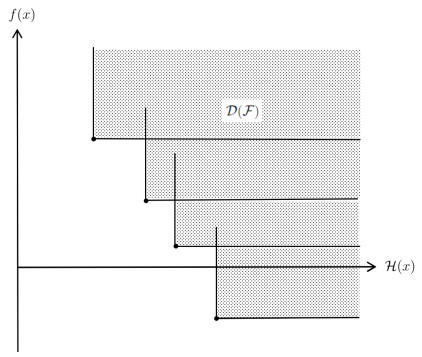
In this paper, we define a new area-type filter algorithm based on the trust-region method. A relaxed trust-region quadratic correction subproblem is proposed to compute the trial direction at the current point. Consider the objective function and the constraint violation function at the current point as a point pair. We divide the point pairs into different partitions by the dominant region of the filter and calculate the contributions of the point pairs to the area of the filter separately. Different from the conventional filter, we define the contribution as the filter acceptance criterion for the trial point. The nonmonotone area-average form is also adopted in the filter mechanism. In this paper, monotone and nonmonotone methods are proposed and compared with the numerical values. Furthermore, the algorithm is proved to be convergent under some reasonable assumptions. The numerical experiment shows the effectiveness of the algorithm.
Citation: Ke Su, Wei Lu, Shaohua Liu. An area-type nonmonotone filter method for nonlinear constrained optimization[J]. AIMS Mathematics, 2022, 7(12): 20441-20460. doi: 10.3934/math.20221120
In this paper, we define a new area-type filter algorithm based on the trust-region method. A relaxed trust-region quadratic correction subproblem is proposed to compute the trial direction at the current point. Consider the objective function and the constraint violation function at the current point as a point pair. We divide the point pairs into different partitions by the dominant region of the filter and calculate the contributions of the point pairs to the area of the filter separately. Different from the conventional filter, we define the contribution as the filter acceptance criterion for the trial point. The nonmonotone area-average form is also adopted in the filter mechanism. In this paper, monotone and nonmonotone methods are proposed and compared with the numerical values. Furthermore, the algorithm is proved to be convergent under some reasonable assumptions. The numerical experiment shows the effectiveness of the algorithm.

| [1] |
J. C. Tang, C. M. Fu, C. J. Mi, H. B. Liu, An interval sequential linear programming for nonlinear robust optimization problems, Appl. Math. Model., 107 (2022), 256–274. https://doi.org/10.1016/j.apm.2022.02.037 doi: 10.1016/j.apm.2022.02.037

|
| [2] |
M. D. Yang, D. Q. Zhang, X. Han, New efficient and robust method for structural reliability analysis and its application in reliability-based design optimization, Comput. Method. Appl. Mech. Eng., 366 (2020), 113018. https://doi.org/10.1016/j.cma.2020.113018 doi: 10.1016/j.cma.2020.113018
|
| [3] |
M. D. Yang, D. Q. Zhang, C. Jiang, X. Han, Q. Li, A hybrid adaptive Kriging-based single loop approach for complex reliability-based design optimization problems, Reliab. Eng. Syst. Safe., 215 (2022), 107736. https://doi.org/10.1016/j.ress.2021.107736 doi: 10.1016/j.ress.2021.107736
|
| [4] |
N. C. Xiao, K. Yuan, C. N. Zhou, Adaptive kriging-based efficient reliability method for structural systems with multiple failure modes and mixed variables, Comput. Method. Appl. Mech. Eng., 359 (2020), 112649. https://doi.org/10.1016/j.cma.2019.112649 doi: 10.1016/j.cma.2019.112649
|
| [5] |
F. E. Curtis, N. I. M. Gould, D. P. Robinson, P. L. Toint, An interior-point trust-funnel algorithm for nonlinear optimization, Math. Program., 161 (2017), 73–134. https://doi.org/10.1007/s10107-016-1003-9 doi: 10.1007/s10107-016-1003-9
|
| [6] |
C. Gu, D. T. Zhu, Global and local convergence of a new affine scaling trust region algorithm for linearly constrained optimization, Acta Math. Sin.-English Ser., 32 (2016), 1203–1213. https://doi.org/10.1007/s10114-016-4513-8 doi: 10.1007/s10114-016-4513-8
|
| [7] |
K. Su, X. C. Li, R. Y. Hou, A nonmonotone flexible filter method for nonlinear constrained optimization, J. Math. Industry, 6 (2016), 8. https://doi.org/10.1186/s13362-016-0029-1 doi: 10.1186/s13362-016-0029-1
|
| [8] |
X. J. Zhu, On a globally convergent trust region algorithm with infeasibility control for equality constrained optimization, J. Appl. Math. Comput., 50 (2016), 275–298. https://doi.org/10.1007/s12190-015-0870-1 doi: 10.1007/s12190-015-0870-1
|
| [9] |
M. J. D. Powell, On the convergence of trust region algorithms for unconstrained minimization without derivatives, Comput. Optim. Appl., 53 (2012), 527–555. https://doi.org/10.1007/s10589-012-9483-x doi: 10.1007/s10589-012-9483-x
|
| [10] |
X. F. Ding, Q. Qu, X. Y. Wang, A modified filter nonmonotone adaptive retrospective trust region method, PLoS ONE, 16 (2021), e0253016. https://doi.org/10.1371/journal.pone.0253016 doi: 10.1371/journal.pone.0253016
|
| [11] |
A. Kamandi, K. Amini, A new nonmonotone adaptive trust region algorithm, Appl. Math., 67 (2022), 233–250. https://doi.org/10.21136/AM.2021.0122-20 doi: 10.21136/AM.2021.0122-20
|
| [12] |
J. J. Liu, X. M. Xu, X. H. Cui, An accelerated nonmonotone trust region method with adaptive trust region for unconstrained optimization, Comput. Optim. Appl., 69 (2018), 77–97. https://doi.org/10.1007/s10589-017-9941-6 doi: 10.1007/s10589-017-9941-6
|
| [13] |
I. S. Duff, J. Nocedal, J. K. Reid, The use of linear programming for the solution of sparse sets of nonlinear equations, SIAM J. Sci. Stat. Comput., 8 (1987), 99–108. https://doi.org/10.1137/0908024 doi: 10.1137/0908024
|
| [14] |
J. Y. Fan, J. Y. Pan, An improved trust region algorithm for nonlinear equations, Comput. Optim. Appli., 48 (2011), 59–70. https://doi.org/10.1007/s10589-009-9236-7 doi: 10.1007/s10589-009-9236-7
|
| [15] |
H. C. Zhang, A. R. Conn, K. Scheinberg, A derivative-free algorithm for least-squares minimization, SIAM J. Optim., 20 (2010), 3555–3576. https://doi.org/10.1137/09075531X doi: 10.1137/09075531X
|
| [16] |
C. Cartis, N. I. Gould, P. L.Toint, Trust-region and other regularisations of linear least-squares problems, Bit. Numer. Math., 49 (2009), 21–53. https://doi.org/10.1007/s10543-008-0206-8 doi: 10.1007/s10543-008-0206-8
|
| [17] |
S. A. Karbasy, M. Salahi, On the branch and bound algorithm for the extended trust-region subproblem, J. Glob. Optim., 83 (2022), 221–233. https://doi.org/10.1007/s10898-021-01104-0 doi: 10.1007/s10898-021-01104-0
|
| [18] |
C. Kanzow, A. Klug, An interior-point affine-scaling trust-region method for semismooth equations with box constraints, Comput. Optim. Appl., 37 (2007), 329–353. https://doi.org/10.1007/s10589-007-9029-9 doi: 10.1007/s10589-007-9029-9
|
| [19] |
Y. X. Yuan, Recent advances in trust region algorithms, Math. Program., 151 (2015), 249–281. https://doi.org/10.1007/s10107-015-0893-2 doi: 10.1007/s10107-015-0893-2
|
| [20] |
R. Fletcher, S. Leyffer, Nonlinear programming without a penalty function, Math. Program., 91 (2002), 239–269. https://doi.org/10.1007/s101070100244 doi: 10.1007/s101070100244
|
| [21] |
R. Fletcher, S. Leyffer, P. L. Toint, On the global convergence of a filter-SQP algorithm, SIAM J. Optim., 13 (2002), 44–59. https://doi.org/10.1137/S105262340038081X doi: 10.1137/S105262340038081X
|
| [22] |
C. Gu, D. T. Zhu, A dwindling filter algorithm with a modified subproblem for nonlinear inequality constrained optimization, Chin. Ann. Math. Ser. B, 35 (2014), 209–224. https://doi.org/10.1007/s11401-014-0826-z doi: 10.1007/s11401-014-0826-z
|
| [23] |
J. Y. Wang, C. Gu, G. Q. Wang, Some results on the filter method for nonlinear complementary problems, J. Inequal. Appl., 2021 (2021), 30. https://doi.org/10.1186/s13660-021-02558-2 doi: 10.1186/s13660-021-02558-2
|
| [24] |
X. J. Zhu, D. G. Pu, A restoration-free filter SQP algorithm for equality constrained optimization, Appl. Math. Comput., 219 (2013), 6016–6029. https://doi.org/10.1016/j.amc.2012.12.002 doi: 10.1016/j.amc.2012.12.002
|
| [25] |
K. Su, A globally and superlinearly convergent modified SQP-filter method, J. Glob. Optim., 41 (2008), 203–217. https://doi.org/10.1007/s10898-007-9219-0 doi: 10.1007/s10898-007-9219-0
|
| [26] |
H. Ahmadzadeh, N. Mahdavi-Amiri, A competitive inexact nonmonotone filter SQP method: Convergence analysis and numerical results, Optim. Method. Softw., 2021, 1–34. https://doi.org/10.1080/10556788.2021.1913155 doi: 10.1080/10556788.2021.1913155
|
| [27] |
A. Q. Huang, A filter-type method for solving nonlinear semidefinite programming, Appl. Numer. Math., 158 (2020), 415–424. https://doi.org/10.1016/j.apnum.2020.08.012 doi: 10.1016/j.apnum.2020.08.012
|
| [28] |
S. Leyffer, C. Vanaret, An augmented Lagrangian filter method, Math. Meth. Oper. Res., 92 (2020), 343–376. https://doi.org/10.1007/s00186-020-00713-x doi: 10.1007/s00186-020-00713-x
|
| [29] |
K. Su, D. G. Pu, A nonmonotone filter trust region method for nonlinear constrained optimization, J. Comput. Appl. Math., 223 (2009), 230–239. https://doi.org/10.1016/j.cam.2008.01.013 doi: 10.1016/j.cam.2008.01.013
|
| [30] |
X. Y. Wang, X. F. Ding, Q. Qu, A new filter nonmonotone adaptive trust region method for unconstrained optimization, Symmetry, 12 (2020), 208. https://doi.org/10.3390/sym12020208 doi: 10.3390/sym12020208
|
| [31] |
W. J. Xue, W. L. Liu A multidimensional filter SQP algorithm for nonlinear programming, J. Comput. Math., 38 (2020), 683–704. DOI: 10.4208/jcm.1903-m2018-0072 doi: 10.4208/jcm.1903-m2018-0072
|
| [32] | N. I. M. Gould, P. L.Toint, Global convergence of a non-monotone trust-region filter algorithm for nonlinear programming, In: Multiscale optimization methods and applications, Boston, MA: Springer, 2006,125–150. https://doi.org/10.1007/0-387-29550-X_5 |
| [33] |
P. E. Gill, W. Murray, M. A. Saunders, SNOPT: An SQP algorithm for large-scale constrained optimization, SIAM Rev., 47 (2005), 99–131. https://doi.org/10.1137/S0036144504446096 doi: 10.1137/S0036144504446096
|
| [34] |
A. Wächter, L. T. Biegler, On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming, Math. Program., 106 (2006), 25–57. https://doi.org/10.1007/s10107-004-0559-y doi: 10.1007/s10107-004-0559-y
|
| [35] | J. Nocedal, S. Wright, Numerical optimization, New York: Springer, 1999. https://doi.org/10.1007/b98874 |
| [36] |
W. Hock, K. Schittkowski, Test examples for nonlinear programming codes, J. Optim. Theory Appl., 30 (1980), 127–129. https://doi.org/10.1007/BF00934594 doi: 10.1007/BF00934594
|
| [37] | K. Schittkowski, More test examples for nonlinear programming codes, Berlin, Heidelberg: Springer, 1987. https://doi.org/10.1007/978-3-642-61582-5 |
| [38] |
E. D. Dolan, J. J. Moré, Benchmarking optimization software with performance profiles, Math. Program., 91 (2002), 201–213. https://doi.org/10.1007/s101070100263 doi: 10.1007/s101070100263
|




Figures(5) / Tables(2)

Ke Su, Wei Lu, Shaohua Liu. An area-type nonmonotone filter method for nonlinear constrained optimization[J]. AIMS Mathematics, 2022, 7(12): 20441-20460. doi: 10.3934/math.20221120







 DownLoad:
DownLoad: