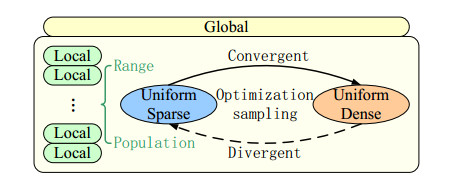
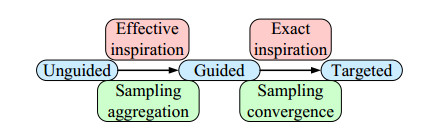
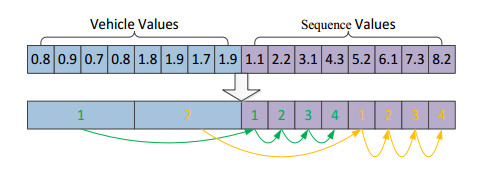
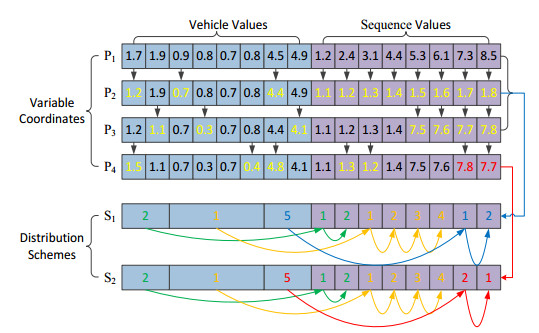
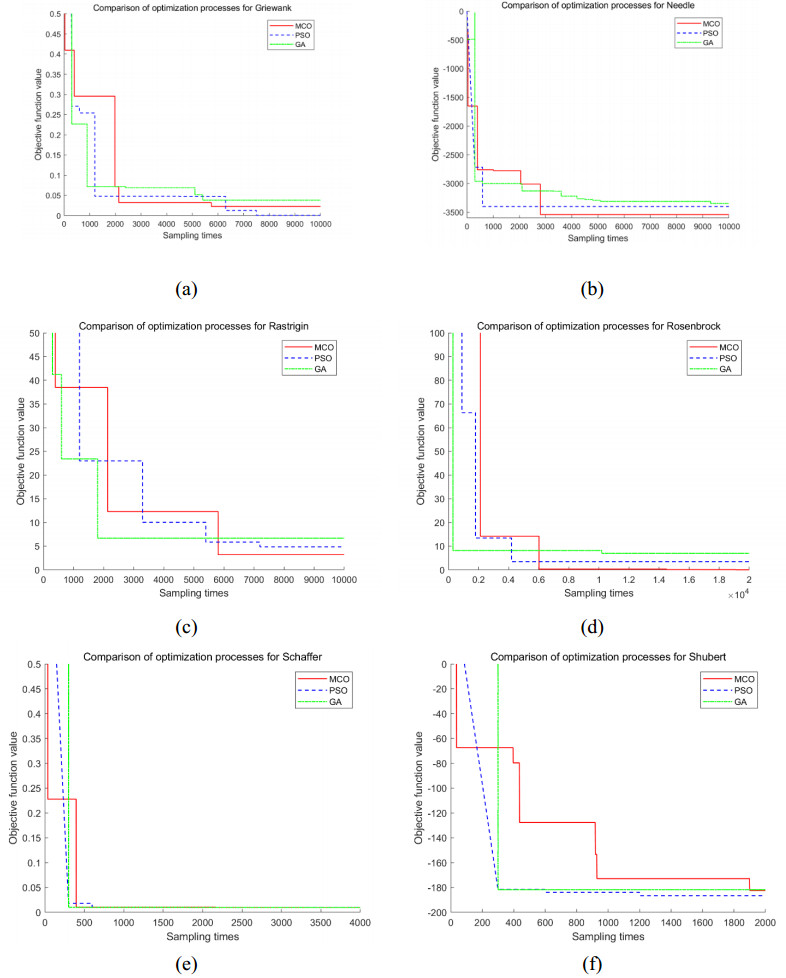
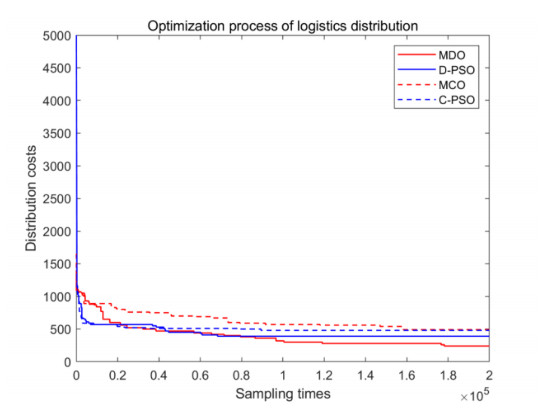
This study was purposed to design a multimodal continuous optimization algorithm based on a scheme agent to address the multidimensional complexity of optimization. An evolutionary sampling method of subarea exploration and multiple exploitations was developed by employing the scheme with variable population size so as to obtain higher optimization speed and accuracy. Second, the distribution plan was quantified into high-dimensional variable parameters based on the characteristics of logistics distribution optimization problems, and a high-dimensional discrete optimization model was constructed. Then, we identified and addressed the prominent issues and malignant virtual changes in the application of continuous algorithms to discrete problems. We have introduced a reasonable mutation mechanism during the optimization sampling process to mitigate this issue. Continuous real coordinate points were transformed across the neighborhood to standard discrete integer coordinate points by normalizing and logicizing the optimization sampling coordinates; also, the discretization of the continuous algorithm was realized. This approach could effectively prevent the algorithm from searching for targets in continuous optimization space, thereby fully reducing the complexity of the objective function distribution after conversion. The experiments showed that the transformed multimodal discrete optimization algorithm effectively addressed the optimization design problem of logistics distribution.
Citation: Weishang Gao, Qin Gao, Lijie Sun, Yue Chen. Design of a novel multimodal optimization algorithm and its application in logistics optimization[J]. Electronic Research Archive, 2024, 32(3): 1946-1972. doi: 10.3934/era.2024089
This study was purposed to design a multimodal continuous optimization algorithm based on a scheme agent to address the multidimensional complexity of optimization. An evolutionary sampling method of subarea exploration and multiple exploitations was developed by employing the scheme with variable population size so as to obtain higher optimization speed and accuracy. Second, the distribution plan was quantified into high-dimensional variable parameters based on the characteristics of logistics distribution optimization problems, and a high-dimensional discrete optimization model was constructed. Then, we identified and addressed the prominent issues and malignant virtual changes in the application of continuous algorithms to discrete problems. We have introduced a reasonable mutation mechanism during the optimization sampling process to mitigate this issue. Continuous real coordinate points were transformed across the neighborhood to standard discrete integer coordinate points by normalizing and logicizing the optimization sampling coordinates; also, the discretization of the continuous algorithm was realized. This approach could effectively prevent the algorithm from searching for targets in continuous optimization space, thereby fully reducing the complexity of the objective function distribution after conversion. The experiments showed that the transformed multimodal discrete optimization algorithm effectively addressed the optimization design problem of logistics distribution.

| [1] |
X. Zhu, N. Liu, Y. Shi, Artificial intelligence technology in modern logistics system, Int. J. Technol. Policy Manage., 22 (2022), 66–81. https://doi.org/10.1504/IJTPM.2022.122537 doi: 10.1504/IJTPM.2022.122537

|
| [2] | F. Qiu, Focus on the thinking of logistics operations developing to the digital and intelligent supply chain, Hoisting Conveying Mach., (2021), 22–23. |
| [3] |
W. Qin, X. Qi, Evaluation of green logistics efficiency in northwest China, Sustainability, 14 (2022), 6848–6848. https://doi.org/10.3390/su14116848 doi: 10.3390/su14116848
|
| [4] |
Z. Yang, Research on the construction of paper industry information logistics system under the background of green and recyclable, Paper Sci. Technol., 40 (2021), 77–79. https://doi.org/10.19696/j.issn1671-4571.2021.4.016 doi: 10.19696/j.issn1671-4571.2021.4.016
|
| [5] |
S. Zhao, Q. Zhang, Z. Peng, X. Lu, Personalized manufacturing service composition recommendation: combining combinatorial optimization and collaborative filtering, J. Comb. Optim., 40 (2020), 733–756. https://doi.org/10.1007/s10878-020-00613-0 doi: 10.1007/s10878-020-00613-0
|
| [6] |
H. Zhang, H. Wang, Y. Wang, D. Hong, Uncertainty modeling and optimization method for overall design of flight vehicle, J. Astronaut., 44 (2023), 486–495. https://doi.org/10.3873/j.issn.1000-1328.2023.04.003 doi: 10.3873/j.issn.1000-1328.2023.04.003
|
| [7] |
Y. Zhang, L. Liu, T. Wang, J. Guo, Y. Han, Error analysis and optimization algorithm of focal shift on mode decomposition for few-mode fiber beam, Optoelectron. Lett., 17 (2021), 418–421. https://doi.org/10.1007/s11801-021-0147-x doi: 10.1007/s11801-021-0147-x
|
| [8] |
Y. Hua, Y. Liu, W. Pan, X. Diao, H. Zhu, Multi-objective optimization design of bearingless permanent magnet synchronous motor using improved particle swarm optimization algorithm, Chin. Soc. Elec. Eng., 43 (2023), 4443–4451. https://doi.org/10.13334/j.0258-8013.pcsee.220039 doi: 10.13334/j.0258-8013.pcsee.220039
|
| [9] |
D. Wang, S. Chen, Spatial difference and distribution dynamic evolution of high-quality development of logistics industry in China, Stat. Decis., 38 (2022), 57–62. https://doi.org/10.13546/j.cnki.tjyjc.2022.09.011 doi: 10.13546/j.cnki.tjyjc.2022.09.011
|
| [10] |
J. Wang, K. Zhou, Analysis of the relationship between the distribution of city size and the allocation efficiency of logistics industry, J. Commer. Econ., 22 (2023), 92–96. https://doi.org/10.3969/j.issn.1002-5863.2023.22.021 doi: 10.3969/j.issn.1002-5863.2023.22.021
|
| [11] |
K. Shang, X. Wei, The effect of integration development of logistics industry and information industry on its energy intensity, J. Henan Univ., 63 (2023), 19–23,152. https://doi.org/10.15991/j.cnki.411028.2023.03.021 doi: 10.15991/j.cnki.411028.2023.03.021
|
| [12] |
C. Zhang, J. Liu, Multi-box container loading problem based on hybrid genetic algorithm, J. Beijing Univ. Aeronaut. Astronaut., 48 (2022), 747–755. https://doi.org/10.13700/j.bh.1001-5965.2020.0665 doi: 10.13700/j.bh.1001-5965.2020.0665
|
| [13] |
G. Zhao, Z. Qin, J. Li, Optimization algorithm and implementation of dispatched vehicles between several flights in condition of flights delay, J. Chongqing Jiaotong Univ., 39 (2020), 5–9, 17. https://doi.org/10.3969/j.issn.1674-0696.2020.10.02 doi: 10.3969/j.issn.1674-0696.2020.10.02
|
| [14] |
Y. Liu, H. Chen, Distribution path planning and charging strategy for pure electric vehicles with load constraint, J. Comput. Appl., 40 (2020), 2831–2837. https://doi.org/10.11772/j.issn.1001-9081.2020020157 doi: 10.11772/j.issn.1001-9081.2020020157
|
| [15] |
H. Lu, K. Zhao, Optimization of the multi-containers loading problems based on complex constraints, J. Wuhan Univ. Technol. (Transp. Sci. Eng.), 40 (2016), 1058–1062. https://doi.org/10.3963/j.issn.2095-3844.2016.06.023 doi: 10.3963/j.issn.2095-3844.2016.06.023
|
| [16] |
N. Wu, H. Dai, J. Li, Q. Jiang, Multi-objective optimization of cold chain logistics distribution path considering time tolerance, J. Transp. Syst. Eng. Inf. Technol., 23 (2023), 275–284. https://doi.org/10.16097/j.cnki.1009-6744.2023.02.029 doi: 10.16097/j.cnki.1009-6744.2023.02.029
|
| [17] | H. Lu, Y. Wang, Research on preventive maintenance strategy of port machinery equipment considering reliability and economy, Modern Manuf. Eng., (2022), 116–122,115. https://doi.org/10.16731/j.cnki.1671-3133.2022.08.018 |
| [18] |
M. Zhang, Y. An, N. Pan, Y. Sun, J. Bao, H. Gao, et al., Heterogeneous vehicle scheduling oriented to urban city supermarket logistics distribution, J. Kunming Univ. Sci. Technol., 47 (2022), 154–162. https://doi.org/10.16112/j.cnki.53-1223/n.2022.06.482 doi: 10.16112/j.cnki.53-1223/n.2022.06.482
|
| [19] |
J. Li, Study on the development path of green logistics from the perspective of supply chain, Logist. Sci.-Tech., 46 (2023), 133–135,139. https://doi.org/10.13714/j.cnki.1002-3100.2023.14.036 doi: 10.13714/j.cnki.1002-3100.2023.14.036
|
| [20] |
Y. Wang, Y. Wei, Q. Jiang, M. Xu, Study on the optimization method of three-dimensional loading logistics distribution with time windows, Oper. Res. Manage. Sci., 31 (2022), 111–119. https://doi.org/10.12005/orms.2022.0395 doi: 10.12005/orms.2022.0395
|
| [21] | J. Huang, Research on cross-border e-commerce logistics distribution optimization based on multi-objective optimization and chicken flock algorithm, Econ. Res. Guide, (2021), 34–37. https://doi.org/10.3969/j.issn.1673-291X.2021.03.012 |
| [22] |
C. Wu, J. Yang, Vehicle routing problem of logistics distribution based on improved particle swarm optimization algorithm, Comput. Eng. Appl., 51 (2015), 259–262. https://doi.org/10.3778/j.issn.1002-8331.1409-0200 doi: 10.3778/j.issn.1002-8331.1409-0200
|
| [23] |
J. Lu, Scheduling distribution vehicles in internet of things based on perturbation contraction particle swarm optimization, J. Highway Transp. Res. Dev., 37 (2020), 111–117. https://doi.org/10.3969/j.issn.1002-0268.2020.04.015 doi: 10.3969/j.issn.1002-0268.2020.04.015
|
| [24] |
W. Fei, C. Liu, S. Hu, Research on swarm intelligence optimization algorithm, J. China Univ. Posts Telecommun., 27 (2020), 1–20. https://doi.org/10.19682/j.cnki.1005-8885.2020.0012 doi: 10.19682/j.cnki.1005-8885.2020.0012
|
| [25] |
Z. Wang, Y. Deng, Optimizing financial engineering time indicator using bionics computation algorithm and neural network deep learning, Comput. Econ., 59 (2022), 1755–1772. https://doi.org/10.1007/s10614-022-10253-7 doi: 10.1007/s10614-022-10253-7
|
| [26] |
P. Trojovsky, M. Dehghani, A new optimization algorithm based on mimicking the voting process for leader selection, PeerJ Comput. Sci., 8 (2022), 1–40. https://doi.org/10.7717/peerj-cs.976 doi: 10.7717/peerj-cs.976
|
| [27] | S. Bhatti, V. Tayal, P. Gulia, Swarm intelligence, Int. J. Innovative Res. Technol., 1 (2015), 210–214. |
| [28] |
R. Qi, Z. Wang, S. Li, A parallel genetic algorithm based on spark for pairwise test suite generation, J. Comput. Sci. Technol., 31 (2016), 417–427. https://doi.org/10.1007/s11390-016-1635-5 doi: 10.1007/s11390-016-1635-5
|
| [29] |
W. Zhou, S. Li, G. Ma, X. Chang, X. Ma, C. Zhang, Parameters inversion of high central core rockfill dams based on a novel genetic algorithm, Sci. China Technol. Sci., 59 (2016), 783–794. https://doi.org/10.1007/s11431-016-6017-2 doi: 10.1007/s11431-016-6017-2
|
| [30] |
Ankita, S. K. Sahana, Ba-PSO: A Balanced PSO to solve multi-objective grid scheduling problem, Appl. Intell., 52 (2022), 4015–4027. https://doi.org/10.1007/s10489-021-02625-7 doi: 10.1007/s10489-021-02625-7
|
| [31] |
P. Kumari, S. K. Sahana, PSO-DQ: An improved routing protocol based on PSO using dynamic queue mechanism for MANETs, J. Inf. Sci. Eng., 38 (2022), 41–56. https://doi.org/10.6688/JISE.202201_38(1).0003 doi: 10.6688/JISE.202201_38(1).0003
|
| [32] |
Y. Xiang, X. Yang, H. Huang, J. Wang, Balancing constraints and objectives by considering problem types in constrained multiobjective optimization, IEEE Trans. Cybern., 53 (2023), 88–101. https://doi.org/10.1109/TCYB.2021.3089633 doi: 10.1109/TCYB.2021.3089633
|
| [33] |
Y. Sui, Z. Li, H. Li, G. Chen, Continuous solution method for 0-1 programming based on the sinusoidal smooth polish function, Oper. Res. Trans., 21 (2017), 35–44. https://doi.org/10.15960/j.cnki.issn.1007-6093.2017.03.004 doi: 10.15960/j.cnki.issn.1007-6093.2017.03.004
|


Figures(16) / Tables(6)
Weishang Gao, Qin Gao, Lijie Sun, Yue Chen. Design of a novel multimodal optimization algorithm and its application in logistics optimization[J]. Electronic Research Archive, 2024, 32(3): 1946-1972. doi: 10.3934/era.2024089







 DownLoad:
DownLoad: