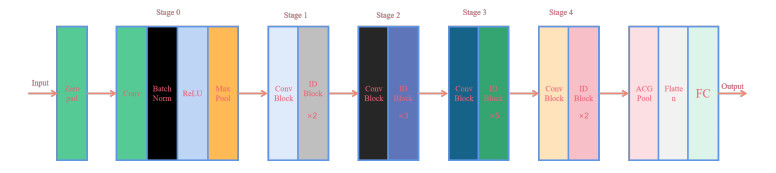
The emergence of COVID-19 has broken the silence of humanity and people are gradually becoming concerned about pneumonia-related diseases; thus, improving the recognition rate of pneumonia-related diseases is an important task. Neural networks have a remarkable effectiveness in medical diagnoses, though the internal parameters need to be set in accordance to different data sets; therefore, an important challenge is how to further improve the efficiency of neural network models. In this paper, we proposed a learning exponential distribution optimizer based on chaotic evolution, and we optimized Resnet50 for COVID classification, in which the model is abbreviated as IEDO-net. The algorithm introduces a criterion for judging the distance of the signal-to-noise ratio, a chaotic evolution mechanism is designed according to this criterion to effectively improve the search efficiency of the algorithm, and a rotating flight mechanism is introduced to improve the search capability of the algorithm. In the computed tomography (CT) image data of COVID-19, the accuracy, sensitivity, specificity, precision, and F1 score of the optimized Resnet50 were 94.42%, 93.40%, 94.92%, 94.29% and 93.84%, respectively. The proposed network model is compared with other algorithms and models, and ablation experiments and convergence and statistical analyses are performed. The results show that the diagnostic performance of IEDO-net is competitive, which validates the feasibility and effectiveness of the proposed network.
Citation: Chengtian Ouyang, Huichuang Wu, Jiaying Shen, Yangyang Zheng, Rui Li, Yilin Yao, Lin Zhang. IEDO-net: Optimized Resnet50 for the classification of COVID-19[J]. Electronic Research Archive, 2023, 31(12): 7578-7601. doi: 10.3934/era.2023383
The emergence of COVID-19 has broken the silence of humanity and people are gradually becoming concerned about pneumonia-related diseases; thus, improving the recognition rate of pneumonia-related diseases is an important task. Neural networks have a remarkable effectiveness in medical diagnoses, though the internal parameters need to be set in accordance to different data sets; therefore, an important challenge is how to further improve the efficiency of neural network models. In this paper, we proposed a learning exponential distribution optimizer based on chaotic evolution, and we optimized Resnet50 for COVID classification, in which the model is abbreviated as IEDO-net. The algorithm introduces a criterion for judging the distance of the signal-to-noise ratio, a chaotic evolution mechanism is designed according to this criterion to effectively improve the search efficiency of the algorithm, and a rotating flight mechanism is introduced to improve the search capability of the algorithm. In the computed tomography (CT) image data of COVID-19, the accuracy, sensitivity, specificity, precision, and F1 score of the optimized Resnet50 were 94.42%, 93.40%, 94.92%, 94.29% and 93.84%, respectively. The proposed network model is compared with other algorithms and models, and ablation experiments and convergence and statistical analyses are performed. The results show that the diagnostic performance of IEDO-net is competitive, which validates the feasibility and effectiveness of the proposed network.

| [1] |
Q. Yuan, K. Chen, Y. Yu, N. Q. K. Le, M. C. H. Chua, Prediction of anticancer peptides based on an ensemble model of deep learning and machine learning using ordinal positional encoding, Briefings Bioinf., 24 (2023), bbac630. https://doi.org/10.1093/bib/bbac630 doi: 10.1093/bib/bbac630

|
| [2] |
N. Q. K. Le, Potential of deep representative learning features to interpret the sequence information in proteomics, Proteomics, 22 (2022), 2100232. https://doi.org/10.1002/pmic.202100232 doi: 10.1002/pmic.202100232
|
| [3] |
P. Aggarwal, N. K. Mishra, B. Fatimah, P. Singh, A. Gupta, S. D. Joshi, COVID-19 image classification using deep learning: Advances, challenges and opportunities, Comput. Biol. Med., 144 (2022), 105350. https://doi.org/10.1016/j.compbiomed.2022.105350 doi: 10.1016/j.compbiomed.2022.105350
|
| [4] |
O. S. Albahri, A. A. Zaidan, A. S. Albahri, B. B. Zaidan, K. H. Abdulkareem, Z. T. Al-qaysi, et al., Systematic review of artificial intelligence techniques in the detection and classification of COVID-19 medical images in terms of evaluation and benchmarking: Taxonomy analysis, challenges, future solutions and methodological aspects, J. Infect. Public Health, 13 (2020), 1381–1396. https://doi.org/10.1016/j.jiph.2020.06.028 doi: 10.1016/j.jiph.2020.06.028
|
| [5] |
T. W. Cenggoro, B. Pardamean, A systematic literature review of machine learning application in COVID-19 medical image classification, Procedia Comput. Sci., 216 (2023), 749–756. https://doi.org/10.1016/j.procs.2022.12.192 doi: 10.1016/j.procs.2022.12.192
|
| [6] |
Y. Hu, K. Liu, K. Ho, D. Riviello, J. Brown, A. R. Chang, et al., A simpler machine learning model for acute kidney injury risk stratification in hospitalized patients, J. Clin. Med., 11 (2022), 5688. https://doi.org/10.3390/jcm11195688 doi: 10.3390/jcm11195688
|
| [7] |
E. Hussain, M. Hasan, M. A. Rahman, I. Lee, T. Tamanna, M. Z. Parvez, CoroDet: A deep learning based classification for COVID-19 detection using chest X-ray images, Chaos, Solitons Fractals, 142 (2021), 110495. https://doi.org/10.1016/j.chaos.2020.110495 doi: 10.1016/j.chaos.2020.110495
|
| [8] |
M. A. Ozdemir, G. D. Ozdemir, O. Guren, Classification of COVID-19 electrocardiograms by using hexaxial feature mapping and deep learning, BMC Med. Inf. Decis. Making, 21 (2021), 170. https://doi.org/10.1186/s12911-021-01521-x doi: 10.1186/s12911-021-01521-x
|
| [9] |
A. M. Ismael, A. Şengür, Deep learning approaches for COVID-19 detection based on chest X-ray images, Expert Syst. Appl., 164 (2021), 114054. https://doi.org/10.1016/j.eswa.2020.114054 doi: 10.1016/j.eswa.2020.114054
|
| [10] |
K. Kc, Z. Yin, M. Wu, Z. Wu, Evaluation of deep learning-based approaches for COVID-19 classification based on chest X-ray images, Signal, Image Video Process., 15 (2021), 959–966. https://doi.org/10.1007/s11760-020-01820-2 doi: 10.1007/s11760-020-01820-2
|
| [11] |
G. Muhammad, M. S. Hossain, COVID-19 and non-COVID-19 classification using multi-layers fusion from lung ultrasound images, Inf. Fusion, 72 (2021), 80–88. https://doi.org/10.1016/j.inffus.2021.02.013 doi: 10.1016/j.inffus.2021.02.013
|
| [12] |
X. Wang, X. Deng, Q. Fu, Q. Zhou, J. Feng, H. Ma, et al., A weakly-supervised framework for COVID-19 classification and lesion localization from chest CT, IEEE Trans. Med. Imaging, 39 (2020), 2615–2625. https://doi.org/10.1109/TMI.2020.2995965 doi: 10.1109/TMI.2020.2995965
|
| [13] |
M. Riaz, M. Bashir, I. Younas, Metaheuristics based COVID-19 detection using medical images: A review, Comput. Biol. Med., 2022 (2022), 105344. https://doi.org/10.1016/j.compbiomed.2022.105344 doi: 10.1016/j.compbiomed.2022.105344
|
| [14] |
D. Zhu, S. Wang, C. Zhou, S. Yan, J. Xue, Human memory optimization algorithm: A memory-inspired optimizer for global optimization problems, Expert Syst. Appl., 237 (2024), 121597. https://doi.org/10.1016/j.eswa.2023.121597 doi: 10.1016/j.eswa.2023.121597
|
| [15] |
D. Zhu, S. Wang, J. Shen, C. Zhou, T. Li, S. Yan, A multi-strategy particle swarm algorithm with exponential noise and fitness-distance balance method for low-altitude penetration in secure space, J. Comput. Sci., 74 (2023), 102149. https://doi.org/10.1016/j.jocs.2023.102149 doi: 10.1016/j.jocs.2023.102149
|
| [16] | J. Kennedy, R. Eberhart, Particle swarm optimization, in Proceedings of ICNN'95-International Conference on Neural Networks, IEEE, (1995), 1942–1948. https://doi.org/10.1109/ICNN.1995.488968 |
| [17] | K. V. Price, Differential evolution, in Handbook of Optimization: From Classical to Modern Approach, Springer, (2013), 187–214. https://doi.org/10.1007/978-3-642-30504-7_8 |
| [18] | M. Dorigo, M. Birattari, T. Stutzle, Ant colony optimization, IEEE Comput. Intell. Mag., 1 (2006), 28–39. https://doi.org/10.1109/MCI.2006.329691 |
| [19] | S. Mirjalili, S. M. Mirjalili, A. Lewis, Grey wolf optimizer, Adv. Eng. Software, 69 (2014), 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 |
| [20] |
S. Mirjalili, A. Lewis, The whale optimization algorithm, Adv. Eng. Software, 95 (2016), 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008 doi: 10.1016/j.advengsoft.2016.01.008
|
| [21] |
J. Xue, B. Shen, A novel swarm intelligence optimization approach: Sparrow search algorithm, Syst. Sci. Control Eng., 8 (2020), 22–34. https://doi.org/10.1080/21642583.2019.1708830 doi: 10.1080/21642583.2019.1708830
|
| [22] |
A. A. Heidari, S. Mirjalili, H. Faris, I. Aljarah, M. Mafarja, H. Chen, Harris hawks optimization: Algorithm and applications, Future Gener. Comput. Syst., 97 (2019), 849–872. https://doi.org/10.1016/j.future.2019.02.028 doi: 10.1016/j.future.2019.02.028
|
| [23] |
W. Zhao, Z. Zhang, L. Wang, Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications, Eng. Appl. Artif. Intell., 87 (2020), 103300. https://doi.org/10.1016/j.engappai.2019.103300 doi: 10.1016/j.engappai.2019.103300
|
| [24] |
M. Abdel-Basset, D. El-Shahat, M. Jameel, M. Abouhawwash, Exponential distribution optimizer (EDO): A novel math-inspired algorithm for global optimization and engineering problems, Artif. Intell. Rev., 56 (2023), 9329–9400. https://doi.org/10.1007/s10462-023-10403-9 doi: 10.1007/s10462-023-10403-9
|
| [25] |
A. Dixit, A. Mani, R. Bansal, CoV2-Detect-Net: Design of COVID-19 prediction model based on hybrid DE-PSO with SVM using chest X-ray images, Inf. Sci., 571 (2021), 676–692. https://doi.org/10.1016/j.ins.2021.03.062 doi: 10.1016/j.ins.2021.03.062
|
| [26] |
D. A. D. Júnior, L. B. da Cruz, J. O. B. Diniz, G. L. F. da Silva, G. B. Junior, A. C. Silva, et al., Automatic method for classifying COVID-19 patients based on chest X-ray images, using deep features and PSO-optimized XGBoost, Expert Syst. Appl., 183 (2021), 115452. https://doi.org/10.1016/j.eswa.2021.115452 doi: 10.1016/j.eswa.2021.115452
|
| [27] |
M. A. A. Albadr, S. Tiun, M. Ayob, F. T. AL-Dhief, Particle swarm optimization-based extreme learning machine for COVID-19 detection, Cognit. Comput., 2022 (2022), 1–16. https://doi.org/10.1007/s12559-022-10063-x doi: 10.1007/s12559-022-10063-x
|
| [28] |
M. A. Elaziz, K. M. Hosny, A. Salah, M. M. Darwish, S. Lu, A. T. Sahlol, New machine learning method for image-based diagnosis of COVID-19, PLoS One, 15 (2020), e0235187. https://doi.org/10.1371/journal.pone.0235187 \newpage doi: 10.1371/journal.pone.0235187
|
| [29] |
E. S. M. El-Kenawy, S. Mirjalili, A. Ibrahim, M. Alrahmawy, M. El-Said, R. M. Zaki, et al., Advanced meta-heuristics, convolutional neural networks, and feature selectors for efficient COVID-19 X-ray chest image classification, IEEE Access, 9 (2021), 36019–36037. https://doi.org/10.1109/ACCESS.2021.3061058 doi: 10.1109/ACCESS.2021.3061058
|
| [30] |
S. Pathan, P. C. Siddalingaswamy, P. Kumar, M. M. M. Pai, T. Ali, U. R. Acharya, Novel ensemble of optimized CNN and dynamic selection techniques for accurate COVID-19 screening using chest CT images, Comput. Biol. Med., 137 (2021), 104835. https://doi.org/10.1016/j.compbiomed.2021.104835 doi: 10.1016/j.compbiomed.2021.104835
|
| [31] |
A. Basu, K. H. Sheikh, E. Cuevas, R. Sarkar, COVID-19 detection from CT scans using a two-stage framework, Expert Syst. Appl., 193 (2022), 116377. https://doi.org/10.1016/j.eswa.2021.116377 doi: 10.1016/j.eswa.2021.116377
|
| [32] |
M. H. Nadimi-Shahraki, H. Zamani, S. Mirjalili, Enhanced whale optimization algorithm for medical feature selection: A COVID-19 case study, Comput. Biol. Med., 148 (2022), 105858. https://doi.org/10.1016/j.compbiomed.2022.105858 doi: 10.1016/j.compbiomed.2022.105858
|
| [33] | S. Elghamrawy, A. E. Hassanien, Diagnosis and prediction model for COVID-19 patient's response to treatment based on convolutional neural networks and whale optimization algorithm using CT images, preprint, MedRxiv, 2020. https://doi.org/10.1101/2020.04.16.20063990 |
| [34] |
T. Goel, R. Murugan, S. Mirjalili, D. K. Chakrabartty, OptCoNet: An optimized convolutional neural network for an automatic diagnosis of COVID-19, Appl. Intell., 51 (2021), 1351–1366. https://doi.org/10.1007/s10489-020-01904-z doi: 10.1007/s10489-020-01904-z
|
| [35] |
T. Hu, M. Khishe, M. Mohammadi, G. Parvizi, S. H. T. Karim, T. A. Rashid, Real-time COVID-19 diagnosis from X-Ray images using deep CNN and extreme learning machines stabilized by chimp optimization algorithm, Biomed. Signal Process. Control, 68 (2021), 102764. https://doi.org/10.1016/j.bspc.2021.102764 doi: 10.1016/j.bspc.2021.102764
|
| [36] |
D. Singh, V. Kumar, M. Kaur, Classification of COVID-19 patients from chest CT images using multi-objective differential evolution–based convolutional neural networks, Eur. J. Clin. Microbiol. Infect. Dis., 39 (2020), 1379–1389. https://doi.org/10.1007/s10096-020-03901-z doi: 10.1007/s10096-020-03901-z
|
| [37] | M. S. Iraji, M. Feizi-Derakhshi, J. Tanha, Deep learning for COVID-19 diagnosis based feature selection using binary differential evolution algorithm, preprint, 2021, arXiv: PPR343118. |
| [38] |
A. M. Sahan, A. S. Al-Itbi, J. S. Hameed, COVID-19 detection based on deep learning and artificial bee colony, Periodicals Eng. Nat. Sci., 9 (2021), 29–36. http://doi.org/10.21533/pen.v9i1.1774 doi: 10.21533/pen.v9i1.1774
|
| [39] | F. Sadeghi, O. Rostami, M. K. Yi, A deep learning approach for detecting COVID-19 using the chest X-ray images, CMC-Comput. Mater. Continua, 75 (2023), 751–768. |
| [40] |
H. M. Balaha, E. M. El-Gendy, M. M. Saafan, CovH2SD: A COVID-19 detection approach based on Harris Hawks Optimization and stacked deep learning, Expert Syst. Appl., 186 (2021), 115805. https://doi.org/10.1016/j.eswa.2021.115805 doi: 10.1016/j.eswa.2021.115805
|
| [41] |
W. M. Bahgat, H. M. Balaha, Y. AbdulAzeem, M. M. Badawy, An optimized transfer learning-based approach for automatic diagnosis of COVID-19 from chest x-ray images, PeerJ Comput. Sci., 7 (2021), e555. https://doi.org/10.7717/peerj-cs.555 doi: 10.7717/peerj-cs.555
|
| [42] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, (2016), 770–778. |
| [43] |
L. Wen, X. Li, L. Gao, A transfer convolutional neural network for fault diagnosis based on ResNet-50, Neural Comput. Appl., 32 (2020), 6111–6124. https://doi.org/10.1007/s00521-019-04097-w doi: 10.1007/s00521-019-04097-w
|
| [44] |
J. Yang, J. Yu, C. Huang, Adaptive multistrategy ensemble particle swarm optimization with Signal-to-Noise ratio distance metric, Inf. Sci., 612 (2022), 1066–1094. https://doi.org/10.1016/j.ins.2022.07.165 doi: 10.1016/j.ins.2022.07.165
|
| [45] |
D. Zhu, Z. Huang, S. Liao, C. Zhou, S. Yan, G. Chen, Improved bare bones particle swarm optimization for DNA sequence design, IEEE Trans. Nanobiosci., 22 (2022), 603–613. https://doi.org/10.1109/TNB.2022.3220795 doi: 10.1109/TNB.2022.3220795
|
| [46] |
H. T. Kahraman, S. Aras, E. Gedikli, Fitness-distance balance (FDB): A new selection method for meta-heuristic search algorithms, Knowledge-Based Syst., 190 (2020), 105169. https://doi.org/10.1016/j.knosys.2019.105169 doi: 10.1016/j.knosys.2019.105169
|
| [47] |
R. Zheng, A. G. Hussien, R. Qaddoura, H. Jia, L. Abualigah, S. Wang, A multi-strategy enhanced African vultures optimization algorithm for global optimization problems, J. Comput. Des. Eng., 10 (2023), 329–356. https://doi.org/10.1093/jcde/qwac135 doi: 10.1093/jcde/qwac135
|
| [48] |
D. Zhu, S. Wang, C. Zhou, S. Yan, Manta ray foraging optimization based on mechanics game and progressive learning for multiple optimization problems, Appl. Soft Comput., 145 (2023), 110561. https://doi.org/10.1016/j.asoc.2023.110561 doi: 10.1016/j.asoc.2023.110561
|
| [49] |
R. Murugan, T. Goel, S. Mirjalili, D. K. Chakrabartty, WOANet: Whale optimized deep neural network for the classification of COVID-19 from radiography images, Biocybern. Biomed. Eng., 41 (2021), 1702–1718. https://doi.org/10.1016/j.bbe.2021.10.004 doi: 10.1016/j.bbe.2021.10.004
|
| [50] | C. Szegedy, W. Liu, Y. Jia, Going deeper with convolutions, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, (2015), 1–9. |
| [51] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [52] |
L. Kong, J. Cheng, Classification and detection of COVID-19 X-Ray images based on DenseNet and VGG16 feature fusion, Biomed. Signal Process. Control, 77 (2022), 103772. https://doi.org/10.1016/j.bspc.2022.103772 doi: 10.1016/j.bspc.2022.103772
|
| [53] |
A. Karacı, VGGCOV19-NET: Automatic detection of COVID-19 cases from X-ray images using modified VGG19 CNN architecture and YOLO algorithm, Neural Comput. Appl., 34 (2022), 8253–8274. https://doi.org/10.1007/s00521-022-06918-x doi: 10.1007/s00521-022-06918-x
|
| [54] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84–90. https://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [55] |
G. Muhammad, M. S. Hossain, COVID-19 and non-COVID-19 classification using multi-layers fusion from lung ultrasound images, Inf. Fusion, 72 (2021), 80–88. https://doi.org/10.1016/j.inffus.2021.02.013 doi: 10.1016/j.inffus.2021.02.013
|
| [56] | I. Bankman, Handbook of Medical Image Processing and Analysis, Elsevier, 2008. |
| [57] |
Y. Song, S. Zheng, L. Li, X. Zhang, X. Zhang, Z. Huang, et al., Deep learning enables accurate diagnosis of novel coronavirus (COVID-19) with CT images, IEEE/ACM Trans. Comput. Biol. Bioinf., 18 (2021), 2775–2780. https://doi.org/10.1109/TCBB.2021.3065361 doi: 10.1109/TCBB.2021.3065361
|
| [58] |
Y. Pathak, P. K. Shukla, K. V. Arya, Deep bidirectional classification model for COVID-19 disease infected patients, IEEE/ACM Trans. Comput. Biol. Bioinf., 18 (2020), 1234–1241. https://doi.org/10.1109/TCBB.2020.3009859 doi: 10.1109/TCBB.2020.3009859
|
| [59] |
Y. Pathak, P. K. Shukla, A. Tiwari, S. Stalin, S. Singh, P. K. Shukla, Deep transfer learning based classification model for COVID-19 disease, IRBM, 43 (2022), 87–92. https://doi.org/10.1016/j.irbm.2020.05.003 doi: 10.1016/j.irbm.2020.05.003
|
| [60] |
X. Fan, X. Feng, Y. Dong, H. Hou, COVID-19 CT image recognition algorithm based on transformer and CNN, Displays, 72 (2022), 102150. https://doi.org/10.1016/j.displa.2022.102150 doi: 10.1016/j.displa.2022.102150
|
| [61] |
A. S. Ebenezer, S. D. Kanmani, M. Sivakumar, S. J. Priya, Effect of image transformation on EfficientNet model for COVID-19 CT image classification, Mater. Today Proc., 51 (2022), 2512–2519. https://doi.org/10.1016/j.matpr.2021.12.121 doi: 10.1016/j.matpr.2021.12.121
|
| [62] |
N. S. Shaik, T. K. Cherukuri, Transfer learning based novel ensemble classifier for COVID-19 detection from chest CT-scans, Comput. Biol. Med., 141 (2022), 105127. https://doi.org/10.1016/j.compbiomed.2021.105127 doi: 10.1016/j.compbiomed.2021.105127
|








Figures(9) / Tables(5)
Chengtian Ouyang, Huichuang Wu, Jiaying Shen, Yangyang Zheng, Rui Li, Yilin Yao, Lin Zhang. IEDO-net: Optimized Resnet50 for the classification of COVID-19[J]. Electronic Research Archive, 2023, 31(12): 7578-7601. doi: 10.3934/era.2023383







 DownLoad:
DownLoad: