In recent years, the fresh-cut products segment has shown a growing trend in Italy even in the current complex socio-economic phase determined largely by the Covid 19 pandemic. The paper proposes an evolutionary path with the analysis of data produced by statistical sources, effective for cognitive purposes. Data mainly refer to the large product group of "salads" that represent the prevailing market share of the fresh-cut products segment. The vitality emerged has suggested to focus on some of the quality aspects orientated both on the part of firms, in order to promote competitive capacity, and on the part of consumers because of the need to respond to requests for food safety. In relation to this aspect, the paper proposes theoretical consideration, relevant for practical and factual purposes, on whether food safety is really one of the factors closely linked to determining quality. This is to identify the role and the importance attributed respectively to quality, as regards the ability to satisfy expressed or implicit needs, and to food safety, as an absence of risks that could endanger human health. The resulting difference in role and function raised the question of whether food quality and safety should be considered universally combined in the reference food. Finally, the paper, in the general regulatory framework, inherent to the agro-food sector of the European Union and of the Italian legislative authorities, has sought to identify the provisions that directly and/or indirectly influence the improvement and innovation of fresh-cut products.
Citation: Carla Zarbà, Gaetano Chinnici, Biagio Pecorino, Gioacchino Pappalardo, Mario D'Amico. Recent scenarios in Italy on fresh-cut products in the Covid-19 context[J]. AIMS Agriculture and Food, 2022, 7(2): 403-425. doi: 10.3934/agrfood.2022026
In recent years, the fresh-cut products segment has shown a growing trend in Italy even in the current complex socio-economic phase determined largely by the Covid 19 pandemic. The paper proposes an evolutionary path with the analysis of data produced by statistical sources, effective for cognitive purposes. Data mainly refer to the large product group of "salads" that represent the prevailing market share of the fresh-cut products segment. The vitality emerged has suggested to focus on some of the quality aspects orientated both on the part of firms, in order to promote competitive capacity, and on the part of consumers because of the need to respond to requests for food safety. In relation to this aspect, the paper proposes theoretical consideration, relevant for practical and factual purposes, on whether food safety is really one of the factors closely linked to determining quality. This is to identify the role and the importance attributed respectively to quality, as regards the ability to satisfy expressed or implicit needs, and to food safety, as an absence of risks that could endanger human health. The resulting difference in role and function raised the question of whether food quality and safety should be considered universally combined in the reference food. Finally, the paper, in the general regulatory framework, inherent to the agro-food sector of the European Union and of the Italian legislative authorities, has sought to identify the provisions that directly and/or indirectly influence the improvement and innovation of fresh-cut products.

| [1] |
De Corato U (2020) Improving the shelf-life and quality of fresh and minimally-processed fruits and vegetables for a modern food industry: A comprehensive critical review from the traditional technologies into the most promising advancements. Crit Rev Food Sci Nutr 60: 940-975. https://doi.org/10.1080/10408398.2018.1553025 doi: 10.1080/10408398.2018.1553025

|
| [2] | González-Buesa J, Page N, Kaminski C, et al. (2014) Effect of non-conventional atmospheres and bio-based packaging on the quality and safety of listeria monocytogenes-inoculated fresh-cut celery (apium graveolens L.) during storage. Postharvest Biol Technol 93: 29-37. https://doi.org/10.1016/j.postharvbio.2014.02.005 |
| [3] |
Rico D, Martín-Diana AB, Barat JM, et al. (2007) Extending and measuring the quality of fresh-cut fruit and vegetables: A review. Trends Food Sci Technol 18: 373-386. https://doi.org/10.1016/j.tifs.2007.03.011 doi: 10.1016/j.tifs.2007.03.011
|
| [4] | De Luca AI, Iofrida N (2020) Sustainability certifications and life cycle approaches for quality evaluation in agro-food supply chains. In: Fabbio P, Sajia R (Eds.), Atti del Convegno AIDA "La qualità e le qualità dei prodotti alimentari tra regole e mercato". Collana Diritto Alimentare/Food Law Series, Wolters Kluwer, Cedam 219. |
| [5] | Prodotti-ortofrutticoli-di-iv-gamma cosa sono (2017) TuttoAlimenti effettua consulenza alle aziende del settore alimentare in tutta Italia. Scopri i nostri servizi. Available from: http://www.tuttoalimenti.com[Italian]. |
| [6] | Rapporto sulla competitività del settore ortofrutticolo nazionale (2015) Available from: http://www.unaproa.com[Italian]. |
| [7] | Malara M (2018) Anni '90|epoca di cambiamenti e rivoluzione digitale. Available from: https://www.exitrc.it[Italian]. |
| [8] |
Del Nobile M A, Conte A, Scrocco C, et al. (2009) New packaging strategies to preserve fresh-cut artichoke quality during refrigerated storage. Innovative Food Sci Emerging Technol 10: 128-133. https://doi.org/10.1016/j.ifset.2008.06.005 doi: 10.1016/j.ifset.2008.06.005
|
| [9] | Statistiche di Produzione e Mercato (2021) CSO Italy Centro Servizi Ortofrutticoli. Available from: https://www.csoservizi.com[Italian]. |
| [10] | Colelli G, Elia A (2009) I prodotti ortofrutticoli di IV gamma: aspetti fisiologici e tecnologici. Review n. 9-Italus Hortus: 55-78. Available from: https://www.soihs.it[Italian]. |
| [11] | Calano gli acquisti di ortaggi IV gamma nel (2014) ISMEA Mercati, Roma. |
| [12] | Nuove regole per la produzione, il confezionamento e la distribuzione dei prodotti di IV e V gamma (2021) Available from: https://www.agricolturafinanziamenti.com/nuove-regole-per-la-produzione-il-confezionamento-e-la-distribuzione-dei-prodotti-di-iv-e-v-gamma/ [Italian]. |
| [13] | IV gamma: è ora di "fare il tagliando" alla legge che compie 10 anni (2021) Available from: https://www.fruitbookmagazine.it[Italian]. |
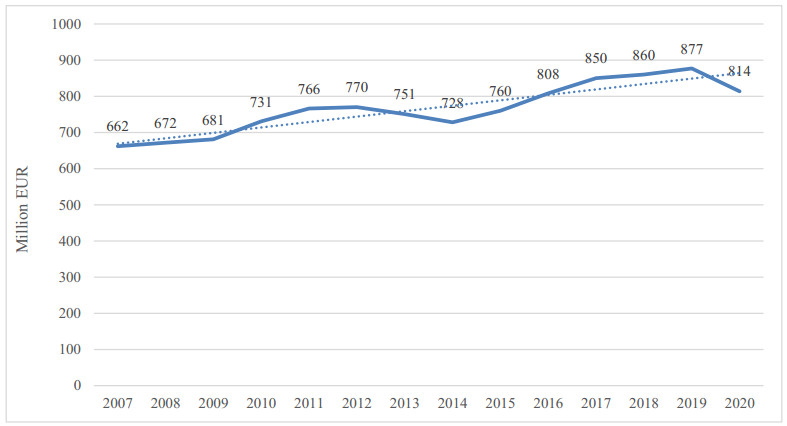
| [14] | IV gamma: il 2020 chiude con un valore complessivo di 814 mln di euro (2021) Available from: https://distribuzionemoderna.info[Italian]. |
| [15] | IV gamma, pressing sul Governo per una normativa chiara (2021) Ufficio stampa Unione Italiana Food. Available from: http://www.italiafruit.net[Italian]. |
| [16] | Rapporto Ortofrutta DEF (2015) Available from: http://www.unaproa.com/upload/news/[Italian]. |
| [17] | Produzione di Prodotti di Quarta Gamma (2017) Zipmec. Available from: https://www.zipmec.com[Italian]. |
| [18] | Baldi L, Casati D (2009) Un distretto della IV gamma? Il comparto che "vende tempo libero. Agriregionieuropa 5. Available from: https://agriregionieuropa.univpm.it/it/content/article/31/16/un-distretto-della-iv-gamma-il-comparto-che-vende-tempo-libero [Italian]. |
| [19] | Acquisti di IV gamma (2020) Available from: https://www.freshcutnews.it/2020/02/28[Italian]. |
| [20] | Reale LL (2019) La Piana del Sele, polo europeo degli ortaggi a foglia per la IV gamma. Available from: https://www.freshplaza.it/article/9110743/[Italian]. |
| [21] | Colelli G (2018) L'ortofrutta-di IV-gamma spinta dall'innovazione tecnologica. Rivista di frutticoltura e di ortofloricolturta 82: 42-43. https://rivistafrutticoltura.edagricole.it/featured/lortofrutta-di-iv-gamma-spinta-dallinnovazione-tecnologica/ [Italian] |
| [22] |
Pereira BR, Soares AG, Barboza HTG, er al. (2019) Impact of minimal processing on the quality of the sweet celebration grape cultivar. Curr Nutr Food Sci 15: 274-280. https://doi.org/10.2174/1573401313666170928145627 doi: 10.2174/1573401313666170928145627
|
| [23] |
Rodgers S (2016) Minimally processed functional foods: Technological and operational pathways. J Food Sci 81: R2309-R2319. https://doi.org/10.1111/1750-3841.13422 doi: 10.1111/1750-3841.13422
|
| [24] |
Zarbà C, Allegra V, Zarbà AS, et al. (2019) Wild leafy plants market survey in Sicily: From local culture to food sustainability. AIMS Agric Food 4: 534-546. https://doi.org/10.3934/agrfood.2019.3.534 doi: 10.3934/agrfood.2019.3.534
|
| [25] |
Thompson GD, Wilson PN (1999) Market demands for bagged, refrigerated salads. J Agric Resour Econ 24: 463-481. https://doi.org/10.22004/ag.econ.30801 doi: 10.22004/ag.econ.30801
|
| [26] | Nucera M (2019) Le vendite al dettaglio del segmento degli ortaggi IV gamma. I consumi domestici delle famiglie italiane Ismea. Available from: https://www.ismeamercati.it/flex/cm/pages/ServeAttachment.php/L/IT/D/1%252F6%252F1%252FD.ecadfe14d3b6a36c6980/P/BLOB%3AID%3D11412/E/pdf [Italian]. |
| [27] | Parmigiani P (2021) Le vendite al dettaglio degli ortaggi IV gamma. Available from: https://www.italiaatavola.net/images/contenutiarticoli/Report%20Ismea%20-%20Consumi%20IV%20gamma.pdf [Italian]. |
| [28] | Cavicchi A (2008) Qualità alimentare e percezione del consumatore. Agriregionieuropa 4, N. 15. Available from: https://agriregionieuropa.univpm.it/en/content/article/31/15/qualita-alimentare-e-percezione-del-consumatore [Italian]. |
| [29] |
Yousuf B, Qadri OS, Srivastava AK (2018) Recent developments in shelf-life extension of fresh-cut fruits and vegetables by application of different edible coatings: A review. LWT-Food Sci Technol 89: 198-209. https://doi.org/10.1016/j.lwt.2017.10.051 doi: 10.1016/j.lwt.2017.10.051
|
| [30] | Cavicchi A (2012) Indagare la percezione e la disponibilità a pagare per attributi di qualità alimentare: il contributo della ricerca partecipata "università-impresa" alla riduzione della marketing myopia. Available from: https://docenti.unimc.it/alessio.cavicchi. [Italian]. |
| [31] |
Rolfe J, Bretherton P, Hyland P, et al. (2006) Statistical techniques to facilitate the launch price of fresh fruit: Bringing science to the art of pricing. Br Food J 108: 200-212. https://doi.org/10.1108/00070700610651025 doi: 10.1108/00070700610651025
|
| [32] | Fabbio P, Saija R (2019) La qualità e le qualità dei prodotti alimentarti tra regole e mercato. CEDAM Scienze Giuridiche[Italian]. |
| [33] | Aprile MC, Annunziata A (2006) Informazione, etichettatura e comportamento del consumatore: un'analisi sull'uso delle etichette alimentari. Economia agro-alimentare. SIEA 2, 2: 111-129 FrancoAngeli[Italian]. |
| [34] | Pecorino B (2007) Le filiere agroalimentari in rapporto alle esigenze di rintracciabilità. Atti del XLIV Convegno di studi, Taormina. SIEA. 1820.198: 110-146 FrancoAngeli. http://hdl.handle.net/20.500.11769/96087 [Italian] |
| [35] | Peirce E (2010) Vegetali di quarta gamma-cenni. In: Osservatorio Regionale Sicurezza alimentare (O.R.S.A). Available from: http://www.orsacampania.it[Italian]. |
| [36] | Gaglio R, Craparo V, Francesca N, et al. (2017) Aspetti igienico-sanitari dei prodotti vegetali di IV gamma. La Rivista Di Scienza Dell'alimentazione 46: 23-34. Available from: https://iris.unipa.it/retrieve/handle/10447/249755/472035 [Italian]. |
| [37] | Stampacchia P, Colurcio M, Russo Spena T (2008) Preferenze, profili e tendenze del consumo dei prodotti di IV gamma. Atti International Congress: Marketing Trend. Venezia, 17-19 gennaio. Available from: http://archives.marketing-trends-congress.com/2008/Materiali/Paper/It/Stampacchia_Colurcio_RussoSpena.pdf [Italian]. |
| [38] | Cocchi M, Tassinari M (2007) Il concetto di qualità e sicurezza nutrizionale in una moderna ed avanzata visione del rapporto fra produzione agro alimentare e salute. Progress in nutrition 3, 9: 175-182[Italian]. |
| [39] |
Del Nobile MA, Conte A, Scrocco C, et al. (2009) New strategies for minimally processed cactus pear packaging. Innovative Food Sci Emerging Technol 10: 356-362. https://doi.org/10.1016/j.ifset.2008.12.006 doi: 10.1016/j.ifset.2008.12.006
|
| [40] |
Forney CF, Fan L, Doucette C, et al. (2018) Market life of diced red onion subjected to modified atmosphere packaging and antimicrobial dips. Acta Hortic 1209: 201-208. https://doi.org/10.17660/ActaHortic.2018.1209.29 doi: 10.17660/ActaHortic.2018.1209.29
|
| [41] |
Guzel M, Moreira RG, Omac B, et al. (2017) Quantifying the effectiveness of washing treatments on the microbial quality of fresh-cut romaine lettuce and cantaloupe. LWT 86: 270-276. https://doi.org/10.1016/j.lwt.2017.08.008 doi: 10.1016/j.lwt.2017.08.008
|
| [42] |
Li H, Ren Y, Hao J, et al. (2017) Dual effects of acidic electrolyzed water treatments on the microbial reduction and control of enzymatic browning for fresh-cut lotus root. J Food Saf 37: e12333. https://doi.org/10.1111/jfs.12333 doi: 10.1111/jfs.12333
|
| [43] |
Nguz K, Shindano J, Samapundo S, et al. (2005) Microbiological evaluation of fresh-cut organic vegetables produced in Zambia. Food Control 16: 623-628. https://doi.org/10.1016/j.foodcont.2004.07.001 doi: 10.1016/j.foodcont.2004.07.001
|
| [44] |
Qadri OS, Yousuf B, Srivastava AK (2015) Fresh-cut fruits and vegetables: Critical factors influencing microbiology and novel approaches to prevent microbial risks—A review. Cogent Food Agric 1: 112606. https://doi.org/10.1080/23311932.2015.1121606 doi: 10.1080/23311932.2015.1121606
|
| [45] |
Suslow TV, Oria MP, Beuchat LR, et al. (2003) Production practices as risk factors in microbial food safety of fresh and fresh-cut produce. Comprehensive Rev Food Sci Food Saf 2: 38-77. https://doi.org/10.1111/j.1541-4337.2003.tb00030.x doi: 10.1111/j.1541-4337.2003.tb00030.x
|
| [46] | Sticca S (2021) La Sicurezza alimentare. Le Policy Europee ed Internazionali. Periodico La linfa. Available from: https://www.lalinfa.it[Italian]. |
| [47] | Food and Agriculture Organization of United Nations (1996) Home|Food and Agriculture Organization of the United Nations (fao.org). Available from: https://www.fao.org. |
| [48] | European Union (2000) White Paper on Food Safety. Available from: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=LEGISSUM%3Al32041. |
| [49] |
Massaglia S, Merlino V M, Borra D, et al. (2019) Consumer attitudes and preference exploration towards fresh-cut salads using best-worst scaling and latent class analysis. Foods 8: 568. https://doi.org/10.3390/foods8110568 doi: 10.3390/foods8110568
|
| [50] |
Althaus D, Hofer E, Corti S, et al. (2012) Bacteriological survey of ready-to-eat lettuce, fresh-cut fruit, and sprouts collected from the swiss market. J Food Prot 75: 1338-1341. https://doi.org/10.4315/0362-028X.JFP-12-022 doi: 10.4315/0362-028X.JFP-12-022
|
| [51] | Riordan DCR, Sapers GM, Hankinson TR, et al. (2001) A study of U.S. orchards to identify potential sources of escherichia coli O157: H7. J Food Prot 6: 1320-1327. https://doi.org/10.4315/0362-028X-64.9.1320 |
| [52] |
Ansah FA, Amodio ML, De Chiara MLV, et al. (2018) Effects of equipments and processing conditions on quality of fresh-cut produce. J Agric Eng 49: 139-150. https://doi.org/10.4081/jae.2018.827 doi: 10.4081/jae.2018.827
|
| [53] | Catalano AE, Sapienza M, Peluso O, et al. (2008) Enzymes relating to the alteration of minimally processed vegetables. [Miglioramento qualitativo degli ortofrutticoli di IV gamma: Ruolo dei principali enzimi degradativi] Industrie Alimentari 47: 479-485. |
| [54] | European Commission (2019) Communication from the Commission to the European Parliament, the European Council, the Council, the European Economic and Social Committee and the Committee of the Regions the European Green Deal COM/2019/640 final. |
| [55] | European Commission (2020) Communication from the Commission to the European Parliament, the Council, the European Economic and Social Committee and the Committee of the Regions Commission Work Programme 2021 A Union of vitality in a world of fragility COM/2020/690 final. |
| [56] | European Commission (2021) Communication from the Commission to the European Parliament, the Council, the European Economic and Social Committee and the Committee of the Regions on an Action Plan for the development of organic production COM/2021/141 final/2. |
| [57] | Chinnici G, Di Grusa A, D'Amico M (2019) The consumption of fresh-cut vegetables: Features and purchasing behaviour. Qual-Access Success 20: 178-185. |
| [58] |
Du X, Chen H, Zhang Z, et al. (2021) Headspace analysis of shelf life of postharvest arugula leaves using a SERS-active fiber. Post Biol Technol 175: 111410. https://doi:10.1016/j.postharvbio.2020.111410 doi: 10.1016/j.postharvbio.2020.111410
|
| [59] |
Allegra V, Zarbà C, La Via G, et al. (2019) Why the new orange juice consumption model favors global trade and growth in orange production. Br Food J 121: 1954-1968. https://doi.org/10.1108/BFJ-05-2019-0316 doi: 10.1108/BFJ-05-2019-0316
|
| [60] |
Zarbà C, Chinnici G, Hamam M, et al. (2022) Driving management of novel foods: A network analysis approach. Front Sustain Food Syst 5: 799587. https://doi.org/10.3389/fsufs.2021.799587 doi: 10.3389/fsufs.2021.799587
|
| [61] | Allegra V, Zarbà AS, Zarbà C (2019) Recent overview of the agri-food commercial economy of Italy with the rest of the world. Connections with the national economic system. Qual-Access Success 20: 13-20. |
| [62] | Zarbà C, Chinnici G, Pecorino B, et al. (2019) Paradigm of the circular economy in agriculture: The case of vegetable seedlings for transplantation in nursery farms. International Multidisciplinary Scientific GeoConference: SGEM Volume 19: 113-120. https://doi.org/10.5593/sgem2019V/4.2/S05.016 |
Figures(11) / Tables(1)

Carla Zarbà, Gaetano Chinnici, Biagio Pecorino, Gioacchino Pappalardo, Mario D'Amico. Recent scenarios in Italy on fresh-cut products in the Covid-19 context[J]. AIMS Agriculture and Food, 2022, 7(2): 403-425. doi: 10.3934/agrfood.2022026







 DownLoad:
DownLoad: