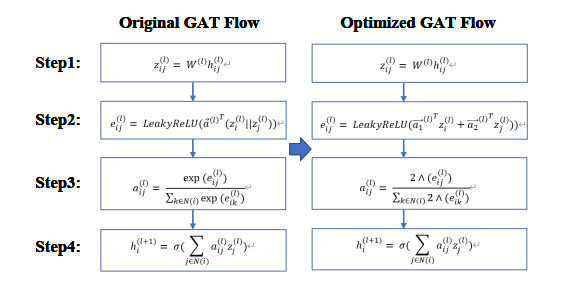
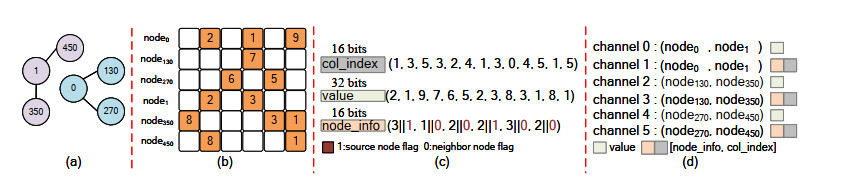
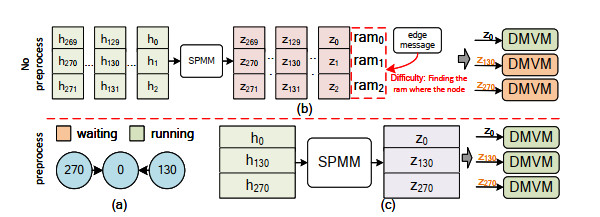
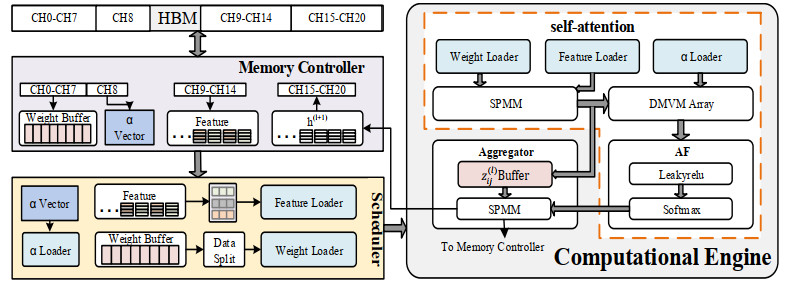
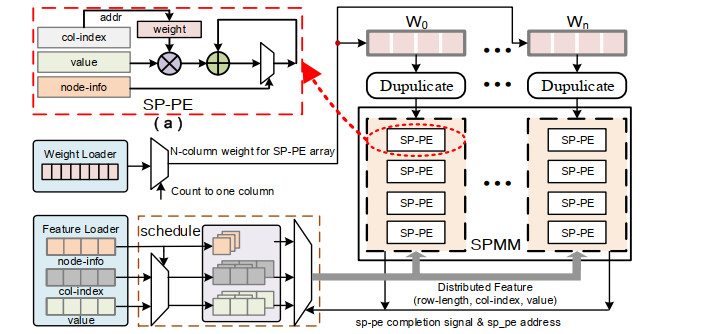
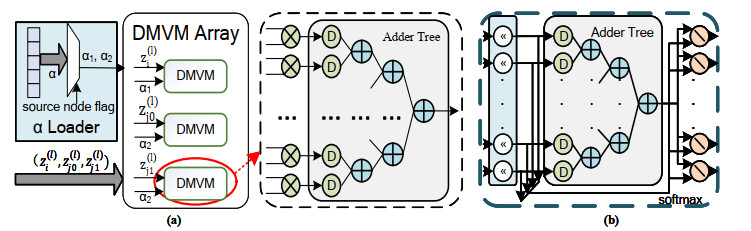
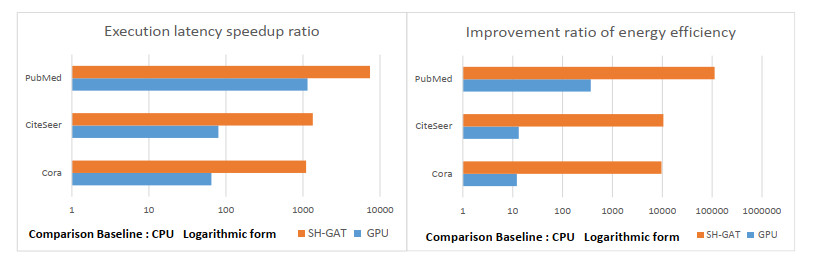
Graph convolution networks (GCN) have demonstrated success in learning graph structures; however, they are limited in inductive tasks. Graph attention networks (GAT) were proposed to address the limitations of GCN and have shown high performance in graph-based tasks. Despite this success, GAT faces challenges in hardware acceleration, including: 1) The GAT algorithm has difficulty adapting to hardware; 2) challenges in efficiently implementing Sparse matrix multiplication (SPMM); and 3) complex addressing and pipeline stall issues due to irregular memory accesses. To this end, this paper proposed SH-GAT, an FPGA-based GAT accelerator that achieves more efficient GAT inference. The proposed approach employed several optimizations to enhance GAT performance. First, this work optimized the GAT algorithm using split weights and softmax approximation to make it more hardware-friendly. Second, a load-balanced SPMM kernel was designed to fully leverage potential parallelism and improve data throughput. Lastly, data preprocessing was performed by pre-fetching the source node and its neighbor nodes, effectively addressing pipeline stall and complexly addressing issues arising from irregular memory access. SH-GAT was evaluated on the Xilinx FPGA Alveo U280 accelerator card with three popular datasets. Compared to existing CPU, GPU, and state-of-the-art (SOTA) FPGA-based accelerators, SH-GAT can achieve speedup by up to 3283$ \times $, 13$ \times $, and 2.3$ \times $.
Citation: Renping Wang, Shun Li, Enhao Tang, Sen Lan, Yajing Liu, Jing Yang, Shizhen Huang, Hailong Hu. SH-GAT: Software-hardware co-design for accelerating graph attention networks on FPGA[J]. Electronic Research Archive, 2024, 32(4): 2310-2322. doi: 10.3934/era.2024105
Graph convolution networks (GCN) have demonstrated success in learning graph structures; however, they are limited in inductive tasks. Graph attention networks (GAT) were proposed to address the limitations of GCN and have shown high performance in graph-based tasks. Despite this success, GAT faces challenges in hardware acceleration, including: 1) The GAT algorithm has difficulty adapting to hardware; 2) challenges in efficiently implementing Sparse matrix multiplication (SPMM); and 3) complex addressing and pipeline stall issues due to irregular memory accesses. To this end, this paper proposed SH-GAT, an FPGA-based GAT accelerator that achieves more efficient GAT inference. The proposed approach employed several optimizations to enhance GAT performance. First, this work optimized the GAT algorithm using split weights and softmax approximation to make it more hardware-friendly. Second, a load-balanced SPMM kernel was designed to fully leverage potential parallelism and improve data throughput. Lastly, data preprocessing was performed by pre-fetching the source node and its neighbor nodes, effectively addressing pipeline stall and complexly addressing issues arising from irregular memory access. SH-GAT was evaluated on the Xilinx FPGA Alveo U280 accelerator card with three popular datasets. Compared to existing CPU, GPU, and state-of-the-art (SOTA) FPGA-based accelerators, SH-GAT can achieve speedup by up to 3283$ \times $, 13$ \times $, and 2.3$ \times $.

| [1] | T. N. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks, preprint, arXiv: 1609.02907. |
| [2] | S. Abu-El-Haija, A. Kapoor, B. Perozzi, J. Lee, N-GCN: Multi-scale graph convolution for semi-supervised node classification, in Proceedings of The 35th Uncertainty in Artificial Intelligence Conference, 115 (2020), 841–851. Available from: https://proceedings.mlr.press/v115/abu-el-haija20a.html. |
| [3] | M. Zhang, Y. Chen, Link prediction based on graph neural networks, in Advances in Neural Information Processing Systems, 31 (2018), 5171–5181. Available from: https://proceedings.neurips.cc/paper_files/paper/2018/file/53f0d7c537d99b3824f0f99d62ea2428-Paper.pdf. |
| [4] | M. Zhang, Z. Cui, M. Neumann, Y. Chen, An end-to-end deep learning architecture for graph classification, in Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 32 (2018), 4438–4445. https://doi.org/10.1609/aaai.v32i1.11782 |
| [5] | P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Liò, Y. Bengio, Graph attention networks, preprint, arXiv: 1710.10903. |
| [6] | R. Chen, H. Zhang, Y. Li, R. Zhang, G. Li, J. Yu, et al., Edge FPGA-based onsite neural network training, in 2023 IEEE International Symposium on Circuits and Systems (ISCAS), (2023), 1–5. https://doi.org/10.1109/ISCAS46773.2023.10181582 |
| [7] | W. Yan, W. Tong, X. Zhi, S-GAT: Accelerating graph attention networks inference on FPGA platform with shift operation, in 2020 IEEE 26th International Conference on Parallel and Distributed Systems (ICPADS), (2020), 661–666. https://doi.org/10.1109/ICPADS51040.2020.00093 |
| [8] |
S. Huang, E. Tang, S. Li, H-GAT: A hardware-efficient accelerator for graph attention networks, J. Appl. Sci. Eng., 27 (2023), 2233–2240. http://dx.doi.org/10.6180/jase.202403_27(3).0010 doi: 10.6180/jase.202403_27(3).0010

|
| [9] |
T. Tian, L. Zhao, X. Wang, Q. Wu, W. Yuan, X. Jin, FP-GNN: Adaptive FPGA accelerator for graph neural networks, Future Gener. Comput. Syst., 136 (2022), 294–310. https://doi.org/10.1016/j.future.2022.06.010 doi: 10.1016/j.future.2022.06.010
|
| [10] |
Z. He, T. Tian, Q. Wu, X. Jin, FTW-GAT: An FPGA-based accelerator for graph attention networks with ternary weights, IEEE Trans. Circuits Syst. II Express Briefs, 70 (2023), 4211–4215. https://doi.org/10.1109/TCSII.2023.3280180 doi: 10.1109/TCSII.2023.3280180
|
| [11] | T. Geng, A. Li, R. Shi, C. Wu, T. Wang, Y. Li, et al., AWB-GCN: A graph convolutional network accelerator with runtime workload rebalancing, in 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), (2020), 922–936. https://doi.org/10.1109/MICRO50266.2020.00079 |
| [12] | B. Zhang, R. Kannan, V. Prasanna, BoostGCN: A framework for optimizing GCN inference on FPGA, in 2021 IEEE 29th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), (2021), 29–39. https://doi.org/10.1109/FCCM51124.2021.00012 |
| [13] | T. Geng, C. Wu, Y. Zhang, C. Tan, C. Xie, H. You, et al., I-GCN: A graph convolutional network accelerator with runtime locality enhancement through Islandization, in 54th Annual IEEE/ACM International Symposium on Microarchitecture, (2021), 1051–1063. https://doi.org/10.1145/3466752.3480113 |
| [14] | M. Yan, L. Deng, X. Hu, L. Liang, Y. Feng, X. Ye, et al., HyGCN: A GCN accelerator with hybrid architecture, in 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), (2020), 15–29. https://doi.org/10.1109/HPCA47549.2020.00012 |
| [15] | Y. Gao, L. Gong, C. Wang, T. Wang, X. Zhou, SDMA: An efficient and flexible sparse-dense matrix-multiplication architecture for GNNs, in 2022 32nd International Conference on Field-Programmable Logic and Applications (FPL), (2022), 307–312. https://doi.org/10.1109/FPL57034.2022.00054 |
| [16] | R. Chen, H. Zhang, Y. Ma, J. Chen, J. Yu, K. Wang, eSSpMV: An embedded-FPGA-based hardware accelerator for symmetric sparse matrix-vector multiplication, in 2023 IEEE International Symposium on Circuits and Systems (ISCAS), (2023), 1–5. https://doi.org/10.1109/ISCAS46773.2023.10181734 |
| [17] | Z. Xu, J. Yu, C. Yu, H. Shen, Y. Wang, H. Yang, CNN-based feature-point extraction for real-time visual SLAM on embedded FPGA, in 2020 IEEE 28th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), (2020), 33–37. https://doi.org/10.1109/FCCM48280.2020.00014 |
Figures(7) / Tables(4)
Renping Wang, Shun Li, Enhao Tang, Sen Lan, Yajing Liu, Jing Yang, Shizhen Huang, Hailong Hu. SH-GAT: Software-hardware co-design for accelerating graph attention networks on FPGA[J]. Electronic Research Archive, 2024, 32(4): 2310-2322. doi: 10.3934/era.2024105







 DownLoad:
DownLoad: