Citation: Bedassa D. Kitessa, Semu M. Ayalew, Geremew S. Gebrie, Solomon T. Teferi. Quantifying water-energy nexus for urban water systems: A case study of Addis Ababa city[J]. AIMS Environmental Science, 2020, 7(6): 486-504. doi: 10.3934/environsci.2020031

| [1] | Zakkour PD, Gaterell MR, Griffin P, et al. (2002) Developing a Sustainable Energy Strategy for a Water Utility. Part I: A Review of the UK Legislative Framework. J Environ Manage 66: 105-114. |
| [2] | UNICEF, Annual Report. 2013. |
| [3] | IEA, Emissions from fuel combustion. International Energy Agency. 2012. |
| [4] | Cohen R, Nelson B, Wolff G (2004) Energy Down the Drain: The Hidden Costs of California's Water Supply. Natural Resources Defence Council and Pacific Institute. USA. |
| [5] | Healy RW, Alley WM, Engle MA, et al. (2015) The water-energy nexus: an earth science perspective. US Geological Survey. |
| [6] | Voinov A, Cardwell H (2009) The Energy-Water Nexus: Why Should We Care? J Contemp Water Res Educ 143: 17-29. |
| [7] | Scott CA, Pierce SA, Pasqualetti MJ, et al. (2011) Policy and Institutional Dimensions of the Water-energy Nexus. Ener Pol 39: 6622-6630. |
| [8] | Lundie S, Peters GM, Beavis PC (2004) Life cycle assessment for sustainable metropolitan water systems planning. Environ Sci Technol 3465-73. |
| [9] | Loubet P, Roux P, Loiseau E, et al. (2014) Life cycle assessments of urban water systems: a comparative analysis of selected peer-reviewed literature. Water Res 67: 187-202. |
| [10] | Kenney DS, Wilkinson R, editors (2011) The water-energy nexus in the American west. Edward Elgar Publishing. |
| [11] | Hardy L, Garrido A, Juana L (2012) Evaluation of Spain's water-energy nexus. Int J Water Resour Dev 28: 151-70. |
| [12] | W. W. Griffiths-Sattenspiel B, 2009. |
| [13] | Stillwell AS, King CW, Webber ME, et al. (2011) The energy-water nexus in Texas. Ecol Soc 16. |
| [14] | Ringler C, Bhaduri A, Lawford R (2013) The nexus across water, energy, land and food (WELF): potential for improved resource use efficiency? Curr Opin Environ Sustain 617-624. |
| [15] | Wilkinson R K W (2006) An analysis of the energy intensity of water in California: providing a basis for quantification of energy savings from water system improvements. ACEEE Summer Study on Energy Efficiency in Buildings, ACEEE, Pacific Grove, CA, 123-33. |
| [16] | Kenway SJ, Priestley A, Cook S, et al. (2008) Energy use in the provision and consumption of urban water in Australia and New Zealand. Water for a Healthy Country Flagship: CSIRO. |
| [17] | King CW, Duncan IJ, Webber M (2008) Water Demand Projections for Power Generation in Texas. |
| [18] | Siddiqi A, Anadon LD. The Water-Energy Nexus In Middle East And North Africa. Ener Pol 39: 4529-4540. |
| [19] | Pan SY, Haddad AZ, Kumar A, et al. (2020) Brackish water desalination using reverse osmosis and capacitive. Water Res 183: 1-23. |
| [20] | Kumar A, Pan SY (2020) Opportunities and Challenges for Renewable Energy Integrated Water-Energy. Water-Energy Nexus. |
| [21] | Tsai SW, Hackl L, Kumar A, et al. (2021) Exploring the electrosorption selectivity of nitrate over chloride in capacitive deionization (CDI) and membrane capacitive deionization (MCDI). Desalination 497: 1-11. |
| [22] | Chiu YR, Liaw CH, Chen LC (2009) Optimizing Rainwater Harvesting Systems as an Innovative Approach to saving energy in Hilly Communities. Renew Energ 34: 492-498. |
| [23] | Retamal ML, Abeysuriya K, Turner AJ, et al. (2008) The Water energy Nexus: Literature Review. [Prepared For CSIRO]. Sydney: Institute For Sustainable Futures, University Of Technology "The Water energy Nexus: Literature Review". [Prepared For CSIRO]. Sydney: Institute For Sustainable Futures, University. |
| [24] | Copeland C, Carter NT (2017) Energy-Water Nexus: The Water Sector's Energy Use. Congressional Research Service. |
| [25] | Wakeel M, Chen B, Hayat T, et al. (2016) Energy consumption for water use cycles in different countries: a review. Appl Energy 178: 868-85. |
| [26] | CEC. (2005) Comparison of Alternate Cooling Technologies for California Power Plants: Economic, Environmental and Other Tradeoffs" California, USA: California Energy Commission. |
| [27] | Yoon H (2018) A Review on Water-Energy Nexus and Directions. Documents d'Anàlisi Geogràfica, 64: 365-395. |
| [28] | Goldstein R, Smith WE (2002) Water & Sustainability (Volume 4): US Electricity Consumption for Water Supply & Treatment - The Next Half Century". Palo Alto, California, USA. |
| [29] | Cohen R, Nelson B, Wolff G (2004) Energy Down the Drain-The Hidden Costs of California's Water Supply. Oakland, California: Natural Resources Defense Council, Pacific Institute. |
| [30] | Hernández-Sancho F, Molinos-Senante M, Sala-Garrido R (2011) Energy Efficiency in Spanish Wastewater Treatment Plants: A Non-Radial DEA Approach. Sci Total Environ 409: 2693-2699. |
| [31] | Lam KL, Kenway SJ, Lant PA (2017) Energy use for water provision in cities. J Clean Prod 143: 699-709. |
| [32] | Hancock NT, Black ND, Cath TY (2012) A Comparative Life Cycle Assessment of Hybrid Osmotic Dilution Desalination and Established Seawater Desalination and Wastewater Reclamation Processes. Water Res 46: 1145-1154. |
| [33] | Dai J, Wu S, Han G, Weinberg J, et al. (2018) Water-energy nexus: A review of methods and tools for macro-assessment. applied energy, 15: 393-408. |
| [34] | Spang ES, Loge FJ (2015) A high-resolution approach to mapping energy flows through water infrastructure systems. J Ind Ecol 19: 656-65. |
| [35] | Cohen R, Nelson B, Wolff G (2004) Energy down the drain: the hidden costs of California's water supply. Cousins, Emily, Natural Resources Defense Council, Oakland, . Researchgate, applied energy. |
| [36] | Kenwa y, S. P (2008) Energy Use in the Provision and Consumption of Urban Water in Australia and New Zealand. Water Services Association of Australia. Canberra: CSIRO. |
| [37] | Mo W, Wang R, Zimmerman JB (2014) Energy-water nexus analysis of enhanced water supply scenarios: a regional comparison of Tampa Bay Florida, and San Diego, California. Environ Sci Technol 48: 5883-91. |
| [38] | Lemos D, Dias AC, Gabarrell X, et al. (2013) Environmental assessment of an urban water system. J Clean Prod 54: 157-65. |
| [39] | MUDHCo (2015) National Report on Housing and Sustainable Urban Development. Federal Democratic Republic of Ethiopia. |
| [40] | EEA (2013) Urban waste water treatment. European Environment Agency, Denmark. |
| [41] | Racoviceanu AI, Karney BW, Kennedy CA, et al. (2007) Life-cyle energy use and greenhouse gas emissions inventory for water treatment systems. J Infrastruct Syst 13: 261-70. |
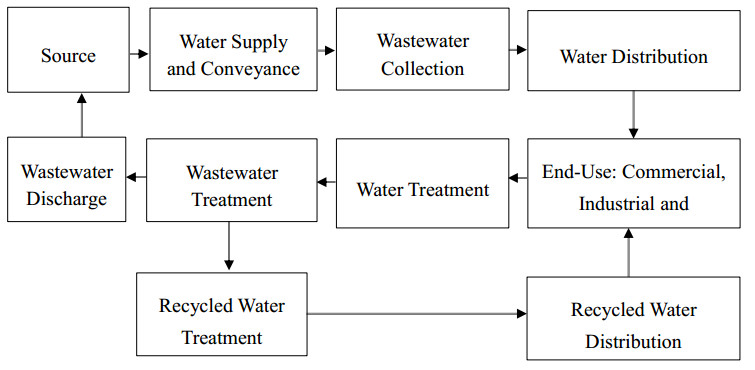
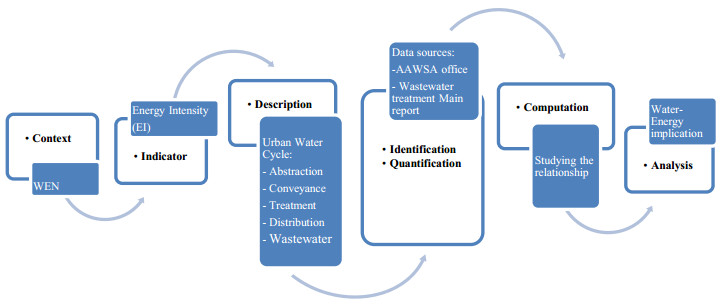

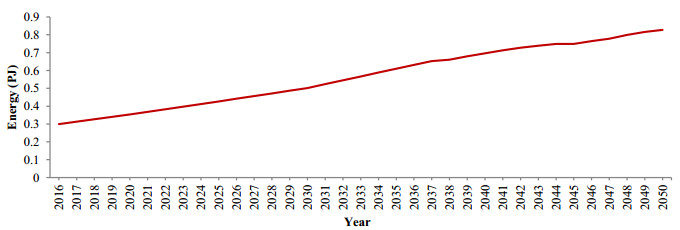
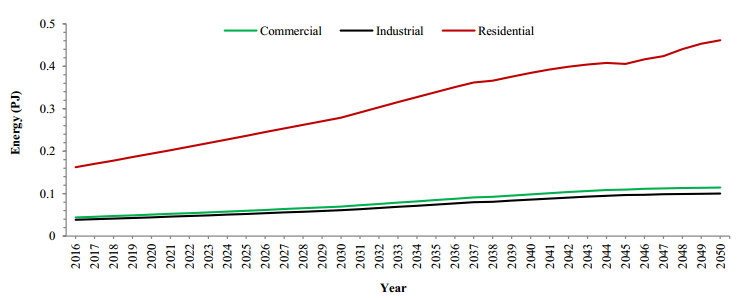
Figures(5) / Tables(5)

Bedassa D. Kitessa, Semu M. Ayalew, Geremew S. Gebrie, Solomon T. Teferi. Quantifying water-energy nexus for urban water systems: A case study of Addis Ababa city[J]. AIMS Environmental Science, 2020, 7(6): 486-504. doi: 10.3934/environsci.2020031







 DownLoad:
DownLoad: